RDD
RDD(Resilient Distributed Datasets)叫做弹性分布式数据集,是Spark中最基本的数据抽象,源码中是一个抽象类,代表一个不可变、可分区、里面的元素可并行计算的集合。编译时类型安全,但是无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行序列化和反序列化,还存在较大的GC的性能开销,会频繁的创建和销毁对象。RDD也不支持SparkSQL操作。
DataFrame
与RDD类似,DataFrame是一个分布式数据容器,不过它更像数据库中的二维表格,除了数据之外,还记录这数据的结构信息(即schema)。DataFrame也是懒执行的,性能上要比RDD高(主要因为执行计划得到了优化)。由于RDD每一行的数据结构一样,且存在schema中,Spark通过schema就能读懂数据,因此在通信和IO时只需要序列化和反序列化数据,而结构部分不用。Spark能够以二进制的形式序列化数据到JVM堆以外(off-heap:非堆)的内存,这些内存直接受操作系统管理,也就不再受JVM的限制和GC的困扰了。但是DataFrame不是类型安全的。
DataSet
DataSet是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。DataFrame=DataSet[Row](Row表示表结构信息的类型),DataFrame只知道字段,但是不知道字段类型,而DataSet是强类型的,不仅仅知道字段,而且知道字段类型。样例类被用来在DataSet中定义数据的结构信息,样例类中的每个属性名称直接对应到DataSet中的字段名称。DataSet具有类型安全检查,也具有DataFrame的查询优化特性,还支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
RDD、DataFrame和DataSet之间的转换
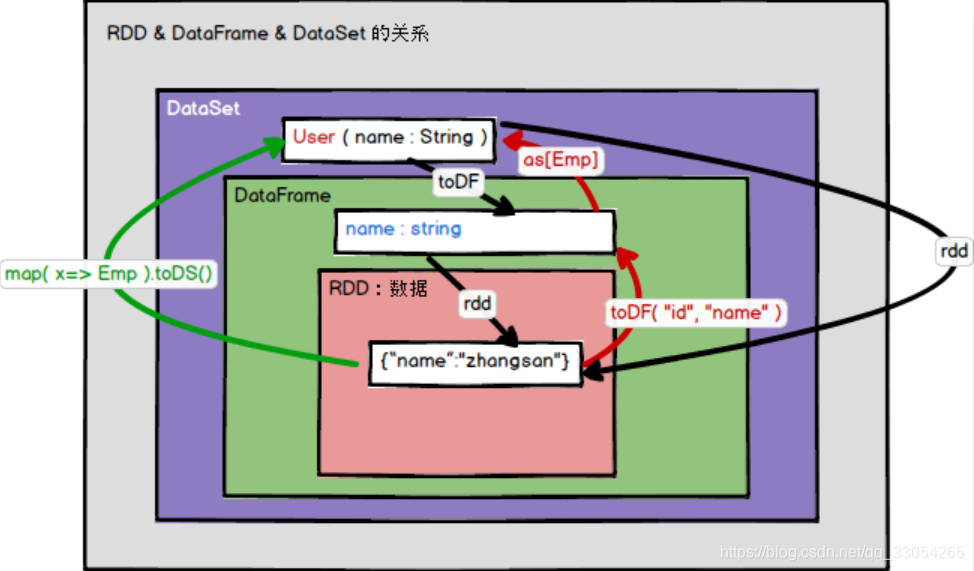
假设有个样例类:
case class Emp(id: Long, name: String)
RDD转换到DataFrame:rd.toDF(“id”, “name”)
RDD转换到DataSet:rd.map(x => Emp(x._1, x._2)).toDS
DataFrame转换到DataSet:df.as[Emp]
DataFrame转换到RDD:df.rdd
DataSet转换到DataFrame:ds.toDF
DataSet转换到RDD:ds.rdd
注意:RDD与DataFrame或者DataSet进行操作,都需要引入隐式转换import spark.implicits._,其中的spark是SparkSession对象的名称!