mnist_forward.py
import tensorflow as tf
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
def get_weight(shape,regularizer):
w = tf.Variable(tf.truncated_normal(shape,stddev=0.1))
if regularizer != None:tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
def get_bias(shape):
b = tf.Variable(tf.zeros(shape))
return b
def forward(x,regularizer):
w1 = get_weight([INPUT_NODE,LAYER1_NODE],regularizer)
b1 = get_bias([LAYER1_NODE])
y1 = tf.nn.relu(tf.matmul(x,w1)+b1)
w2 = get_weight([LAYER1_NODE,OUTPUT_NODE],regularizer)
b2 = get_bias([OUTPUT_NODE])
y = tf.matmul(y1,w2)+b2
return y
tf.truncated_normal:产生截断正态分布随机数,取值范围为 [ mean - 2 * stddev, mean + 2 * stddev ]。(mean默认0.0)此处即为[-0.2,0.2]
由上述代码可知,在前向传播过程中,规定网络输入结点为 784 个(代表每张输入图片的像素个数),隐藏层节点 500 个,输出节点 10 个(表示输出为数字 0-9的十分类)。由输入层到隐藏层的参数 w1 形状为[784,500],由隐藏层到输出层的参数 w2 形状为[500,10],参数满足截断正态分布,并使用正则化,将每个参数的正则化损失加到总损失中。由输入层到隐藏层的偏置 b1 形状为长度为 500
的一维数组,由隐藏层到输出层的偏置 b2 形状为长度为 10 的一维数组,初始化值为全 0。前向传播结构第一层为输入 x 与参数 w1 矩阵相乘加上偏置 b1,再经过 relu 函数,得到隐藏层输出 y1。前向传播结构第二层为隐藏层输出 y1 与参数 w2 矩阵相乘加上偏置 b2,得到输出 y。由于输出 y 要经过 softmax 函数,使其符合概率分布,故输出 y 不经过 relu 函数。
mnist_backward.py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_forward
import os
BATCH_SIZE = 200
LEARNING_RATE_BASE = 0.1
LEARNING_RATE_DECAY = 0.99
REGULARIZER = 0.0001
STEPS = 50000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = "./model/"
MODEL_NAME = "mnist_model"
def backward(mnist):
x = tf.placeholder(tf.float32,[None,mnist_forward.INPUT_NODE])
y_ = tf.placeholder(tf.float32,[None,mnist_forward.OUTPUT_NODE])
y = mnist_forward.forward(x,REGULARIZER)
global_step = tf.Variable(0,trainable=False)
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cem = tf.reduce_mean(ce)
loss = cem + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples/BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
ema_op = ema.apply(tf.trainable_variables())
with tf.control_dependencies([train_step,ema_op]):
train_op = tf.no_op(name='train')
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(STEPS):
xs,ys = mnist.train.next_batch(BATCH_SIZE)
_,loss_value,step = sess.run([train_op,loss,global_step],feed_dict={x:xs,y_:ys})
if i % 1000 == 0:
print("After %d training steps(s),loss on training batch is %g." % (step,loss_value))
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
def main():
mnist = input_data.read_data_sets("./data/",one_hot=True)
backward(mnist)
if __name__ == '__main__':
main()
在反向传播过程中,首先引入 tensorflow、input_data、前向传播 mnist_forward 和 os 模块,定义每轮喂入神经网络的图片数、初始学习率、学习率衰减率、正则化系数、训练轮数、模型保存路径以及模型保存名称等相关信息。在反向传播函数 backword 中,首先读入 mnist,用 placeholder 给训练数据 x 和标签 y_占位,调用 mnist_forward 文件中的前向传播过程 forword()函数,并设置正则化,计算训练数据集上的预测结果 y,并给当前计算轮数计数器赋值,设定为不可训练类型。接着,调用包含所有参数正则化损失的损失函数loss,并设定指数衰减学习率 learning_rate。然后,使用梯度衰减算法对模型优化,降低损失函数,并定义参数的滑动平均。最后,在 with 结构中,实现所有参数初始化,每次喂入 batch_size 组(即 200 组)训练数据和对应标签,循环迭代 steps 轮,并每隔 1000 轮打印出一次损失函数值信息,并将当前会话加 载到指定路径。最后,通过主函数 main(),加载指定路径下的训练数据集,并调用规定的 backward()函数训练模型。
(Tensorflow中定义的时,可以通过trainable属性控制这个变量是否可以被优化器更新。关于此处global_step设置为trainable=False的困惑参见这篇文章link~
mnist_test.py
当训练完模型后,给神经网络模型输入测试集验证网络的准确性和泛化性。注意,所用的测试集和训练集是相互独立的。
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_forward
import mnist_backward
TEST_INTERVAL_SEC = 5
def test(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32,[None,mnist_forward.INPUT_NODE])
y_ = tf.placeholder(tf.float32,[None,mnist_forward.OUTPUT_NODE])
y = mnist_forward.forward(x,None)
ema = tf.train.ExponentialMovingAverage(mnist_backward.MOVING_AVERAGE_DECAY)
ema_restore = ema.variables_to_restore()
saver = tf.train.Saver(ema_restore)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('.')[-1]
accuracy_score = sess.run(accuracy,feed_dict={x:mnist.test.images,y_:mnist.test.labels})
print("After %s training step(s),test accuracy = %g" % (global_step,accuracy_score))
else:
print("No checkpoint file found")
return
time.sleep(TEST_INTERVAL_SEC)
def main():
mnist = input_data.read_data_sets('./data/',one_hot=True)
test(mnist)
if __name__ == '__main__':
main()
在上述代码中,首先需要引入 time 模块、tensorflow、input_data、前向传播mnist_forward、反向传播 mnist_backward 模块和 os 模块,并规定程序 5 秒的循环间隔时间。接着,定义测试函数 test(),读入 mnist 数据集,利用 tf.Graph()复现之前定义的计算图,利用 placeholder 给训练数据 x 和标签 y_占位,调用mnist_forward 文件中的前向传播过程 forword()函数,计算训练数据集上的预测结果 y。接着,实例化具有滑动平均的 saver 对象,从而在会话被加载时模型中的所有参数被赋值为各自的滑动平均值,增强模型的稳定性,然后计算模型在测试集上的准确率。在 with 结构中,加载指定路径下的 ckpt,若模型存在,则加载出模型到当前对话,在测试数据集上进行准确率验证,并打印出当前轮数下的准确率,若模型不存在,则打印出模型不存在的提示,从而 test()函数完成。通过主函数 main(),加载指定路径下的测试数据集,并调用规定的 test 函数,进行模型在测试集上的准确率验证。
运行:
python mnist_forward.py
另开一个命令行
python mnist_test.py

从终端显示的运行结果可以看出,随着训练轮数的增加,网络模型的损失函数值在不断降低,并且在测试集上的准确率在不断提升,有较好的泛化能力。
一个改进:上面的训练代码每次都是从头开始训练?如何断点续训呢?
在反向传播中加入这些代码
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
1)tf.train.get_checkpoint_state(checkpoint_dir,latest_filename=None)
该函数表示如果断点文件夹中包含有效断点状态文件,则返回该文件。
参数说明:
checkpoint_dir:表示存储断点文件的目录
latest_filename=None:断点文件的可选名称,默认为“checkpoint”
2)saver.restore(sess, ckpt.model_checkpoint_path)
该函数表示恢复当前会话,将 ckpt 中的值赋给 w 和 b。
参数说明:
sess:表示当前会话,之前保存的结果将被加载入这个会话
ckpt.model_checkpoint_path:表示模型存储的位置,不需要提供模型的名字,它会去查看 checkpoint 文件,看看最新的是谁,叫做什么。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_forward
import os
BATCH_SIZE = 200
LEARNING_RATE_BASE = 0.1
LEARNING_RATE_DECAY = 0.99
REGULARIZER = 0.0001
STEPS = 50000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = "./model/"
MODEL_NAME = "mnist_model"
def backward(mnist):
x = tf.placeholder(tf.float32,[None,mnist_forward.INPUT_NODE])
y_ = tf.placeholder(tf.float32,[None,mnist_forward.OUTPUT_NODE])
y = mnist_forward.forward(x,REGULARIZER)
global_step = tf.Variable(0,trainable=False)
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cem = tf.reduce_mean(ce)
loss = cem + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples/BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
ema_op = ema.apply(tf.trainable_variables())
with tf.control_dependencies([train_step,ema_op]):
train_op = tf.no_op(name='train')
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
#!!!!!!加在这里
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
for i in range(STEPS):
xs,ys = mnist.train.next_batch(BATCH_SIZE)
_,loss_value,step = sess.run([train_op,loss,global_step],feed_dict={x:xs,y_:ys})
if i % 1000 == 0:
print("After %d training steps(s),loss on training batch is %g." % (step,loss_value))
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
def main():
mnist = input_data.read_data_sets("./data/",one_hot=True)
backward(mnist)
if __name__ == '__main__':
main()
以上部分完成了基于已有的MNIST数据集训练手写数字识别的模型。
接下来要考虑的是
如何根据以上过程训练出的模型对新的真实的数据输出预测结果?
如何制作数据集,实现特定应用?
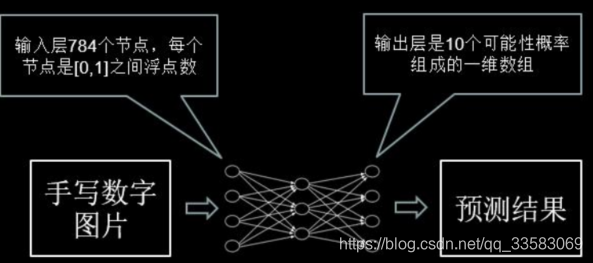
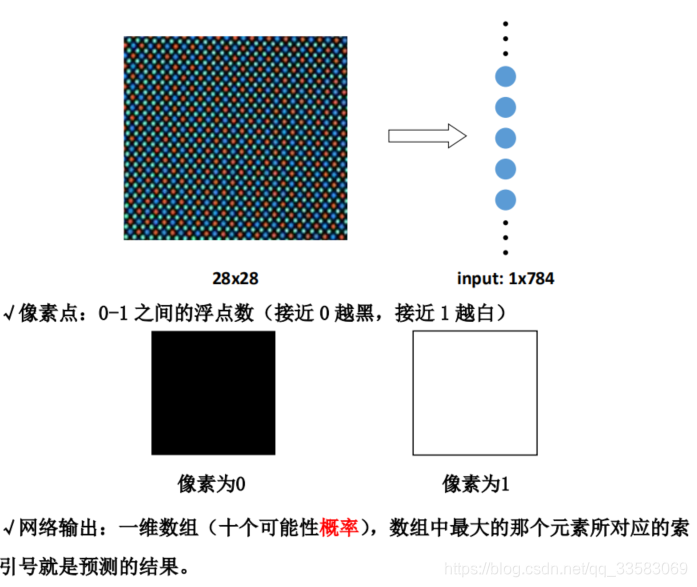
在将带预测的图片输入神经网络之间需要经过一些处理,这些过程抽象如下:
def application():
testNum = input("input the number of test pictures:")
for i in range(testNum):
testPic = raw_input("the path of test picture:")
testPicArr = pre_pic(testPic)
preValue = restore_model(testPicArr)
print "The prediction number is:", preValue
1)testPicArr = pre_pic(testPic)对手写数字图片做预处理
2)preValue = restore_model(testPicArr) 将符合神经网络输入要求的图片喂给复现的神经网络模型,输出预测值
mnist_app.py
import tensorflow as tf
import numpy as np
from PIL import Image
import mnist_backward
import mnist_forward
def restore_model(testPicArr):
with tf.Graph().as_default() as tg:
x = tf.placeholder(tf.float32,[None,mnist_forward.INPUT_NODE])
y = mnist_forward.forward(x,None)
preValue = tf.argmax(y,1) # 得到概率最大的预测值
variable_averages = tf.train.ExponentialMovingAverage(mnist_backward.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path)
preValue = sess.run(preValue,feed_dict={x:testPicArr})
return preValue
else:
print("No checkpoint file found")
return -1
def pre_pic(picName):
img = Image.open(picName)
reIm = img.resize((28,28),Image.ANTIALIAS) #转化为灰度图
im_arr = np.array(reIm.convert('L'))
threshold = 50
for i in range(28):
for j in range(28):
im_arr[i][j] = 255 - im_arr[i][j]
if im_arr[i][j] < threshold:
im_arr[i][j] = 0
else: im_arr[i][j] = 255
num_arr = im_arr.reshape([1,784])
nm_arr = num_arr.astype(np.float32)
img_ready = np.multiply(nm_arr,1.0/255.0)
return img_ready
def application():
testNum = int(input("input the number of test pictures:"))
for i in range(testNum):
testPic = input("the path of test picture:")
testPicArr = pre_pic(testPic)
preValue = restore_model(testPicArr)
print("The prediction number is:",preValue)
def main():
application()
if __name__ == '__main__':
main()
然后自己画一个28x28的图片(白底黑字)进行测试

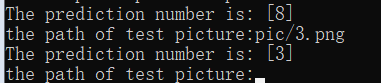
测试环境:
python3.5.2
tensorflow1.2.1
