文章目录
hadoop的安装
本次安装是建立在之前安装完jdk以及mysql的基础上,如果其他朋友们想了解的可以查看下之前的安装步骤,这里是传送门
本次安装使用MobaXterm 辅助工具,先把对应的hadoop压缩包上传到 root/software文件夹内备用
1、解压hadoop免安装压缩包
进入root/software文件夹内后,输入解压命令
tar -zxvf hadoop-2.6.0-cdh5.14.2.tar.gz
执行如下:
2、修改文件夹名称
为了后面方便,先把hadoop的文件名修改的短一点,这一步不重要,个人习惯问题,可以忽略不做。
mv hadoop-2.6.0-cdh5.14.2.tar.gz hadoop

3、删除压缩包文件
解压缩后,原文件就没有用了,建议直接删除
rm -f hadoop-2.6.0-cdh5.14.2.tar.gz
4、准备配置环境
进入刚刚修改名称的hadoop文件夹内,然后在etc目录下还有一个hadoop,进入后准备配置环境
cd hadoop/etc/hadoop
配置环境
1、配置hadoop-env.sh 文件关联java
进入hadoop-env.sh 文件内后进入编辑模式,将原路径注释后,新增JAVA_HOME的实际路径,
vi hadoop-env.sh
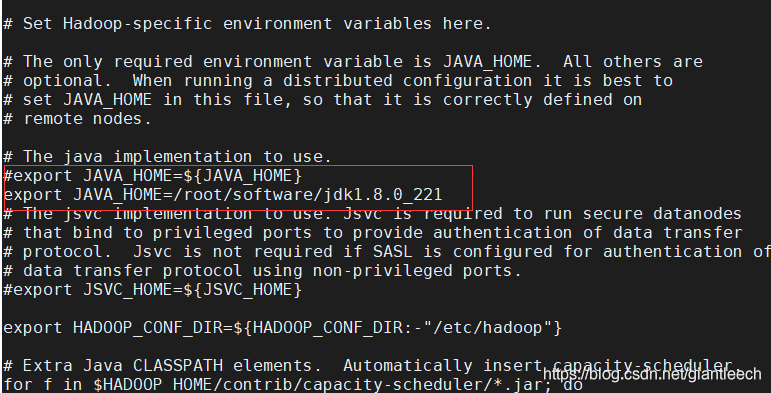
因为某些原因,原JAVA_HOME无法使用,需要注释掉后,手动增加一个新的路径:
export JAVA_HOME=/root/software/jdk1.8.0_221
如果记不清楚JAVA_HOME的路径,可以退出后,输入:
echo $JAVA_HOME
查看JAVA_HOME的实际路径
2、配置core-site.xml文件,配置核心
进入core-site.xml文件
vi core-site.xml
在最后面里面输入后保存退出:
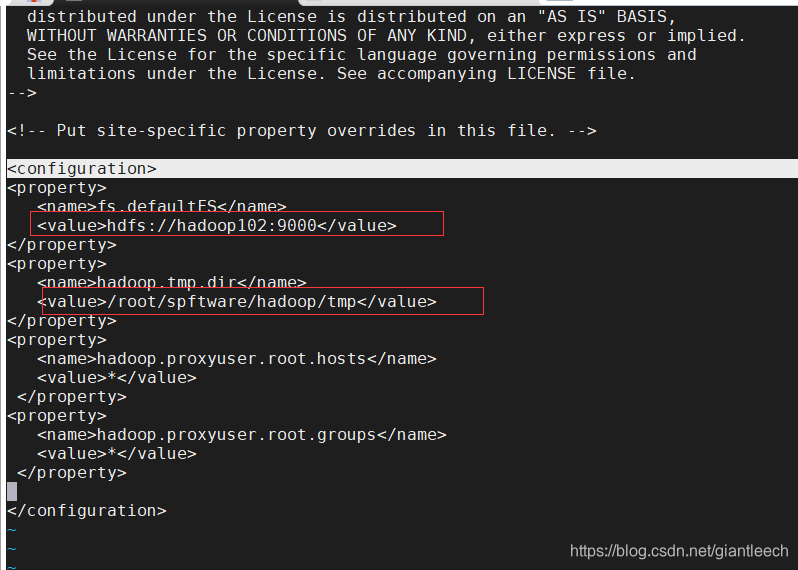
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/software/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
红框标注的地方,hadoop为本来虚拟机的hostname,第二个value 里面是实际的安装地址内新建一个tmp文件夹, 后面两个直接复制粘贴就好
3、配置hdfs-site.xml 配置类型
进入hdfs-site.xml 文件
vi hdfs-site.xml
因为这里是用多个虚拟机模拟分布式结构,也就是伪分布式,所以这个设置节点为1
后期需要的情况下再添加全分布式以及其他
同样在最后面里面输入后保存退出:
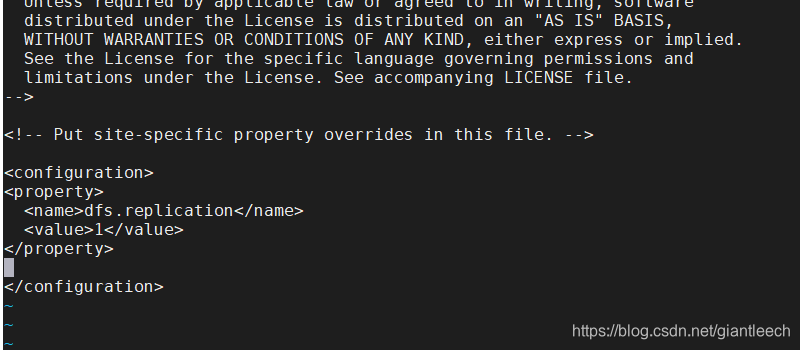
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4、配置mapred-site.xml.template文件
进入mapred-site.xml.template文件
vi mapred-site.xml.template
同样在最后面里面输入后保存退出:
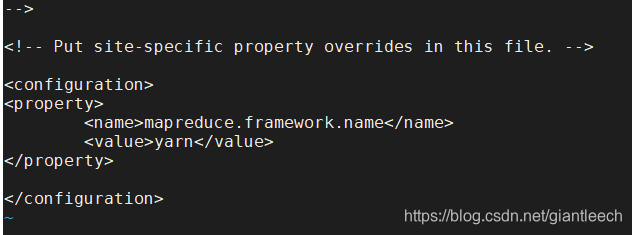
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5、配置vi yarn-site.xml 文件
进入yarn-site.xml文件
vi yarn-site.xml
同样在最后面里面输入后保存退出:
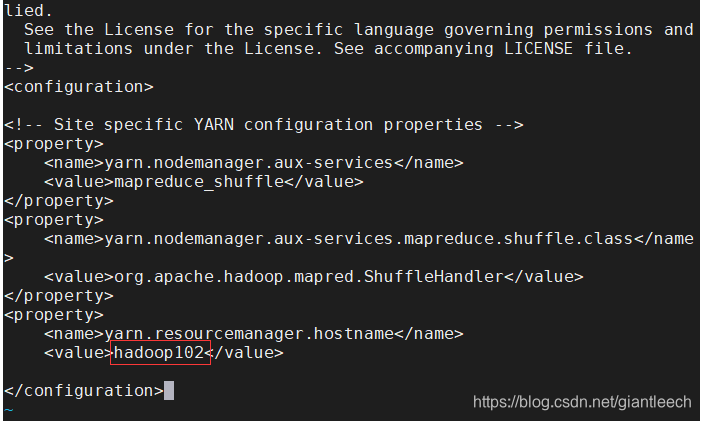
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
标红的位置填写本机的hostname
6、配置hadoop环境变量
进入 etc/profile 目录下的文件内
vi /etc/profile
在最后的位置新增
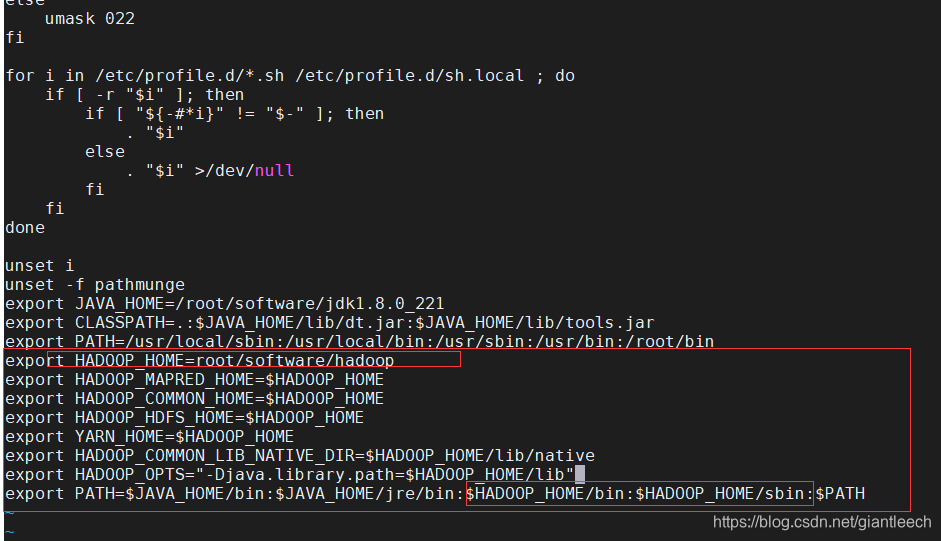
export HADOOP_HOME=/root/software/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
其中,第一行为hadoop的安装目录,根据自己实际情况填写,最后一行是在原有基础上增加 H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:HADOOP_HOME/sbin的路径,然后保存退出:
7、让环境变量生效
输入命令让新配置的环境变量生效
source /etc/profile
8、进行初始化
输入命令:
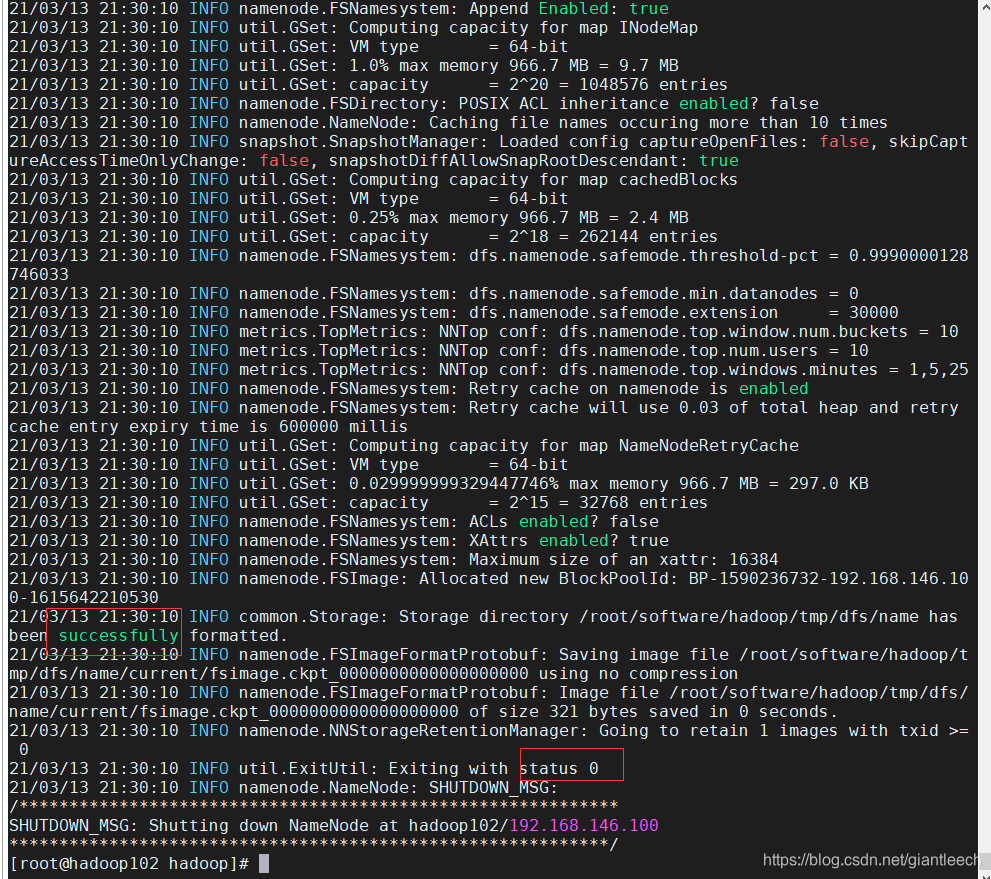
hadoop namenode -format
看到successfully 和status 0 则表示初始化成功,之前的配置没有问题
9、启动服务
先输入
cd ../..
退回hadoop主路径
然后输入
start-all.sh
来启动服务,start-all.sh 相当于start-dfs.sh 加上start-yarn.sh
输入两次yes后启动完成,可以输入jps来查看服务是否启动成功
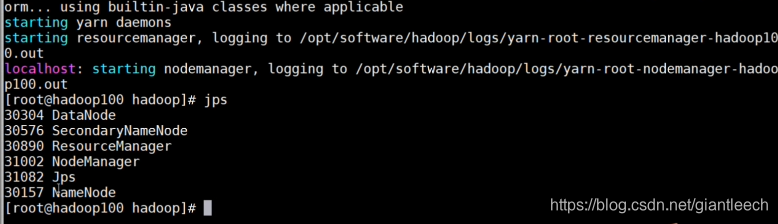
这里可以看到,主要有这6个服务项则表示启动成功
10、测试
同时可以通过本机的浏览器,地址栏输入:
IP地址:50070
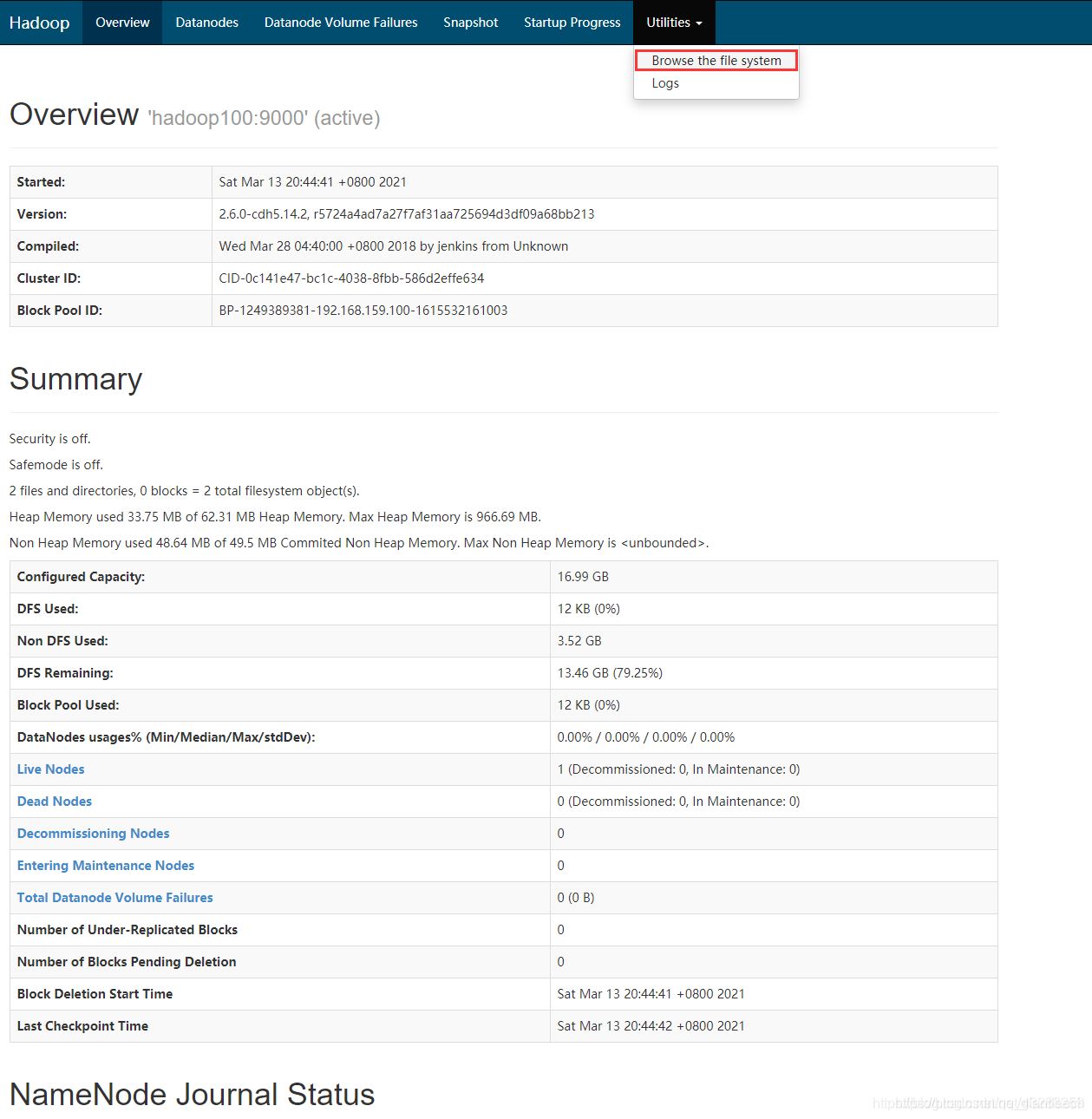
这里就看一更直观的查看Hadoop的分布式文件系统中的文件
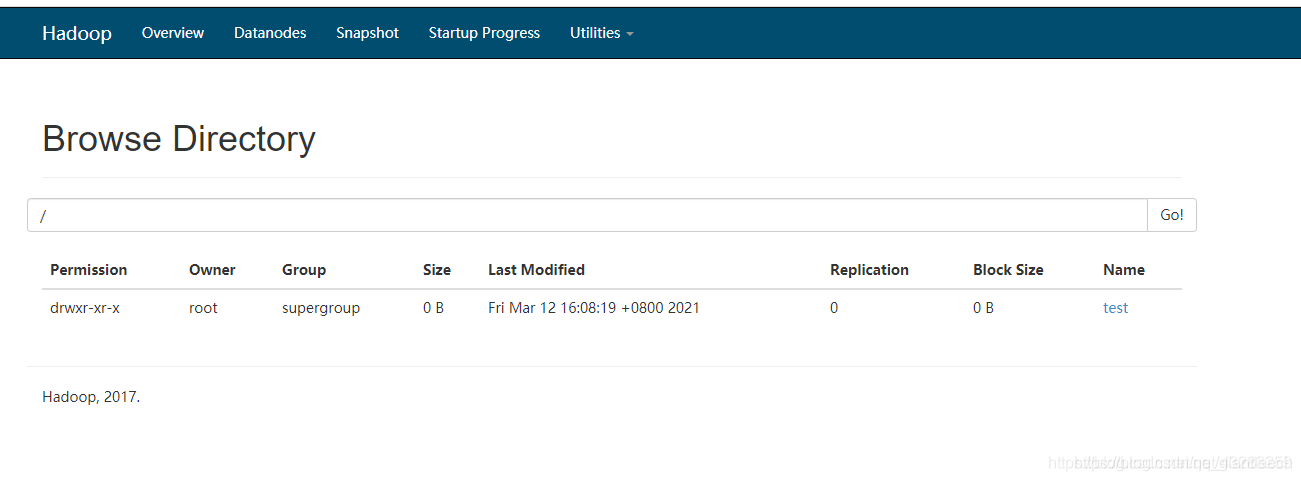
11、上传测试:
输入命令:
hdfs dfs -put READ.txt /test
将文件READ.txt上传到test文件夹
然后输入命令进行计算(对READ.txt文件进行wordcount计数):
hadoop jar share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.14.2.jar wordcount /test/READ.txt /output
`
``
运行成功后输入命令
```sql
hdfs dfs -cat /output/part-r-00000
可以查看到统计的各个单词的数量
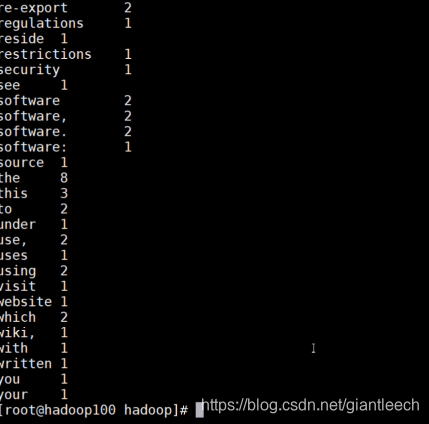
也可以登录浏览器进行查看结果:
IP地址:8088

今天的分享就到这里,谢谢