hive作为hadoop系列的计算模型,在公司的数据清洗和报表开发广泛使用,合理的优化自己的语句结构可以节省计算时间,优化集群的计算资源,下面总结下日常工作中自己碰到的一些问题和别人总结的一些方法。
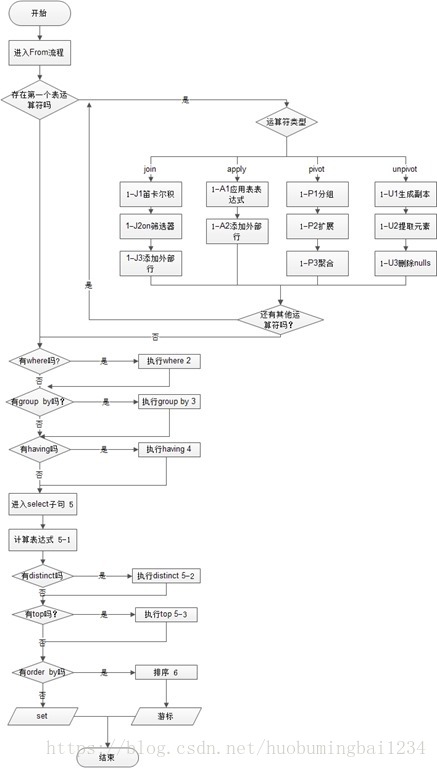
我们先了解下关系型数据库sql的执行顺序,hive大致相同
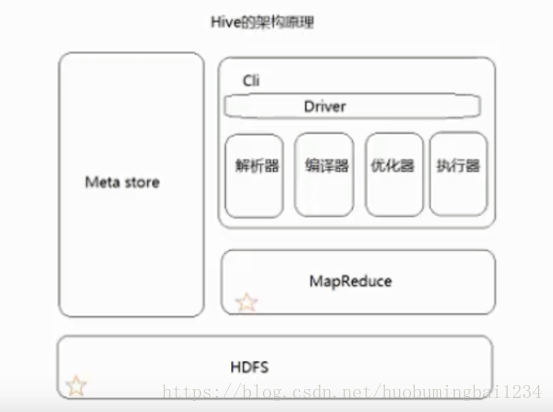
然后大致了解下hive的架构:
具体策略:
1、尽早的过滤数据,hive同样会先执行join,再执行where,分区表要加分区,同时只选择需要使用到的字段(尤其是大表)
2、order by全局排序会集中到一个reducer上执行,对于大数据集效率会极低,如果没有实际需求,避免使用
同时,一般会设置 hive.mapred.mode=nonstrict,这时候使用order by必须加limit关键字
order by默认顺序是升序(asc)。在Hive 2.1.0及以上版本,支持对null值进行排序,升序排序是null值被排在第一位,降序时null值被排在最后。
3、避免使用count(distinct)操作, 解决方法:先使用group by去重,再count计算。
4、join时小表放在左边,大表放在右边,hive会将小表放进内存。两张数据量相差特别大的表进行join操作时,如果小表特别小(比如几百几千条记录),使用mapjoin。在hive0.7版本后,也能够用配置来自己主动优化 set hive.auto.convert.join=true;
数仓设计时销售数据大多数会用星型模型,即事实表和维度表相关联,这种问题比较常见
5、如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,实际测试过程中,执行时间能提升50%(实际没碰到过,真实度待定)
6、hive支持in的子查询写法,尽量用left semi join代替
7、多表join时使用相同的连接键
当对3个或者更多个表进行join连接时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MapReduce job。
8、对于事实表,有分区的一定要加分区
对于join和Group操作都可能会出现数据倾斜。
以下有几种解决这个问题的常见思路
1、参数hive.groupby.skewindata = true,解决数据倾斜的万能钥匙,查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
2、where的条件写在join里面,使得减少join的数量(经过map端过滤,只输出复合条件的)
3、mapjoin方式,无reduce操作,在map端做join操作(map端cache小表的全部数据),这种方式下无法执行Full/RIGHT OUTER join操作
4、对于count(distinct)操作,在map端以group by的字段和count的字段联合作为key,如果有大量相同的key,那么会存在数据倾斜的问题
5、数据的倾斜还包括,大量的join连接key为空的情况,空的key都hash到一个reduce上去了,解决这个问题,最好把空的key和非空的key做区分
空的key不做join操作。
当然有的hive操作,不存在数据倾斜的问题,比如数据聚合类的操作,像sum、count,因为已经在map端做了聚合操作了,到reduce端的数据相对少一些,所以不存在这个问题。