上篇博客使用scrapy框架爬取豆瓣电影top250信息将各种信息通过json存在文件中,不过对数据的进一步使用显然放在数据库中更加方便,这里将数据存入mysql数据库以便以后利用。
运行环境:
1. win7-64bit
2. python 3.5.3
3. mysql 5.7.17
安装mysql数据库模块
打开命令行输入python后,通过import MySQLdb检查是否支持mysql数据库
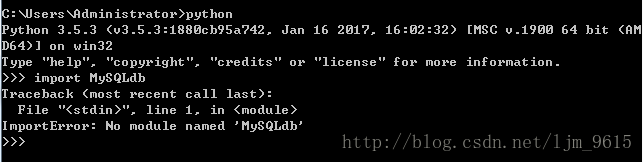
出现错误
ImportError: No module named MySQLdb
那么就要手动安装,查找发现mysqldb只支持到python3.4,这里选择使用pymysql,通过这里下载后解压,切换到PyMySQL3-0.5目录,通过shift+鼠标右键选择在此处打开命令窗口,输入命令python setup.py install安装
安装结束后,测试是否可以使用

安装成功!
创建数据库和表
由于上篇博客中爬取的数据属性就是对应的MovieItem属性
class MovieItem(scrapy.Item):
# 电影名字
name = scrapy.Field()
# 电影信息
info = scrapy.Field()
# 评分
rating = scrapy.Field()
# 评论人数
num = scrapy.Field()
# 经典语句
quote = scrapy.Field()
# 电影图片
img_url = scrapy.Field()据此创建数据库表,创建数据库的时候加上DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci,以防出现乱码
create database douban DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
use douban;
CREATE TABLE doubanmovie (
name VARCHAR(100) NOT NULL, # 电影名字
info VARCHAR(150), # 电影信息
rating VARCHAR(10), # 评分
num VARCHAR(10), # 评论人数
quote VARCHAR(100), # 经典语句
img_url VARCHAR(100), # 电影图片
) 存储数据
首先在项目settings文件中添加与数据库连接相关的变量

MYSQL_HOST = 'localhost'
MYSQL_DBNAME = 'douban'
MYSQL_USER = 'root'
MYSQL_PASSWD = '123456'在MoviePipelines.py文件中创建类DBPipeline,在其中进行对数据库的操作。
首先连接数据库,获取cursor以便之后对数据就行增删查改
def __init__(self):
# 连接数据库
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor();注意这里charset属性为 ‘utf8’,中间没有-,在调试过程中因为这个-搞了半天
之后重载方法process_item(self, item, spider),在其中执行数据的增删查改,通过cursor编写sql语句,然后使用self.connect.commit()提交sql语句
def process_item(self, item, spider):
try:
# 插入数据
self.cursor.execute(
"""insert into doubanmovie(name, info, rating, num ,quote, img_url)
value (%s, %s, %s, %s, %s, %s)""",
(item['name'],
item['info'],
item['rating'],
item['num'],
item['quote'],
item['img_url']))
# 提交sql语句
self.connect.commit()
except Exception as error:
# 出现错误时打印错误日志
log(error)
return item最后在settings文件中注册DBPipeline
ITEM_PIPELINES = {
'doubanmovie.MoviePipelines.MoviePipeline': 1,
'doubanmovie.ImgPipelines.ImgPipeline': 100,
'doubanmovie.MoviePipelines.DBPipeline': 10,
}大功告成后,尝试运行,然而爬取的数据是250条,在数据库存储中只有239条

查看出错日志,发现有以下错误
pymysql.err.ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '), 'https://img3.doubanio.com/view/movie_poster_cover/ipst/public/p2255040492.jp' at line 2")
TypeError: 'module' object is not callable
又是半天折腾,忽然想起来电影的quote属性可能不存在,查看MySpider.py文件,发现果然如此
quote = movie.xpath('.//span[@class="inq"]/text()').extract()
if quote:
quote = quote[0].strip()
item['quote'] = quote如果网页中quote属性不存在,那么将item插入数据库时就会出错,增加一条else语句
if quote:
quote = quote[0].strip()
else:
quote = ' '
item['quote'] = quote再次运行爬虫后,查看数据库,没错,果然这次多了250条数据,数据总数由239变成489

数据查重处理
不过每次执行,重复数据都会多存一次,而我们想要的是多次执行,重复数据只存一遍就好了,那么就要增加查重处理。
这里使用self.cursor.fetchone()方法来判断有没有重复数据,在每次插入数据前,先判断插入item是否已在表中。通过属性img_url查找该item在表中是否存在,如果存在,执行定义的操作,简单起见,这里直接丢掉了,不过可以执行update语句对数据进行更新。
# 查重处理
self.cursor.execute(
"""select * from doubanmovie where img_url = %s""",
item['img_url'])
# 是否有重复数据
repetition = self.cursor.fetchone()
# 重复
if repetition:
pass增加处理后,多次运行爬虫,数据库中不再有重复数据。
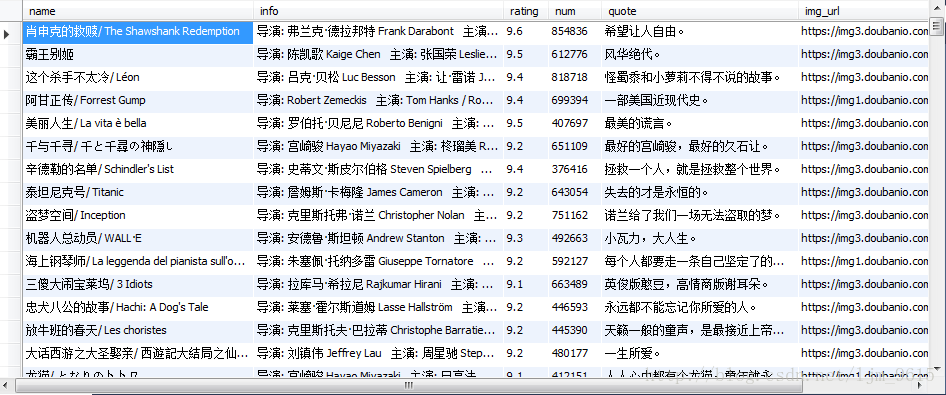
最后整个DBPipeline类代码如下
# 用于数据库存储
class DBPipeline(object):
def __init__(self):
# 连接数据库
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
port=3306,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor();
def process_item(self, item, spider):
try:
# 查重处理
self.cursor.execute(
"""select * from doubanmovie where img_url = %s""",
item['img_url'])
# 是否有重复数据
repetition = self.cursor.fetchone()
# 重复
if repetition:
pass
else:
# 插入数据
self.cursor.execute(
"""insert into doubanmovie(name, info, rating, num ,quote, img_url)
value (%s, %s, %s, %s, %s, %s)""",
(item['name'],
item['info'],
item['rating'],
item['num'],
item['quote'],
item['img_url']))
# 提交sql语句
self.connect.commit()
except Exception as error:
# 出现错误时打印错误日志
log(error)
return item
基本的数据库存储功能算是实现了,虽然足够简单,不过在写的过程中也遇到很多坑,还是要不断百度google来处理遇到的问题。实现数据库存储之后,就可以多爬一些其他数据,然后合理运用一下,搞一些自己的小项目来玩一下