我的环境是vmware12 + rhel7 + hadoop2.4 + jdk7
linux环境配置
1.配置网络ip地址和主机名,这里我配置的ip地址是192.168.137.102,主机名为rhel7-02
2.安装jdk并配置jdk环境变量
3.关闭防火墙,rhel7关闭防火墙的方法如下:
systemctl status firewalld //查看防火墙状态
systemctl stop firewalld //停止防火墙 ,暂时
systemctl disable firewalld //禁用防火墙,永久配置好hadoop的环境之后,我们开始安装hadoop2.4
1.创建hadoop的解压目录,这是为了管理方便
mkdir /home/cloud/hadoop/2.解压hadoop压缩包到该路径下
tar -zxvf hadoop-2.4.1.tar.gz -C /home/cloud/hadoop/3.开始配置hadoop,我们先进去hadoop的配置文件目录
cd /home/cloud/hadoop/hadoop-2.4.1/etc/hadoop/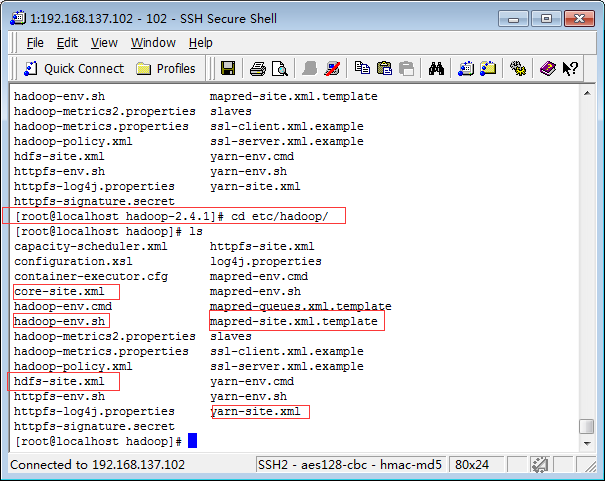
我们需要配置红色框的5个配置文件
a.修改hadoop-env.sh,配置hadoop的环境变量
vi hadoop-env.sh
#找到JAVA_HOME改成实际的javahome路径
export JAVA_HOME=/usr/java/jdk1.7.0_65b.修改core-site.xml,配置hdfs的默认地址以及运行时产生文件的存储目录
vi core-site.xml
<!-- 指定NameNode地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs:rhel7-02//:9000</value>
</property>
<!-- 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/cloud/hadoop/hadoop-2.4.1/tmp</value>
</property>c.修改hdfs-site.xml,配置hdfs副本
vi hdfs-site.xml
<!-- 副本复制数量,这里配置为1,是因为目前我们只在一台机器测试,还没做集群 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>d.修改mapred-site.xml,配置mr运行环境
#hadoop只提供了模版,所以我们需要修改下名称
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<!--指定运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>e.修改yarn-site.xml,配置yarn地址
vi yarn-site.xml
<!-- 指定YARN地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>rhel7-02</value>
</property>
<!-- 指定reducer数据获取方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>到此配置文件都配置完成了,接下来还要需要俩部就成功了
f.添加hadoop到系统环境变量
export JAVA_HOME=/usr/java/jdk1.7.0
export HADOOP_HOME=/home/cloud/hadoop/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbing.让配置生效,可以用命令行hdfs测试下命令是否生效,生效则配置成功
source /etc/profileh.格式化hdfs文件系统
hdfs namenode -formati.启动我们的hadoop,见证奇迹的时候了
sbin/start-dfs.sh #启动文件系统hdfs
sbin/start-yarn.sh #启动yarn4.开始验证我们的hadoop,首先使用使用jps命令验证一下
[root@rhel7-02 hadoop]# jps
2320 DataNode
2447 SecondaryNameNode
3296 Jps
2745 NodeManager
2649 ResourceManager
2224 NameNode 到这里说明说明相关的进程已经启动完成,具体每个进程的作用,下次详细讲解。
接下来,我们就可以在web浏览器输入相关的地址,查看hadoop的相关状态
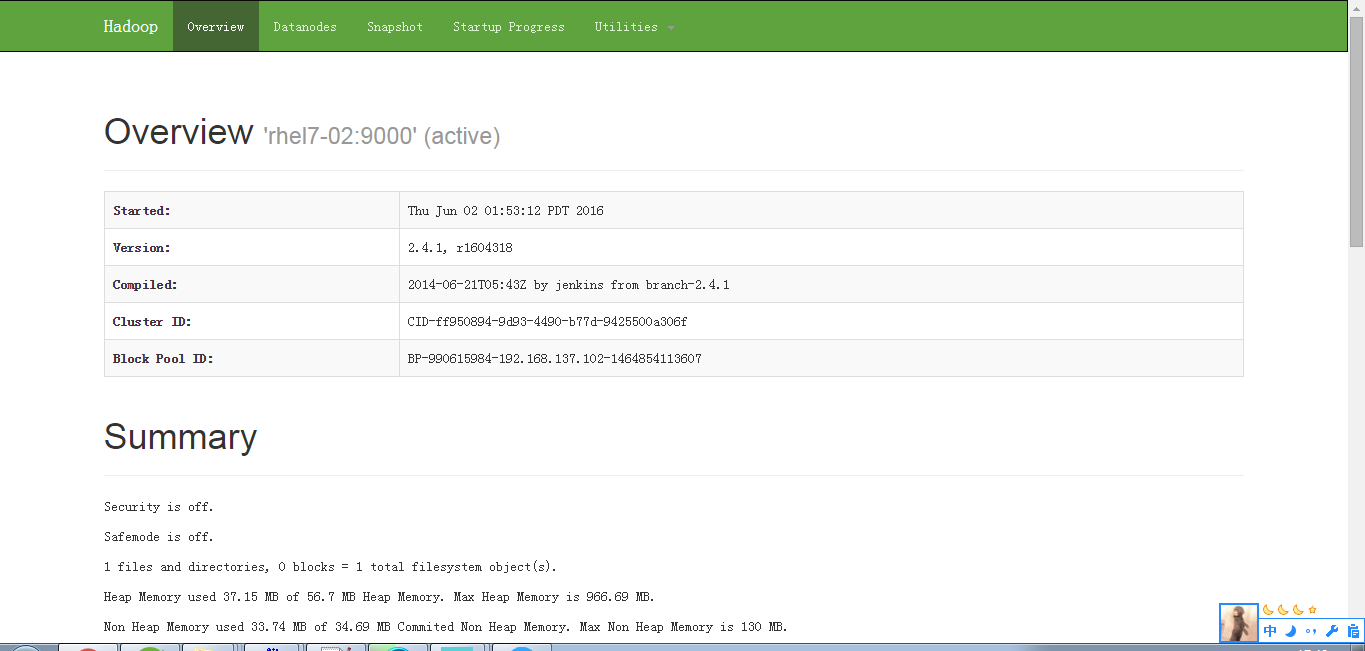
http://192.168.137.102:50070/ #hdfs浏览界面
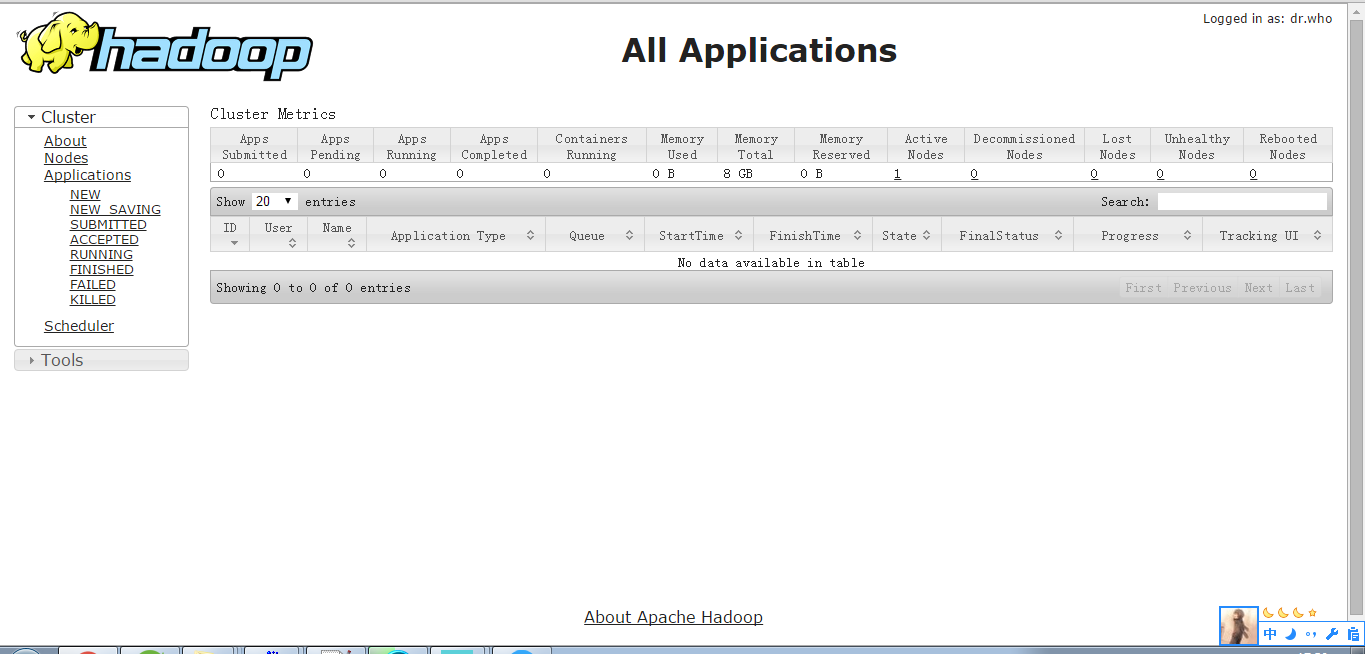
http://192.168.137.102:8088 #yarn集群浏览界面
我们再来试着上传和下载一个文件到hadoop文件系统中看看
hadoop fs -put /home/cloud/package/color.exe hdfs://rhel7-02:9000/上传完成之后,可以在浏览器看到上传文件
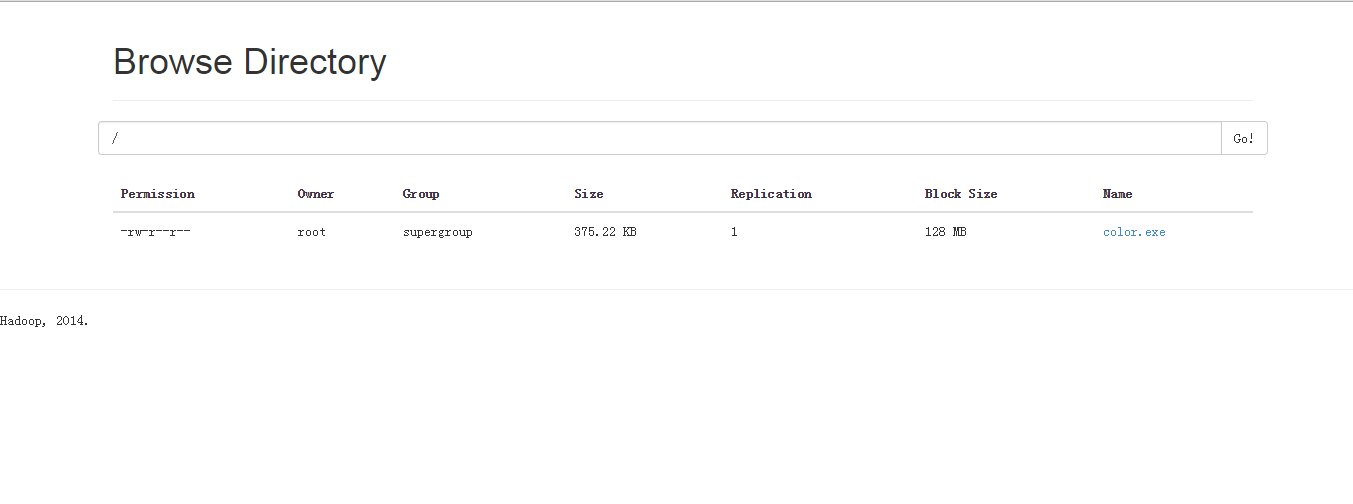
点击可下载,若发现浏览器域名无法解析,需要在本地window上配置域名解析和ip的关联,编辑添加C:\Windows\System32\drivers\etc\hosts
192.168.137.102 rhel7-02接下来我们来下载一个文件,通过命令行
hadoop fs -get hdfs://rhel7-02:9000/color.exe /home/cloud/package/color2.exe在/home/cloud/package/路径下发现color2.exe,说明下载也成功,到此,hadoop安装和配置完成。具体详细概念和用法下次再看看