1.hive是什么?
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
2.Hive的三种模式
数据库:access,virtutal fox,sqlserver,mysql,sqlite,postgresql,oracle;
Local模式.此模式连接到一个In-Memory的数据库Derby,一般用于UnitTest.
单用户模式.通过网络连接到一个数据库中,是最常使用到的模式.
多用户模式:远程服务器模式.用于非java客户端访问元数据库(metastore),在服务器端启动metaStoreServer,客户端利用thrift协议通过metaStoreServer访问元数据库
3.hive的组成部分
Metastore:元数据的存储;元数据(数据库和表结构,列);mysql中
一个文件:除了文件内容以外的叫做元数据;(放到了namenode上)
Cli:client:客户端;hive的黑窗口
Jdbc:连接的
Webgui:
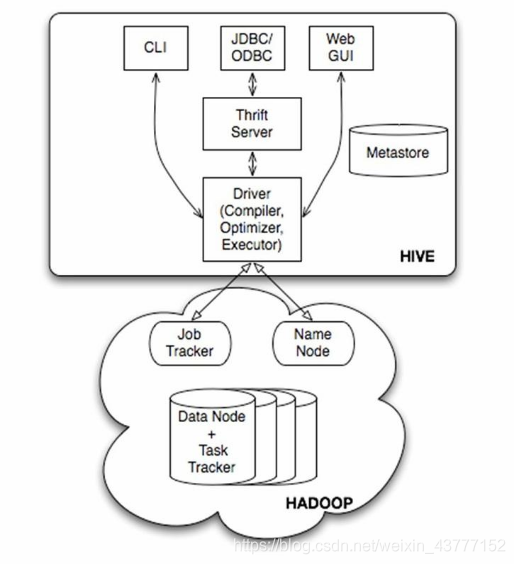
用户接口主要有三个:Cli,jdbc和WebGUI,其中最常用的是cli,cli启动的时候会同时启动一个hive副本,client是hive客户端,用户连接到hiveServer.在启动client模式的时候,需要指出hiveServer所在的节点,并且在该节点启动hiveServer.WUI是通过浏览器也能访问Hive
Hive将元数据(数据库,表)存储在数据库表(真实的数据库,mysql)中,如mysql,derby.hive中元数据包含表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在的目录等.数据库(Mysql)中并不存储Hive的记录;
解释器,编译器,优化器完成sql查询语句从词法分析,语法分析,编译,优化以及查询计划的生成.生成的查询计划存储在hdfs中,并在随后由mapreduce调用执行.
Hive数据存储在hdfs中,大部分数据查询,计算由mapreduce完成(包含*的查询,比如select* from tbl不会生成mapreduce任务)
元数据(hive中看到的库,表)存储到真实的数据库(mysql);记录存储到了hdfs上; 经常使用的mysql:表,记录,库都存储到文件系统中(NTFS)
hive的客户端连接服务器走的是thrift协议;====http==https;传输的内容大小比较小;
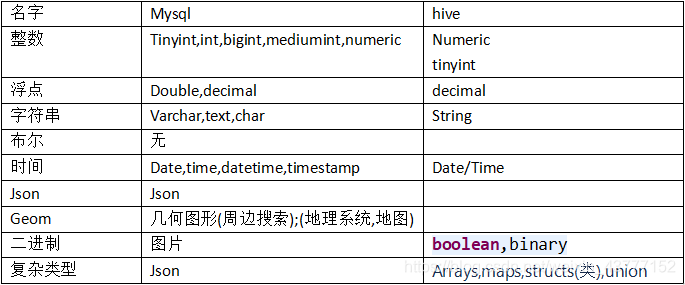
4.类型
5.CRUD
修改表名:
alter table 表名 rename to 新表名
# 修改列名
alter table change 列名 新列名 数据类型
# 添加新列,和替换列
alter table 表名
add columns
(
sex smallint,
updateTime timestamp
);
6.文件格式
mysql底层存储的文件格式
Ibd:表引擎是innerdb;默认是支持事务的;
Myd,myi,sdi:引擎是myism;不支持事务;
# 开启事务;
start transaction ;
# 可以写一堆的sql语句(更新操作,添加操作,删除操作);
#提交;确认木有问题,提交
Commit;
# 回滚;(撤销)
rollback
7.hive底层的文件格式
Avro:
ORC:
Parquet:目录结构(父子)
总结:
压缩比越高,越省空间(磁盘空间);但是解压和压缩的时候浪费了CPU+内存(机器性能),浪费了时间
压缩比越低或者不压缩;浪费空间,但是不需要解压和压缩,省了机器性能;
Load data命令只适用于表的文件格式是textFile;
如果表的格式为textFile,直接将txt上传到表指定的目录中,就可以直接查询出来;
可以先创建目录,上传文件,再创建表;
8.查看表结构
Desc 表名;
desc extended 表名 ;
desc formatted 表名;
9.创建表--as
10.创建表--like
# 使用like创建的表,目标表和源表的结构一样,木有数据;
11.Truncate
截断表:团灭;表里面的记录全部干掉;;直接删除文件
Delete;相当于删除文件中的某个内容;
12.创建类型复杂表
-- 地址;容器,泛型
address array<string>,
-- map爱好;容器,泛型
hobby map<string,string>,
-- 数组的拆分
collection items terminated by '-'
-- map
map keys terminated by ':'
数组的拆分和map的拆分,并木有指定是哪一列,是所有的数组都是用-拆分,所有的map都是用:拆分
Map:键值对,使用:隔开,多个键值对使用集合-;
13.分区
分区,分区的规则,指定列进行分区,分区的列不允许出现在小括号中;(分区可以有多个)
partitioned by (sex string,adress string)
14.窗口函数
-- 将查询出的语句,对记录的内容发生了变化
-- 查询的结果,要分组;(partition);
-- 这一列的值,lead:往下;当前行的值,请填写下一行;
-- lag:默认往前走一个,数字可以指定;
select *,lag(name,2) over (partition by dynastyId) from a_king ;
Over:条件;拿着当前执行的sql语句执行结果拍一张照片;在这些结果上进行处理;
分析函数
-- 需求
-- select dynastyId,count(*) from a_king group by dynastyId ;
-- row_number:查询的结果,进行分组;对每一组的结果进行编号;
select *, row_number() over (partition by dynastyId) from a_king ;
-- 每一个朝代,只列出前两个皇上;(topn)
select * from (select *, row_number() over (partition by dynastyId) as bh from a_king ) t
where bh < 3 ;
select *, row_number() over (partition by dynastyId order by id desc ) as bh from a_king
15.特殊的查询
Grouping sets;
Cubes:(立方体)
Rollups:(筒)
Grouping__ID function
对于每一列,如果该列已在该行中聚合,则为结果集中的一行生成“1”值,否则值为“0”
当我们没有统计某一列时,它的值显示为null,这可能与列本身就有null值冲突,这就需要一种方法区分是没有统计还是值本来就是null。(写一个排列组合的算法,就马上理解了,grouping_id其实就是所统计各列二进制和)
假设表里面有三列;a,b,c;在写sql语句统计的时候,只统计了a,b;group by a , b;c这一列木有管,在hive中c这一列的值为null;
问题:c本身就是nu ll值(hive统计的时候变成Null值,不是对的);c它原来有值,直接就变成了null值,这不公平;相当于把原来的数据给覆盖掉;
16.Udf-udtf-udaf
UDF:User Defined Function;(用户自定义函数);常见的函数
UDAF:User Defined Aggregate(聚合) Functions:count,sum,avg;输入的数据是多条的,输出的数据是一条的;
UDTF:User Defined Table-Generating(表格生成) Functions ;输入是一条,输出是多条;
如果要执行多个sql语句咋办?将多个sql语句写到一个sql文件中
bin/hive -f '/root/demo.sql'
-S:不把sql语句执行的结果输出出来;
# 执行hdfs上面的sql文件;
bin/hive -f hdfs://jh/hw/hive_sql.sql
hive(ETL提取转化加载)优化:
一、hql语句优化:
1.strict mode
严格查询开启后,会限制3个查询:
1.分区查询,不加分区字段过滤条件,不能执行
2.limit
3.order by:不使用limit语句,不能执行
4.限制笛卡尔积的查询,不使用where时,join用on
2.要学会看explain 和 explain extended,后者会额外打印出hql的抽象语法树
解析器要做的事情就是将hql语句变成抽象语法树
一个stage是一个mapreduce任务,一个任务可以有多个map和reduce
一个hql语句包含有一个或多个stage,多个stage之间是相互依赖的,
hive默认只执行一个stage,也可以设置无依赖的并行运行
3.limit性能调优:
是否开启使用limit优化
4.join优化:
1.永远是小表驱动大表
2.join笛卡尔积查询时,尽量加where过滤(严格模式必加)
3.分区表查询时,where条件中加上分区字段过滤
5.group by:分组。一般和聚合函数搭配使用
having是对结果集进一步的过滤
order by:全局排序
sort by:局部排序
6.distinct:去重
7.union all:将多个结果集连接在一起,不去重排序
union:将多个结果集连接在一起,去重排序
8.job个数优化:
hive 默认一个查询或子查询或 group by 等语句生成一个 job
job 数量尽量少
9.尽量少排序:
排序操作会消耗较多的 CPU,会影响 sql 的响应时间
10.尽量避免 select *:
用什么字段取什么字段,减少不必要的资源浪费
11.尽量用 join 代替子查询:
虽然 join 性能并不佳,但比起 mysql 的子查询好的多
12.优先优化高并发的 sql,而不是执行频率低的“大”sql:
对于破坏性来说,高并发的 sql 总是会比低频率的来的快,它不会给任何喘息机会就会把系统击垮,
而频率低的,至少会给我们缓冲的机会
13.从全局出发优化,而不是片面调整:
sql 优化不能单独针对某一个进行,要考虑所有的 sql
14.尽量少 or:
当 where 子句中存在多个条件以或并存时,mysql 优化器也没有很好的解决其执行计划问题,
必要时用 union all 或 union 代替
15.永远为每张表设置ID:
设置 ID 为主键,最好是int型的,并设置自动增加的 auto_increment 标志
16.多配置几台服务器
二、mapreduce优化:
17.本地模式:
hive运行模式就需要mr,mr分为韦分布式,单机版,分布式
也有一个本地模式:开启本地模式计算,more是128m;允许输入的最大模式文件数量是4
18.并行执行:
开启并行执行job,在job之间没有依赖关系时可以同时执行,并行数另设置,并行执行的最大线程数是8,
开启并行会消耗更多的集群资源来提高执行速度,对特定作业并行执行合适
19.mapreducer的数量:
靠合并小文件减少map的数量;
设置属性,减少分片数,当单个文件很大时,适当增加map的数量
设置reduce的个数,如果不控制,会根据map阶段的输出数据大小来确定它的个数
20、合并小文件:
文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,从而影响处理效率。
对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
21.jvm的重用:
默认运行1个task,默认jvm的任务数也是1个
三、数据倾斜:
表现:任务进度长时间维持在99%或100%,查看任务监控页面,发现只有少量(1个或2个)
reduce子任务未完成,因为它处理的数据量和其他的差异过大
1.由于key分布不均匀造成hql语句过长
解决方式:将key分布开计算再合并
2.group by 很容易造成数据倾斜:
#是否开启对group by查询时出现数据倾斜进行优化
hive.groupby.skewindata=flase;
#是否开启group by 使用map端的join优化
hive.map.aggr=true;
3.空值产生的数据倾斜:
解决方法:赋予空值分新的key值
4.不同数据类型关联产生数据倾斜:
解决方法:把数字类型转换成字符串类型
5.表格中出现null值时,建表时加is not null
四、数据方面:
1.hive默认是内部表,删除时会删除元数据和hdfs上的数据内容
删除外部表只会删除元数据
2.分区是为了避免hive暴力扫描大表查询
分区字段不在元数据中存在,真实数据也不在hdfs中存在
将大表分散到多个小表中,提高查询效率
3.分区使用表外字段(paritioned by),分桶使用表内字段(clustered by)
分区分桶都是为了将大数据分散到多个文件中
4.分区裁剪:可以查询的过程中减少不必要的分区。
5. hive的储存和压缩:储存格式一般用orcfile / parquet;压缩用‘ SNAPPY ’;
建表之前设置压缩格式:set parquet.compression=SNAPPY;
建表过程中设置文件格式和压缩格式:stored as orc tblproperties('orc.compression'='SNAPPY')