Hive provides two execution engines: Apache Hadoop MapReduce and Apache TEZ. Tez is faster than MapReduce.
配置优化
tez配置优化
调整mapper
任务症状
任务中Map个数较大,超过2W甚至5W,资源紧张时任务申请不到资源;下游reduce因为上游map数量大导致shuffle慢。mapper数量与输入文件的split数息息相关,在Hadoop源码org.apache.hadoop.mapreduce.lib.input.FileInputFormat类中可以看到split划分的具体逻辑。
调优方法
set hive.execution.engine=tez;
set tez.grouping.max-size=67108864; //如果map数过多,可以加大这个值比如*2。当前map运行时的tez.grouping.max-size就是对应于日志里面的Map 1 Split size。
set hive.tez.map.memory.mb=3072; //beyond physical memory limits时或者oom时就可以调整map或者reduce内存大小。
"1,删除任务中的split size,使用平台默认的Split 切分算法(平台默认 Split 切分算法会考虑任务读取数据量 或 子任务的执行时间,来确定Split Size。)。
2,若需要手动调整split size,则需要打开任务运行日志链接,查看平均map运行时间。map平均运行时间以5min左右为合理,调整后map数最大不得超过50000。
tez任务调整参数:tez.grouping.max-size,单位bytes
mr任务调整参数:mapreduce.input.fileinputformat.split.maxsize或 mapred.max.split.size , 单位bytes"
tez 图示:每个map对应的total tasks,就是map个数 图示:task type对应是map时,total就是map个数
mr 可以直接通过参数mapred.map.tasks(默认值2)来设定mapper数的期望值,但它不一定会生效,下面会提到。
备注
"1,若任务确实需要使用较小的split size(如10M),则可以不开启优化(保留split size 参数即可)
2,若map存在较严重的倾斜(多个map任务超过15min以上,而平均map时间在1min以内),则可以不必调大split size"
设输入文件的总大小为total_input_size。HDFS中,一个块的大小由参数dfs.block.size指定,默认值64MB或128MB。在默认情况下,mapper数就是:
default_mapper_num = total_input_size / dfs.block.size。
参数mapred.min.split.size(默认值1B)和mapred.max.split.size(默认值64MB)分别用来指定split的最小和最大大小。split大小和split数计算规则是:
split_size = MAX(mapred.min.split.size, MIN(mapred.max.split.size, dfs.block.size));
split_num = total_input_size / split_size。
得出mapper数:
mapper_num = MIN(split_num, MAX(default_num, mapred.map.tasks))。
可见,如果想减少mapper数,就适当调高mapred.min.split.size,split数就减少了。如果想增大mapper数,除了降低mapred.min.split.size之外,也可以调高mapred.map.tasks。
一般来讲,如果输入文件是少量大文件,就减少mapper数;如果输入文件是大量非小文件,就增大mapper数;至于大量小文件的情况,得参考下面“合并小文件”一节的方法处理。
调整reducer
任务症状 reduce运行时间长
调优方法 "1,通过任务运行日志查看reduce平均运行时间,若平均reduce时间小于1min,禁止再次调大reduce个数。对于Reduce时间在1min以下的任务,需要减小reduce个数。 2,reduce个数上限为3000。大于3000个reduce的任务会变得更慢,并且增大shuffle慢风险。 设置reduce个数时,优先设置参数:set hive.exec.reducers.max=3000; 尽量不要使用mapreduce.job.reduces。"
reducer数量的确定方法比mapper简单得多。使用参数mapred.reduce.tasks可以直接设定reducer数量,不像mapper一样是期望值。但如果不设这个参数的话,Hive就会自行推测,逻辑如下:
参数hive.exec.reducers.bytes.per.reducer用来设定每个reducer能够处理的最大数据量,默认值1G(1.2版本之前)或256M(1.2版本之后)。
参数hive.exec.reducers.max用来设定每个job的最大reducer数量,默认值999(1.2版本之前)或1009(1.2版本之后)。
得出reducer数:
reducer_num = MIN(total_input_size / reducers.bytes.per.reducer, reducers.max)。
reducer数量与输出文件的数量相关。如果reducer数太多,会产生大量小文件,对HDFS造成压力。如果reducer数太少,每个reducer要处理很多数据,容易拖慢运行时间或者造成OOM。
[Optimize Apache Hive with Apache Ambari in Azure HDInsight | Microsoft Learn]
大数据量的配置:
set hive.execution.engine=tez;
set tez.grouping.max-size=67108864;
set hive.tez.map.memory.mb=3072;
set hive.exec.reducers.max=3000;
set hive.tez.reduce.memory.mb=8192;
set hive.mapred.mode = 'nonstrict';
set mapreduce.task.timeout=60000000;
MapReduce优化
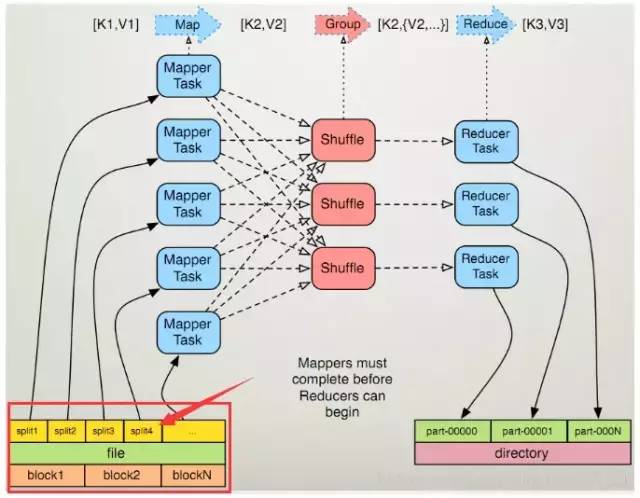
调整mapper数
mapper数量与输入文件的split数息息相关,在Hadoop源码org.apache.hadoop.mapreduce.lib.input.FileInputFormat类中可以看到split划分的具体逻辑。这里不贴代码,直接叙述mapper数是如何确定的。
- 可以直接通过参数
mapred.map.tasks(默认值2)来设定mapper数的期望值,但它不一定会生效,下面会提到。 - 设输入文件的总大小为
total_input_size。HDFS中,一个块的大小由参数dfs.block.size指定,默认值64MB或128MB。在默认情况下,mapper数就是:default_mapper_num = total_input_size / dfs.block.size。 - 参数
mapred.min.split.size(默认值1B)和mapred.max.split.size(默认值64MB)分别用来指定split的最小和最大大小。split大小和split数计算规则是:split_size = MAX(mapred.min.split.size, MIN(mapred.max.split.size, dfs.block.size));split_num = total_input_size / split_size。 - 得出mapper数:
mapper_num = MIN(split_num, MAX(default_num, mapred.map.tasks))。
可见,如果想减少mapper数,就适当调高mapred.min.split.size,split数就减少了。如果想增大mapper数,除了降低mapred.min.split.size之外,也可以调高mapred.map.tasks。
一般来讲,如果输入文件是少量大文件,就减少mapper数;如果输入文件是大量非小文件,就增大mapper数;至于大量小文件的情况,得参考下面“合并小文件”一节的方法处理。
调整reducer数
reducer数量的确定方法比mapper简单得多。使用参数mapred.reduce.tasks可以直接设定reducer数量,不像mapper一样是期望值。但如果不设这个参数的话,Hive就会自行推测,逻辑如下:
- 参数
hive.exec.reducers.bytes.per.reducer用来设定每个reducer能够处理的最大数据量,默认值1G(1.2版本之前)或256M(1.2版本之后)。 - 参数
hive.exec.reducers.max用来设定每个job的最大reducer数量,默认值999(1.2版本之前)或1009(1.2版本之后)。 - 得出reducer数:
reducer_num = MIN(total_input_size / reducers.bytes.per.reducer, reducers.max)。
reducer数量与输出文件的数量相关。如果reducer数太多,会产生大量小文件,对HDFS造成压力。如果reducer数太少,每个reducer要处理很多数据,容易拖慢运行时间或者造成OOM。
合并小文件
- 输入阶段合并 需要更改Hive的输入文件格式,即参数
hive.input.format,默认值是org.apache.hadoop.hive.ql.io.HiveInputFormat,我们改成org.apache.hadoop.hive.ql.io.CombineHiveInputFormat。 这样比起上面调整mapper数时,又会多出两个参数,分别是mapred.min.split.size.per.node和mapred.min.split.size.per.rack,含义是单节点和单机架上的最小split大小。如果发现有split大小小于这两个值(默认都是100MB),则会进行合并。具体逻辑可以参看Hive源码中的对应类。 - 输出阶段合并 直接将
hive.merge.mapfiles和hive.merge.mapredfiles都设为true即可,前者表示将map-only任务的输出合并,后者表示将map-reduce任务的输出合并。 另外,hive.merge.size.per.task可以指定每个task输出后合并文件大小的期望值,hive.merge.size.smallfiles.avgsize可以指定所有输出文件大小的均值阈值,默认值都是1GB。如果平均大小不足的话,就会另外启动一个任务来进行合并。
[Hive/HiveSQL常用优化方法全面总结 - 腾讯云开发者社区-腾讯云]
HIVE快捷查询:不启用Mapreduce job启用Fetch task
如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务。
启用MapReduce Job是会消耗系统开销的。
对于简单的不需要聚合的类似SELECT <col> from <table> LIMIT n语句,可以不需要起MapReduce job,直接通过Fetch task获取数据。在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
SET hive.fetch.task.conversion=none;
[HIVE快捷查询 SET hive.fetch.task.conversion=none; - 简书]
调优指南
| 调优项目 |
任务症状 |
调优方法 |
tez |
mr |
| Shuffle慢 |
任务运行波动大,怎样查看是否是因为shuffle导致。 |
对比两天实例,确认数据量差别不大的情况下,查看任务的平均Shuffle时间和max shuffle时间 PS: map task没有shuffle time,只有reduce task才有。 |
tasks:右边customize可以选择显示Task-REDUCE_INPUT_RECORDS和Task-SHUFFLE_PHASE_TIME |
1 Average Shuffle Time。 |
| vertex整体慢: task分批运行 |
container是task运行的容器。同时运行的container个数受两方面影响:同时运行的container上限(默认10000);资源不足,container满足缓慢。 |
1 对比两天实例,查看任务map任务start time的间隔。有两种情况: a) task个数超过同时运行:dag并发最大4万,vertex并发默认是1万。 b) 队列资源不足,可以通过kirk查看整体的资源情况。 |
tasks:右边customize可以选择显示Start Time |
entries里面:按Start Time排序 |
| Vertex运行慢:数据分布出现倾斜 |
tasks有少量(个别)出现跑得非常慢,其它大部分跑得快得多 |
1 task的运行时间进行排序,存在部分task运行非常慢 2. 查看运行非常慢task与正常的task各自的counter:INPUT_RECORDS,如果存在差异非常大,则是数据倾斜。 |
tasks:右边customize可以选择显示Task - REDUCE_INPUT_RECORDS |
Counters里面:Map input records和Reduce input records。 |
| 读view表时hql过滤条件优化 |
读view表时,某些过滤条件中pt过滤条件失效,拷贝全部pt数据。如下图: 检查HQL是否会读全部pt数据,可以使用explain extended + HQL语句,查看执行计划中返回的需要读取的分区信息。如: explain extended SELECT plat FROM dwb.dwb_flow_ordr_impr_i_d WHERE pt = '2021-05-12' AND page_sn = 10004 AND page_el_sn = 4936040 AND (plat = 'iOS' OR plat = 'Android'); |
目前发现的有以下几种情况:HQL写错;过滤条件中包含undeterministic UDF;视图下游将分区字段和view里计算出来的字段放在一个过滤条件;下游读view,下游sql中的过滤条件下推后与view中的过滤条件矛盾,出现了always false的条件。 一.HQL写错 通常时有多个过滤条件时,某一个过滤条件是用or连接,但是该过滤条件没有加括号。 二、过滤条件中包含undeterministic UDF 在这种情况下为了避免读取全部分区数据,可以将pt分区过滤条件与其他deterministic的过滤条件单独拿出来,与view表放在一起作为一个子查询,其他undeterministic的过滤条件放在子查询外面。e.g.会读全部pt分区的hql写法: select * from t where pt = '***' and time >= unix_timestamp('***', 'yyyy-MM-dd'); (unix_timestamp为undeterministic UDF)修改为以下hql,可以避免读取全部pt数据: select * from ( select * from t where pt = '***')t1 where time >= unix_timestamp('***', 'yyyy-MM-dd'); 三、视图下游将分区字段和view里计算出来的字段放在一个过滤条件 建议用户不要在代数运算之后的列添加过滤/分区裁剪条件 四、下游读view,下游sql中的过滤条件下推后与view中的过滤条件矛盾,出现了always false的条件。 e.g. CREATE VIEW test_view as select a, b from test_table where a = 'hello'; // 下游任务 select * from test_view where a = 'world' and pt = '2222'; 下游任务中的过滤条件下推到view之后,sql相当于 select a, b from test_table where a = 'hello' and a = 'world' and pt = '2222'; |