[TOC]
1 说明
根据之前old li(百度高级大数据工程师)给的一张草图重新整理,并用processon绘图一下,这样就更加清晰了。需要注意的是,这里是基于Spark 2.x以下的版本,因为在之前,底层通信是基于AKKA ACTOR的方式,但是之后就是使用RPC的方式了。(最近原来是想把spark 2.x的源码好好阅读一下,但是公司已有的系统都是基于spark 1.x的,并且最近才更新到spark 1.6.3,所以也不折腾,就把spark 1.x的好好搞透,也不影响后面进一步的深入学习与解理,因为这些都是触类旁通的。)
另外,这里的原理图是spark standalone模式,关于其它模式(如spark on yarn),后面则会再整理一下。
2 运行架构原理图与解析
原理图如下:
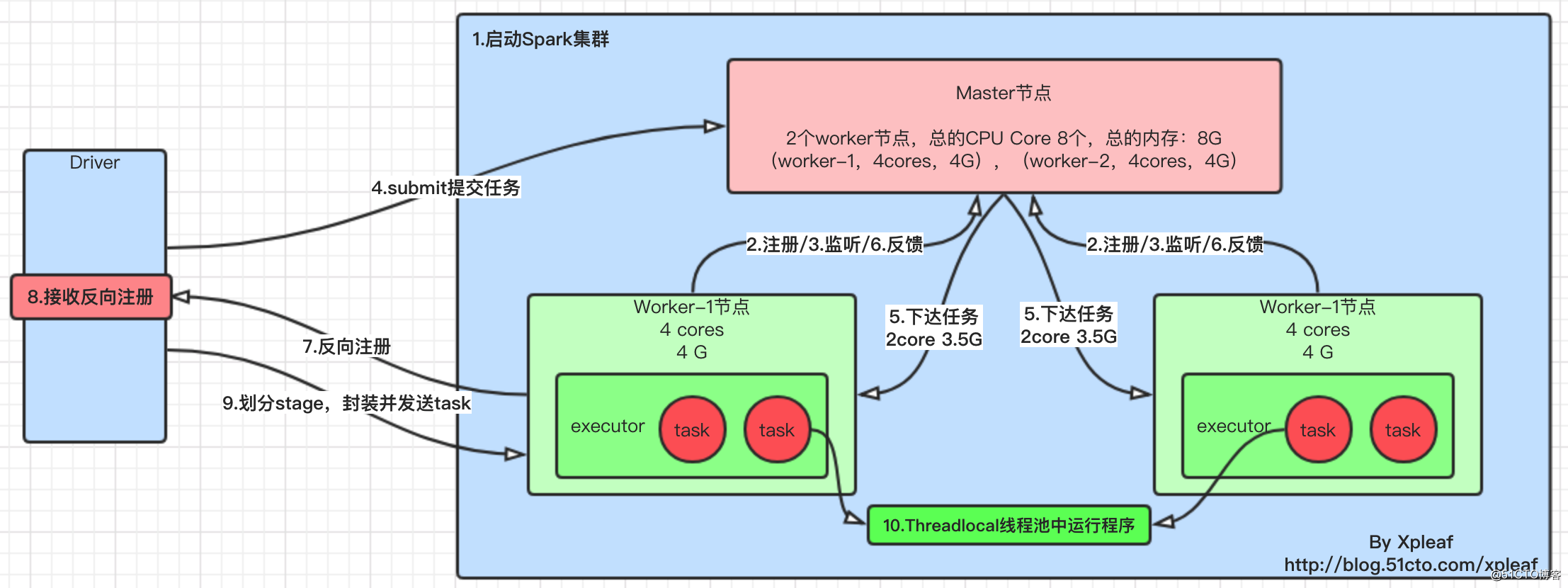
说明如下:
- 1.启动
Spark集群,其实就是通过运行spark-all.sh脚本来启动master节点和worker节点,启动了一个个对应的master进程和worker进程; - 2.
worker启动之后,向master进程发送注册信息(该过程基于AKKA Actor事件驱动模型); - 3.
worker向master注册成功之后,会不断向master发送心跳包,监听master节点是否存活(该过程基于AKKA Actor事件驱动模型); - 4.
driver向Spark集群提交作业,通过spark-submit.sh脚本,向master节点申请资源(该过程基于AKKA Actor事件驱动模型); - 5.
master收到Driver提交的作业请求之后,向worker节点指派任务,其实就是让其启动对应的executor进程; - 6.
worker节点收到master节点发来的启动executor进程任务,就启动对应的executor进程,同时向master汇报启动成功,处于可以接收任务的状态; - 7.当
executor进程启动成功后,就像Driver进程反向注册,以此来告诉driver,谁可以接收任务,执行spark作业(该过程基于AKKA Actor事件驱动模型); - 8.
driver接收到注册之后,就知道了向谁发送spark作业,这样在spark集群中就有一组独立的executor进程为该driver服务; - 9.
SparkContext重要组件运行——DAGScheduler和TaskScheduler,DAGScheduler根据宽依赖将作业划分为若干stage,并为每一个阶段组装一批task组成taskset(task里面就包含了序列化之后的我们编写的spark transformation);然后将taskset交给TaskScheduler,由其将任务分发给对应的executor; - 10.
executor进程接收到driver发送过来的taskset,进行反序列化,然后将这些task封装进一个叫taskrunner的线程中,放到本地线程池中,调度我们的作业的执行;
3 疑惑与解答
1.为什么要向Executor发送taskset?
移动数据的成本远远高于移动计算,在大数据计算领域中,不管是spark还是MapReduce,都遵循一个原则:移动计算,不移动数据!
2.因为最终的计算都是在worker的executor上完成的,那么driver为什么要将spark作业提交给master而不提交给worker?
可以举个简单的例子来说明这个问题,假如现在集群有8 cores、8G内存(两个worker节点,资源一样的,所以每个worker节点为4 cores、4G),而提交的spark任务需要4 cores、6G内存,如果要找worker,请问哪一个worker能搞定?显然都不能,所以需要通过master来进行资源的合理分配,因为此时的计算是分布式计算,而不再是过去传统的单个节点的计算了。