一、VGG 和 ResNet
当你在机器学习领域时,理论和实践是同等需要的。但是因为硬件限制会严重影响你的机器学习进程。值得庆幸的是,在互联网上上传预先训练的模型权重来帮助我们绕过这些问题。这些模型在庞大的数据集上进行训练,使其成为非常强大的特征提取器。
所以不仅可以将这些模型用于您的任务,还可以用作基准。但是在特定数据集上训练的模型是否适用于您的问题所特有的任务?这是一个需要考虑的问题。例如,假设您有一个在 ImageNet 上训练的模型(1400 万张图像和20000个分类)。在这种情况下,针对相似且更具体的图像分类对其进行微调将得到好的结果,因为预训练的模型已经是一个熟练的特征提取器。
借助网络上提供的大量预训练模型权重,Torch Hub 将整个过程浓缩为一行代码来解决这些问题。因此,您不仅可以在本地系统中加载 SOTA 模型(state-of-the-art,最好或者最先进的模型),还可以选择是否要对其进行预训练。
二、VGG 和 ResNet 架构回顾
VGG16架构是在论文“ Very Deep Convolutional Networks for Large-Scale Image Recognition ”中介绍的。它借鉴了 AlexNet 的核心思想,同时将大型卷积滤波器替换为多个3×3卷积滤波器。在下图中,我们可以看到完整的架构。
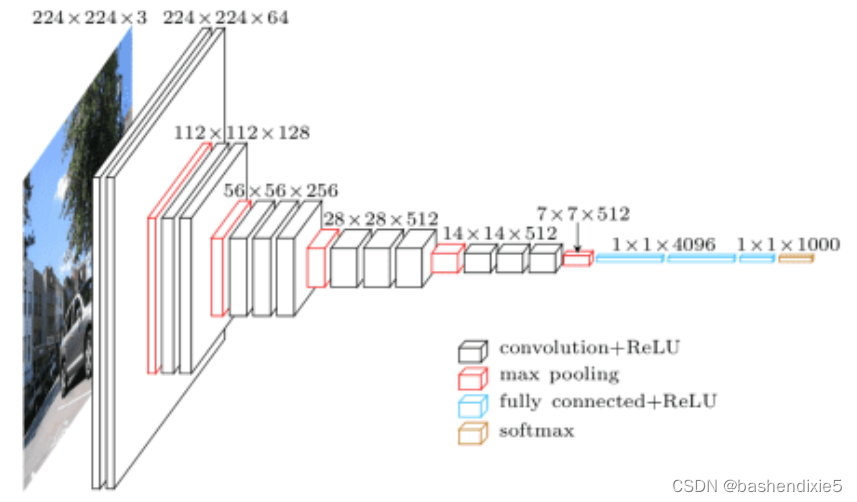
大量卷积滤波器的小滤波器尺寸和网络的深度架构优于当时的许多基准模型。
不过VGG16 有一些重大缺陷。首先,由于网络的性质,它有几个权重参数。这不仅使模型更重,而且增加了这些模型的推理时间。
了解了 VGG 网络带来的局限性,我们继续讨论它们的继承者;ResNet 。由 Kaiming He 和 Jian Sun 介绍,ResNets 理念背后不仅在许多情况下优于 VGG 网络,而且它们的架构还实现了更快的推理时间。
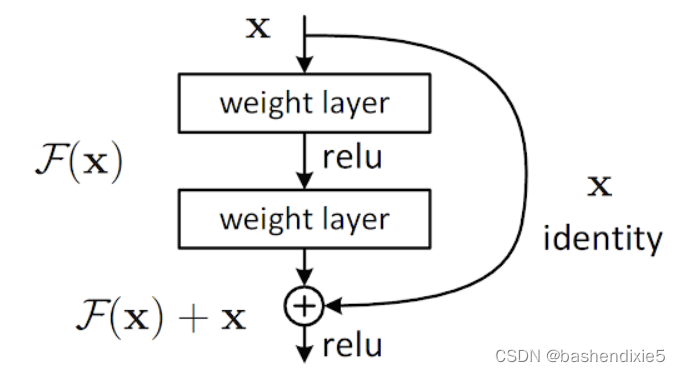
ResNets 背后的主要思想被称为“残差块”。正如你所看到的,一层的输出不仅会被馈送到下一层,还会跳一次并被馈送到架构中的另一层。
三、猫狗大战数据集
使用来自 Kaggle的简单二元分类Dogs & Cats数据集。这个 217.78 MB 的数据集包含 10,000 张猫和狗的图像,以 80-20 的训练与测试比率进行拆分。训练集包含 4000 张猫和 4000 张狗的图像,而测试集分别包含 1000 张猫和 1000 张狗的图像。
使用较小的数据集有两个原因:
(1)微调我们的分类器将花费更少的时间
(2)展示预训练模型适应数据较少的新数据集的速度
四、代码参考
1、创建配置文件
我们创建一个名为config.py的文件。
import torch
import os
# 定义数据目录,训练和测试路径
BASE_PATH = "dataset"
TRAIN_PATH = os.path.join(BASE_PATH, "training_set")
TEST_PATH = os.path.join(BASE_PATH, "test_set")
# 指定 ImageNet 均值和标准差
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
# 指定训练超参数
IMAGE_SIZE = 256
BATCH_SIZE = 128
PRED_BATCH_SIZE = 4
EPOCHS = 15
LR = 0.0001
# 确定设备类型
DEVICE = torch.device("cuda") if torch.cuda.is_available() else "cpu"
# 定义存储训练图和训练模型的路径
PLOT_PATH = os.path.join("output", "model_training.png")
MODEL_PATH = os.path.join("output", "model.pth")2、创建工具函数
创建一个名为datautils.py。
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader
from torch.datasets import Subset
def get_dataloader(dataset, batchSize, shuffle=True):
# create a dataloader
dl = DataLoader(dataset, batch_size=batchSize, shuffle=shuffle)
# return the data loader
return dl
def train_val_split(dataset, valSplit=0.2):
# grab the total size of the dataset
totalSize = len(dataset)
# perform training and validation split
(trainIdx, valIdx) = train_test_split(list(range(totalSize)),
test_size=valSplit)
trainDataset = Subset(dataset, trainIdx)
valDataset = Subset(dataset, valIdx)
# return training and validation dataset
return (trainDataset, valDataset)3、创建分类器
创建一个名为classifier.py的文件。请注意对于VGGnet,我们如何使用命令baseModel.classifier[6].out_features而对于 ResNet,我们使用baseModel.fc.out_features. 这是因为这些模型具有不同的命名模块和层。所以我们必须使用不同的命令来访问每个层的最后一层。因此,模型变量的代码非常重要。
from torch.nn import Linear
from torch.nn import Module
class Classifier(Module):
def __init__(self, baseModel, numClasses, model):
super().__init__()
# 初始化基本模型
self.baseModel = baseModel
# 检查基础模型是否为 VGG,如果是,则相应地初始化 FC 层
if model == "vgg":
self.fc = Linear(baseModel.classifier[6].out_features, numClasses)
# 否则,基础模型是 ResNet 类型,因此相应地初始化 FC 层
else:
self.fc = Linear(baseModel.fc.out_features, numClasses)
def forward(self, x):
# 通过基本模型传递输入以获取特征,然后通过全连接层传递特征以获取我们的输出 logits
features = self.baseModel(x)
logits = self.fc(features)
# 返回分类器输出
return logits4、进行训练
创建一个名为train.py的文件。
1、如果运行时需要的文件下载不下来相应,可以科学上网或者想办法下载到然后从本地加载。
2、如果运行时报类似错误ModuleNotFoundError: No module named ‘torchvision.models.mobilenetv2‘,请在对应环境下执行以下命令更新torchvision
pip install --upgrade torch torchvision
# 运行命令
# python train.py --model vgg
# python train.py --model resnet
import config
from classifier import Classifier
from datautils import get_dataloader
from datautils import train_val_split
from torchvision.datasets import ImageFolder
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torchvision.transforms import RandomResizedCrop
from torchvision.transforms import RandomHorizontalFlip
from torchvision.transforms import RandomRotation
from torchvision.transforms import Normalize
from torch.nn import CrossEntropyLoss
from torch.nn import Softmax
from torch import optim
from tqdm import tqdm
import matplotlib.pyplot as plt
import argparse
import torch
# 构造参数解析器并解析参数
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="vgg", choices=["vgg", "resnet"], help="name of the backbone model")
args = vars(ap.parse_args())
# 检查主干模型的名称是否为 VGG
if args["model"] == "vgg":
# load VGG-11 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "vgg11", pretrained=True, skip_validation=True)
# 冻结 VGG-11 模型的层
for param in baseModel.features.parameters():
param.requires_grad = False
# 否则,我们将使用的主干模型是 ResNet
elif args["model"] == "resnet":
# load ResNet 18 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "resnet18", pretrained=True, skip_validation=True)
# 定义模型的最后一层和当前层
lastLayer = 8
currentLayer = 1
# 循环遍历模型的子层
for child in baseModel.children():
# 检查我们是否还没有到达最后一层
if currentLayer < lastLayer:
# 循环子层的参数并冻结它们
for param in child.parameters():
param.requires_grad = False
# 否则,我们已经到达最后一层,所以打破循环
else:
break
# 增加当前层
currentLayer += 1
# 定义转换管道
trainTransform = Compose([
RandomResizedCrop(config.IMAGE_SIZE),
RandomHorizontalFlip(),
RandomRotation(90),
ToTensor(),
Normalize(mean=config.MEAN, std=config.STD)
])
# 使用 ImageFolder 创建训练数据集
trainDataset = ImageFolder(config.TRAIN_PATH, trainTransform)
# 创建训练和验证数据拆分
(trainDataset, valDataset) = train_val_split(dataset=trainDataset)
# 创建训练和验证数据加载器
trainLoader = get_dataloader(trainDataset, config.BATCH_SIZE)
valLoader = get_dataloader(valDataset, config.BATCH_SIZE)
# 构建自定义模型
model = Classifier(baseModel=baseModel.to(config.DEVICE), numClasses=2, model=args["model"])
model = model.to(config.DEVICE)
# 初始化损失函数和优化器
lossFunc = CrossEntropyLoss()
lossFunc.to(config.DEVICE)
optimizer = optim.Adam(model.parameters(), lr=config.LR)
# 初始化 softmax 激活层
softmax = Softmax()
# 计算训练和验证集的每轮步数
trainSteps = len(trainDataset) // config.BATCH_SIZE
valSteps = len(valDataset) // config.BATCH_SIZE
# 初始化一个字典来存储训练历史
H = {
"trainLoss": [],
"trainAcc": [],
"valLoss": [],
"valAcc": []
}
# 循环遍历
print("[INFO] training the network...")
for epoch in range(config.EPOCHS):
# 将模型设置为训练模式
model.train()
# 初始化总训练和验证损失
totalTrainLoss = 0
totalValLoss = 0
# 初始化训练和验证步骤中正确预测的数量
trainCorrect = 0
valCorrect = 0
# 循环训练集
for (image, target) in tqdm(trainLoader):
# send the input to the device
(image, target) = (image.to(config.DEVICE), target.to(config.DEVICE))
# 执行前向传递并计算训练损失
logits = model(image)
loss = lossFunc(logits, target)
# 将梯度归零,执行反向传播步骤,并更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 将损失添加到到目前为止的总训练损失中,将输出 logits 通过 softmax 层得到输出预测,并计算正确预测的数量
totalTrainLoss += loss.item()
pred = softmax(logits)
trainCorrect += (pred.argmax(dim=-1) == target).sum().item()
# 关闭自动
with torch.no_grad():
# 将模型设置为评估模式
model.eval()
# 循环验证集
for (image, target) in tqdm(valLoader):
# 将输入发送到设备
(image, target) = (image.to(config.DEVICE), target.to(config.DEVICE))
# 做出预测并计算验证损失
logits = model(image)
valLoss = lossFunc(logits, target)
totalValLoss += valLoss.item()
# 将输出logits通过softmax层得到输出预测,并计算正确预测的数量
pred = softmax(logits)
valCorrect += (pred.argmax(dim=-1) == target).sum().item()
# 计算平均训练和验证损失
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# 计算训练和验证准确度
trainCorrect = trainCorrect / len(trainDataset)
valCorrect = valCorrect / len(valDataset)
# 更新我们的培训历史
H["trainLoss"].append(avgTrainLoss)
H["valLoss"].append(avgValLoss)
H["trainAcc"].append(trainCorrect)
H["valAcc"].append(valCorrect)
# 打印模型训练和验证信息
print(f"[INFO] EPOCH: {epoch + 1}/{config.EPOCHS}")
print(f"Train loss: {avgTrainLoss:.6f}, Train accuracy: {trainCorrect:.4f}")
print(f"Val loss: {avgValLoss:.6f}, Val accuracy: {valCorrect:.4f}")
# 绘制训练损失和准确率
plt.style.use("ggplot")
plt.figure()
plt.plot(H["trainLoss"], label="train_loss")
plt.plot(H["valLoss"], label="val_loss")
plt.plot(H["trainAcc"], label="train_acc")
plt.plot(H["valAcc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.PLOT_PATH)
# 将模型状态序列化到磁盘
torch.save(model.module.state_dict(), config.MODEL_PATH)训练2个epoch的log如下,可以看到第一个epoch的准确率就很高。
Using cache found in C:\Users\xiaomao/.cache\torch\hub\pytorch_vision_v0.10.0
[INFO] training the network...
0%| | 0/800 [00:00<?, ?it/s]D:/Project/ml_toolset/vggandresnet/train.py:121: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
pred = softmax(logits)
100%|██████████| 800/800 [01:31<00:00, 8.72it/s]
0%| | 0/200 [00:00<?, ?it/s]D:/Project/ml_toolset/vggandresnet/train.py:139: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
pred = softmax(logits)
100%|██████████| 200/200 [00:12<00:00, 16.57it/s]
[INFO] EPOCH: 1/2
Train loss: 0.389997, Train accuracy: 0.8286
Val loss: 0.266122, Val accuracy: 0.8769
100%|██████████| 800/800 [01:32<00:00, 8.62it/s]
100%|██████████| 200/200 [00:12<00:00, 16.00it/s]
[INFO] EPOCH: 2/2
Train loss: 0.294812, Train accuracy: 0.8684
Val loss: 0.243279, Val accuracy: 0.8775
5、测试模型
# USAGE
# python inference.py --model vgg
# python inference.py --model resnet
import config
from classifier import Classifier
from datautils import get_dataloader
from torchvision.datasets import ImageFolder
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torchvision.transforms import Resize
from torchvision.transforms import Normalize
from torchvision import transforms
from torch.nn import Softmax
from torch import nn
import matplotlib.pyplot as plt
import argparse
import torch
from tqdm import tqdm
# 构造参数解析器并解析参数
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="vgg", choices=["vgg", "resnet"], help="name of the backbone model")
args = vars(ap.parse_args())
# 初始化测试转换管道
testTransform = Compose([
Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
ToTensor(),
Normalize(mean=config.MEAN, std=config.STD)
])
# 计算逆均值和标准差
invMean = [-m/s for (m, s) in zip(config.MEAN, config.STD)]
invStd = [1/s for s in config.STD]
# 定义我们的非规范化变换
deNormalize = transforms.Normalize(mean=invMean, std=invStd)
# 创建测试数据集
testDataset = ImageFolder(config.TEST_PATH, testTransform)
# 初始化测试数据加载器
testLoader = get_dataloader(testDataset, config.PRED_BATCH_SIZE)
# 检查主干模型的名称是否为 VGG
if args["model"] == "vgg":
# load VGG-11 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "vgg11", pretrained=True, skip_validation=True)
# 否则,我们将使用的主干模型是 ResNet
elif args["model"] == "resnet":
# load ResNet 18 model
baseModel = torch.hub.load("pytorch/vision:v0.10.0", "resnet18", pretrained=True, skip_validation=True)
# 构建自定义模型
model = Classifier(baseModel=baseModel.to(config.DEVICE), numClasses=2, model=args["model"])
model = model.to(config.DEVICE)
# 加载模型状态并初始化损失函数
model.load_state_dict(torch.load(config.MODEL_PATH))
lossFunc = nn.CrossEntropyLoss()
lossFunc.to(config.DEVICE)
# 初始化测试数据丢失
testCorrect = 0
totalTestLoss = 0
soft = Softmax()
# 关闭自动毕业
with torch.no_grad():
# 将模型设置为评估模式
model.eval()
# 循环验证集
for (image, target) in tqdm(testLoader):
# 将输入发送到设备
(image, target) = (image.to(config.DEVICE), target.to(config.DEVICE))
# 做出预测并计算验证损失
logit = model(image)
loss = lossFunc(logit, target)
totalTestLoss += loss.item()
# 通过softmax层输出logits得到输出预测,并计算正确预测的个数
pred = soft(logit)
testCorrect += (pred.argmax(dim=-1) == target).sum().item()
# 打印测试数据准确性
print(testCorrect/len(testDataset))
# 初始化可迭代变量
sweeper = iter(testLoader)
# 抓取一批测试数据
batch = next(sweeper)
(images, labels) = (batch[0], batch[1])
# 初始化一个图形
fig = plt.figure("Results", figsize=(10, 10 ))
# 关闭自动毕业
with torch.no_grad():
# 将图像发送到设备
images = images.to(config.DEVICE)
# 做出预测
preds = model(images)
# 循环所有批次
for i in range(0, config.PRED_BATCH_SIZE):
# 初始化子图
ax = plt.subplot(config.PRED_BATCH_SIZE, 1, i + 1)
# 抓取图像,对其进行去规范化,将原始像素强度缩放到 [0, 255] 范围内,并从通道前 tp 通道最后更改通道顺序
image = images[i]
image = deNormalize(image).cpu().numpy()
image = (image * 255).astype("uint8")
image = image.transpose((1, 2, 0))
# 获取真实标签
idx = labels[i].cpu().numpy()
gtLabel = testDataset.classes[idx]
# 获取预测标签
pred = preds[i].argmax().cpu().numpy()
predLabel = testDataset.classes[pred]
# 将结果和图像添加到绘图中
info = "Ground Truth: {}, Predicted: {}".format(gtLabel, predLabel)
plt.imshow(image)
plt.title(info)
plt.axis("off")
# 显示图标
plt.tight_layout()
plt.show()运行log如下,准确率达到0.9765。
Using cache found in C:\Users\xiaomao/.cache\torch\hub\pytorch_vision_v0.10.0
0%| | 0/250 [00:00<?, ?it/s]D:/Project/ml_toolset/vggandresnet/inference.py:74: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
pred = soft(logit)
100%|██████████| 250/250 [00:16<00:00, 15.48it/s]
0.9765 

五、小结
今天的教程不仅展示了如何利用 Torch Hub的模型库,而且还表明预先训练的模型在我们的日常机器学习中对我们帮助有多大。
想象一下,如果您必须从头开始为您选择的任何任务训练像 ResNet 这样的规模的架构。这将需要更多的时间,而且肯定需要更多的epoch。至此,您肯定会欣喜的接受PyTorch Hub背后的想法,以使用这些最先进模型的整个过程更加高效。