基于长范围时间结构(long-range temporal structure)建模,结合了稀疏时间采样策略(sparse temporal sampling strategy)和视频级监督(video-level supervision)来保证使用整段视频时学习得有效和高效。
被ECCV2016接收
论文地址:https://arxiv.org/pdf/1608.00859.pdf
1.摘要
深卷积网络在静止图像的视觉识别中取得了巨大的成功。然而,对于视频中的动作识别,相对于传统方法的优势并不明显。本文旨在探索视频中动作识别的高效ConvNet体系结构的设计原则,并在有限的训练样本下学习这些模型。
主要贡献:
- 时间段网络(TSN),一种新的基于视频的动作识别框架。基于远程时间结构建模的思想。它结合了稀疏时间采样策略和视频级监控,使能够使用整个动作视频进行高效的有效的学习。
- 研究了一系列利用TSN学习视频数据卷积网络的良好实践。
TSN实际上是Two-Stream方法的升级版,在此基础上,文章要解决两个问题:1)how to design an effective and efficient video-level framework for learning video representation that is able to capture long-range temporal structure; 2) how to learn the ConvNet models given limited training samples. 也就是说一个是解决长时间视频的行为判断问题(有些视频的动作时间较长);一个是解决数据少的问题,数据量少会使得一些深层的网络难以应用到视频数据中,因为过拟合会比较严重。
对第一个问题,首先,为什么目前的two stream结构的网络难以学习到long-range temporal structure?因为其针对的主要是single frame或a single stack of frames in a short snippet的数据,但这对于时间跨度较长的视频动作检测而言是不够的。因此采用dense temporal sampling的方式来获取long-range temporal structure是比较常用的方法,但是作者发现视频的连续帧之间存在冗余,因此用sparse temporal sampling代替dense temporal sampling,也就是说在对视频做抽帧的时候采取较为稀疏的抽帧方式,这样可以去除一些冗余信息,同时降低了计算量。
针对第二个问题,可通过常规的data argument(random crop,horizontal flip,corner crop,scale jitter);regularization;还有作者提到的cross-modality pre-training,dropout等方式来减少过拟合。
2.相关工作
动作识别在过去几年中得到了广泛的研究,以往的研究工作分为两类:(1)卷积网络的动作识别,(2)时间结构建模。
用于动作识别的卷积网络
Karpathy等人在一个大数据集(Sports-1M)上测试了具有深层结构的ConvNets。Simonyan等人利用ImageNet数据集进行预训练,计算光流量,设计了包含时空网络的双流convnet,实现了运动信息的显式捕获。Tran等人在真实和大规模视频数据集上探索3D ConvNets,他们试图通过3D卷积操作学习外观和运动特征。Sun等人设计出了一种分解时空转换网,并利用不同的方法分解三维卷积核。
近年来,一些研究集中在用ConvNets建模远程时间结构上。然而,这些方法直接在较长的连续视频流上操作。由于计算量的限制,这些方法通常处理64帧到120帧不等的固定长度序列。由于时间覆盖的限制,这些方法从整个视频中学习是非常重要的。
我们的方法是从这些端到端的深度转换网络中分离出来的,它采用了一种新的稀疏时间采样策略,使得在不受序列长度限制的情况下,能够利用整个视频进行有效的学习。
时间结构建模。
盖登等人为每个视频标注每个原子动作,并提出动作检测的Actom序列模型(ASM)。Niebles等人提出利用隐变量对复杂动作的时间分解进行建模,并借助支持向量机对模型参数进行迭代学习。Wang等人以及Pirsiavash等人使用潜在层次模型(LHM)和分段语法模型(SGM)将复杂动作的时间分解扩展为层次化方式。王等人设计了一个序列骨架模型(SSM)来捕捉动态poselets之间的关系,并进行时空动作检测。费尔南多建立了BoVW动作识别表征的时间演化模型。
然而,这些方法仍然无法组装用于建模时序结构的端到端学习方案。本文提出的时态分段网络,在强调这一原则的同时,也是对整个视频进行端到端时态结构建模的第一个框架。
3. 本文方法
3.1 网络结构
目前双流网络存在的一个明显问题是无法对长时间结构进行建模。这主要是因为它们对时间上下文的访问有限,因为它们被设计成只在一个帧(空间网络)上操作,或在一个短片段(时间网络)中操作一个帧堆栈。然而,复杂的动作,如体育动作,包含了跨越相对较长时间的多个阶段。如果不能在ConvNet训练中利用这些动作的长时程结构,那将是一个巨大的损失。
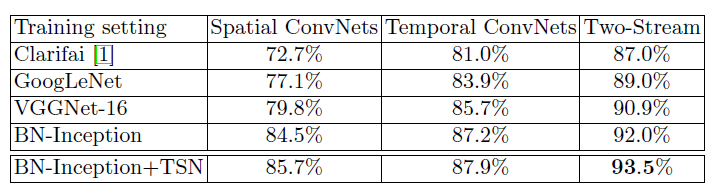
为了解决这个问题,本文提出了时态分段网络,如图1所示,以便能够在整个视频中建模动态。具体来说,TSN旨在利用整个视频的视觉信息进行视频级预测,TSN也由空间流ConvNets和时间流ConvNets组成。
TSN不是处理单个帧或帧堆栈,而是对从整个视频中稀疏采样的一系列短片段进行操作。这个序列中的每个片段都将产生自己的动作类的初步预测。然后将片段之间的一致性作为视频级预测。在学习过程中,通过迭代更新模型参数来优化视频级预测的损失值,而不是用于双流convnet的片段级预测的损失值。
具体来说,给定一个视频V,我们把它分成K段:S1,S2,…,Sk,其持续时间相等。然后,TSN将片段序列建模如下:
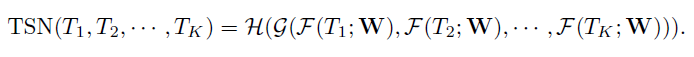
其中:
- (T1,T2,…,TK)是一个片段序列。每个片段Tk从其对应的片段Sk中随机采样。
- F(Tk,W)是一个函数,它用参数W表示ConvNet,参数W对短片段Tk进行操作,并为所有类生成类分数。
- 段共识函数G将多个短片段的输出结合起来,得到它们之间的类假设一致性。
- 基于这一共识,预测函数H预测整个视频的每个动作类的概率。在这里,本文选择了H的广泛使用的Softmax函数。
- 再结合标准分类交叉熵损失,分段共识G的损失函数如下:

其中C是动作类的个数,yi是关于类i的基本真值标签。在实验中,K的个数被设置为3。共识函数G的形式使用G的最简单形式,其中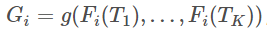 。在这里,使用聚合函数g,从所有片段上的同一类分数推断出类分数Gi。本文对聚合函数g的几种不同形式进行了经验评估,包括均匀平均、最大值和加权平均。最终,使用的是均匀平均。
。在这里,使用聚合函数g,从所有片段上的同一类分数推断出类分数Gi。本文对聚合函数g的几种不同形式进行了经验评估,包括均匀平均、最大值和加权平均。最终,使用的是均匀平均。
根据g的选择,TSN是可微的,或者至少有次梯度。这使得我们可以利用多个片段联合使用标准的反向传播算法来优化模型参数W。在反向传播过程中,模型参数的梯度关于损失值,W可以导出:
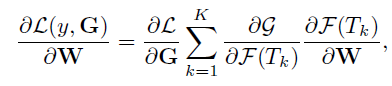
其中K是TSN使用的段数。当我们使用基于梯度的优化方法,如随机梯度下降(SGD)来学习模型参数时,上面的等式保证了参数更新是利用从所有片段级预测中得到的分段一致性G。以这种方式优化,TSN可以从整个视频而不是一个短片段中学习模型参数。同时,通过对所有视频的 K,作者提出了一个稀疏的时间采样策略,其中采样片段只包含一小部分帧。与以前使用密集采样帧的工作相比,它大大降低了在帧上评估convnet的计算成本。
3.2 学习TSN
为了达到最佳表现,一些好的实践如下:
网络结构
一些工作表明更深的结构可以提升物体识别的表现。然而,two-stream网络采用了相对较浅的网络结构(ClarifaiNet)。本文选择BN-Inception (Inception with Batch Normalization)构建模块,由于它在准确率和效率之间有比较好的平衡。作者将原始的BN-Inception架构适应于two-stream架构,和原始two-stream卷积网络相同,空间流卷积网络操作单一RGB图像,时间流卷积网络将一堆连续的光流场作为输入。
网络输入
TSN通过探索更多的输入模式来提高辨别力。除了像two-stream那样,空间流卷积网络操作单一RGB图像,时间流卷积网络将一堆连续的光流场作为输入,作者提出了两种额外的输入模式:RGB差异(RGB difference)和扭曲的光流场(warped optical flow fields)。

单一RGB图像表征特定时间点的静态信息,从而缺少上下文信息。如上图2所示,两个连续帧的RGB差异表示动作的改变,对应于运动显著区域。故试验将RGB差异堆作为另一个输入模式。
TSN将光流场作为输入,致力于捕获运动信息。在现实拍摄的视频中,通常存在摄像机的运动,这样光流场就不是单纯体现出人类行为。如上图2所示,由于相机的移动,视频背景中存在大量的水平运动。受到iDT(improved dense trajectories)工作的启发,作者提出将扭曲的光流场作为额外的输入。通过估计单应性矩阵(homography matrix)和补偿相机运动来提取扭曲光流场。如图2所示,扭曲光流场抑制了背景运动,使得专注于视频中的人物运动。
网络训练
由于行为检测的数据集相对较小,训练时有过拟合的风险,为了缓解这个问题,作者设计了几个训练策略。
(1)交叉输入模式预训练
空间网络以RGB图像作为输入:故采用在ImageNet上预训练的模型做初始化。对于其他输入模式(比如:RGB差异和光流场),它们基本上捕捉视频数据的不同视觉方面,并且它们的分布不同于RGB图像的分布。作者提出了交叉模式预训练技术:利用RGB模型初始化时间网络。
首先,通过线性变换将光流场离散到从0到255的区间,这使得光流场的范围和RGB图像相同。然后,修改RGB模型第一个卷积层的权重来处理光流场的输入。具体来说,就是对RGB通道上的权重进行平均,并根据时间网络输入的通道数量复制这个平均值。这一策略对时间网络中降低过拟合非常有效。
(2)正则化技术
在学习过程中,Batch Normalization将估计每个batch内的激活均值和方差,并使用它们将这些激活值转换为标准高斯分布。这一操作虽可以加快训练的收敛速度,但由于要从有限数量的训练样本中对激活分布的偏移量进行估计,也会导致过拟合问题。因此,在用预训练模型初始化后,冻结所有Batch Normalization层的均值和方差参数,但第一个标准化层除外。由于光流的分布和RGB图像的分布不同,第一个卷积层的激活值将有不同的分布,于是,我们需要重新估计的均值和方差,称这种策略为部分BN。与此同时,在BN-Inception的全局pooling层后添加一个额外的dropout层,来进一步降低过拟合的影响。dropout比例设置:空间流卷积网络设置为0.8,时间流卷积网络设置为0.7。
(3)数据增强
数据增强能产生不同的训练样本并且可以防止严重的过拟合。在传统的two-stream中,采用随机裁剪和水平翻转方法增加训练样本。作者采用两个新方法:角裁剪(corner cropping)和尺度抖动(scale-jittering)。
角裁剪(corner cropping):仅从图片的边角或中心提取区域,来避免默认关注图片的中心。
尺度抖动(scale jittering):将输入图像或者光流场的大小固定为 256×340256×340,裁剪区域的宽和高随机从 {256,224,192,168}{256,224,192,168} 中选择。最终,这些裁剪区域将会被resize到 224×224224×224 用于网络训练。事实上,这种方法不光包括了尺度抖动,还包括了宽高比抖动。
3.3测试TSN
由于在TSN中片段级的卷积网络共享模型参数,所以学习到的模型可以进行帧评估。具体来说,作者采用与two-stream相同的测试方案——即从动作视频中采样25个RGB帧或光流堆。同时,从采样得到的帧中裁剪4个边角和1个中心以及它们的水平翻转来评估卷积网络。
空间和时间流网络采用加权平均的方式进行融合。相比于two-strean,TSN中空间流卷积网络和时间流卷积网络的性能差距大大缩小。基于此,设置空间流的权重为1,设置时间流的权重为1.5。当正常和扭曲光流场都使用时,将其权重1.5分出1给正常光流场,0.5给扭曲光流场。
在TSN部分说过,段共识函数在Softmax归一化之前。为了根据训练测试模型,在Softmax之前融合了25帧和不同流的预测分数。
4. 实验
(1)不同输入模式的表现
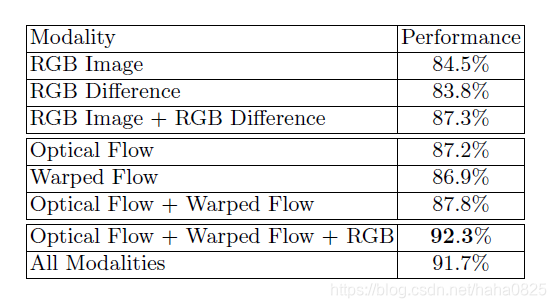
(2)不同训练策略的比较
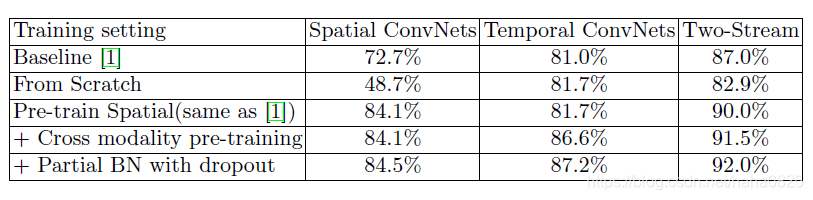
(3)不同段共识函数的比较

(4)不同深度卷积神经网络的比较