BeautifulSoup库使用解析
一、前言
BeautifulSoup是一个html文档解析库,在爬虫解析数据时,十分有用。接下来记录下它的用法。
二、准备工作
引入库
- from bs4 import BeautifulSoup
创建beautifulSoup对象
- 通过文件,创建beautifulSoup对象
file = open("./Test.html",encoding="utf-8")
soup = BeautifulSoup(file,"html.parser")
- 通过文本内容, 创建BeautifulSoup对象
content = '''
<!DOCTYPE html>
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type" />
<meta content="IE=Edge" http-equiv="X-UA-Compatible" />
<meta content="always" name="referrer" />
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css" />
<title attr1="val1" attr2="val2">百度一下,你就知道 </title>
<ha attr1="val1" attr2="val2"><!--我是注释里的内容--></ha>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品 </a>
</div>
</div>
</div>
</div>
</body>
</html>
'''
soup = BeautifulSoup(content,"html.parser")
这种比较常用,不过实际使用时,content会替换为网页实时抓取到的文本内容。
接下来我们就以上面这段文本作为数据源来说明,下面的所有方法都基于这段文本的解析
三、类型
- BeautifulSoup
- Tag
- NavigableString
- Comment
BeautifulSoup类型
我们刚刚创建出来的soup对象,即是BeautifulSoup类型。可以打印一下
print(type(soup))
输出:<class 'bs4.BeautifulSoup'>
Tag类型
Tag类型是一个很重要的类型,那什么是Tag呢,就是类似于xml里一个标签,如下图
<div id="u1"> <!-- 这是一个Tag-->
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a> <!--这也是一个Tag-->
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a> <!--俺也一样-->
</div>
Tag可分为name,attrs,string 三部分。结构如图
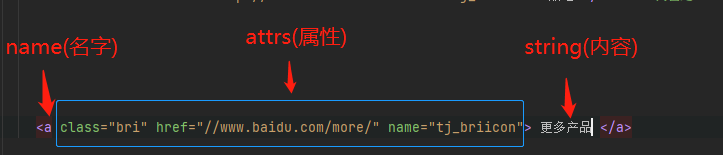
#获得找到的第一个名字为a的标签
print(soup.a)
#结果: <a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
#打印名字
print(soup.a.name)
#结果:a
#打印属性
print(soup.a.attrs)
#结果:{'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
#打印内容
print(soup.a.string)
#结果:新闻
NavigableString 和 Comment类型
这两个其实都是Tag的string内容。区别点在于,如果内容全注释着,就是Comment类型;否则就是NavigableString类型
<title attr1="val1" attr2="val2">百度一下,你就知道 </title> <!--这里的string是NavigableString类型-->
<ha attr1="val1" attr2="val2"><!--我是注释里的内容--></ha> <!--这里的string是Comment类型-->
print(type(soup.title.string))
#结果:<class 'bs4.element.NavigableString'>
print(type(soup.ha.string))
#结果:<class 'bs4.element.Comment'>
print(soup.title.string)
#结果:百度一下,你就知道
print(soup.ha.string)
#结果:我是注释里的内容
#注意上面这里直接获得了注释里的内容
四、遍历
我们可以用根据标签的名字来获得标签。
- 比如根据我们上面的html内容,可以这样来获得标签
- soup.head 获得head
- soup.head.title 获得tag
但是如果想遍历,则需要用其他的方法。接下来我们来看看有什么方法
遍历直属子节点
contents
- 用contents返回直属子节点,list类型
for item in soup.head.contents:
print(item.name)
'''
结果:
None
meta
None
meta
None
meta
None
link
None
title
None
ha
None
'''
可以看到子标签都打印出来了(其中会夹着一些none节点)
children
- 用children返回直属子节点,listiterator 迭代器类型
效果和contents差不多,只是返回的类型不一样
遍历所有子节点
descendants
前面的content和children获取到的直属子节点,不能获得孙子节点。而descendants可以获取到所有子节点
for item in soup.body.descendants:
print(item.name)
遍历父节点
- parent 获得父节点
- parents 获得所有父节点
遍历兄弟节点
-
next_sibling 下一个弟节点
-
next_siblings 位于自己下面的所有弟节点
-
previous_sibling 上一个兄节点
-
previous_siblings 位于自己上面的兄节点
前后遍历
不同于兄弟节点的遍历,这里的前后遍历可以达到子节点。从根节点往后遍历,可以到达所有节点.
- next_element 下一个节点
- next_elements 所有位于自己下面的节点
- previous_element 上一个节点
- previous_elements 所有位于自己上面的节点
五、搜索
find_all()
- 指定关键字查找
指定name
#查找 name=“a” 的所有标签
alla = soup.find_all(name="a")
for a in alla:
print(a)
结果
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
上面也可以写成soup.find_all("a”),不指定关键字默认是以name来作为条件
指定text
allItem = soup.find_all(text="新闻 ")
for item in allItem:
print(item)
结果
新闻
注意这里找出来的都是string,不是Tag
指定属性
除了name,text,attrs等关键词外,其他的代表属性。比如
allItem = soup.find_all(href="//www.baidu.com/more/")
for item in allItem:
print(item)
结果
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
如果属性和python关键字重合,比如class,需要加下划线_,比如
allItem = soup.find_all(class_="mnav")
for item in allItem:
print(item)
结果
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
可以加多个条件,比如
allItem = soup.find_all(class_="mnav",href="http://news.baidu.com",name="a")
for item in allItem:
print(item)
结果
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
指定列表
list = {
"mnav","bri"}
allItem = soup.find_all(class_=list)
for item in allItem:
print(item)
结果
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
指定正则表达式
allItem = soup.find_all(href =re.compile("www."))
for item in allItem:
print(item)
结果
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css"/>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
指定方法
指定方法,可以传入一个方法作为参数,但这个方法需要带Tag作为参数。比如:
def has_attr_name(tag):
return tag.has_attr('name')
allItem = soup.find_all(has_attr_name)
for item in allItem:
print(item)
结果
<meta content="always" name="referrer"/>
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻 </a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123 </a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图 </a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频 </a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧 </a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon"> 更多产品 </a>
search()
BeautifulSoup还可以用search()来搜索,不过由于自己刚使用BeautifulSoup不久,目前多以find_all()来完成搜索,这个不太熟. 就不写了…