将从一个网站上爬到的数据存入MySQL数据库
先要在数据库中建立相对于的table(表),然后将爬到的数据存入表中就可以了,如下是用类实现的某电影网站爬到的电影数据存入数据库的过程
import requests
import csv
from lxml import etree
import pymysql
class ConnMysql(object):
def __init__(self):
# 连接数据库
self.db = pymysql.connect(host=数据库的地址,
port=3306,
database=数据库名称,
user=数据库的用户名,
password=进入数据库的密码,
charset='utf8')
self.cursor = self.db.cursor()
def insert(self,dict1):
# 将数据添加到数据库中的movie表中
sql = "insert into movie1 (name,type,box,price,people_time,country,time,detail_href) values('%s','%s','%s','%s','%s','%s','%s','%s')"%\
(dict1['name'],dict1['type'],dict1['box'],dict1['price'],dict1['people_time'],dict1['country'],dict1['time'],dict1['detail_href'])
self.cursor.execute(sql)
self.db.commit() # 提交操作
class Pachong(object):
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def work(self,url):
response = requests.get(url=url, headers=self.headers)
html_doc = etree.HTML(response.text)
list1 = ['name','type','box','price','people_time','country','time','detail_href']
for j in range(2,27):
dict_data = {}
for num in range(0,8):
try:
if num ==7: # 详情页网址
value = html_doc.xpath('//tr[%d]/td[1]/a/@href' % j)[0]
elif num ==0: # 电影名称
value = html_doc.xpath('//tr[%d]/td[1]/a/p/text()' % j)[0]
else:
value = html_doc.xpath('//tr[%d]/td[%d]/text()'%(j,num+1))[0]
except:
value = None
dict_data[list1[num]] = value # 将数据存入字典
save_data(dict_data) # 执行保存函数用于选择存储方式
print(j)
def save_data(dict_data):
# 存数据库
database = ConnMysql()
database.insert(dict_data)
if __name__ == '__main__':
test = Pachong()
base_url = '爬取的网站网址'
for i in range(2008, 2020): # 这里是因为爬取的好几页的内容,而每页的网址是通过base_url与数字拼接的
url = base_url + str(i)
test.work(url)
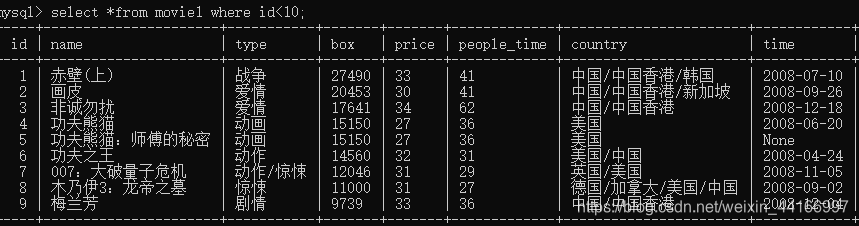
在数据库中查询结果如下图: