这是ECCV18的一篇文章。 论文地址, 项目地址。
该论文主要提出了一种动作-评价网络结构,利用深度强化学习的思想直接得出跟踪结果的action,强化学习 actor-critic模型可以先了解一下,有不对的地方欢迎讨论~
1.主要贡献
利用深度强化学习的思想在之前cvpr的EAST跟踪器中就有应用,这里同样利用这个思想。
贡献一:首次尝试用动作网络去探索连续的跟踪动作结果,因为一般的强化学习输出的action是有限的而跟踪的action是连续无限的,跟踪也能看作一个动态的搜索action的行为;
贡献二:作者提出的动作-评价网络也用于提高跟踪的鲁棒性,而不是仅仅用强化学习中的Q-learning来学出一个不错的action,此外还改进了深度判别策略的梯度算法。

2.方法
2.1 建模
根据强化学习的思想,有三个主要元素,状态,动作和回报。
状态:
状态s就是f跟踪的目标框内的patch,根据每一帧得到的目标的位置(x,y)和大小(w,h)信息来从图像中crop下来。
动作:
动作a是一个目标的相对移动的三元组,
,第三个代表尺度的相对变化,因为是相对的所有前两张变化在-1和1之间,第三个设定为-0.05和0.05之间,这样根据a和s可以得到新的目标信息b’如下
作者直接尝试用动作网络模型根据s得出最优的a,即
,
代表动作网络模型,
代表该网络的参数。
回报:
回报r描述了动作a的准确性,如果a得到的新的目标和groundtruth的交并比大于0.7则r为1.否则为-1,这样在线下学习中可以使网络去学习更好的决策,只是这里的定义比EAST还是简单了一点,有改进的空间。
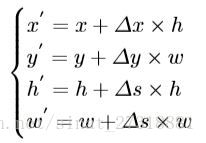
2.2 离线训练
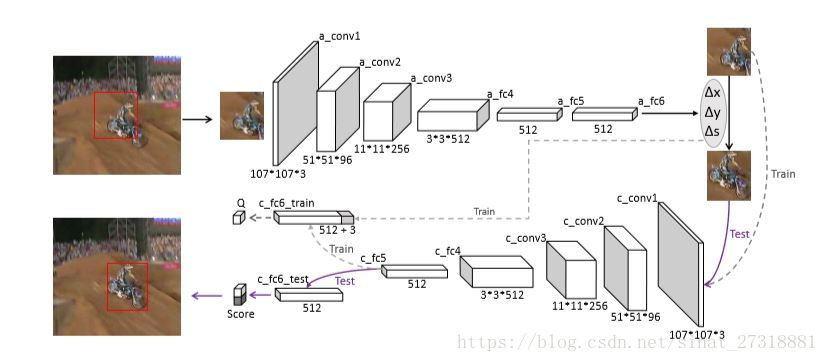
网络结构
作者使用了轻量级的深度网络VGG-M预训练好的模型作为文中动作-评价网络的初始模型,具体形式如下图
可以看到评价网络和动作网络有相同的结构除了最后一层全连接层,评价网络的最后一层根据预测的动作三维向量和第五层全连接层串联起来得到的,最后得到一个Q值,用于评价当前状态下预测的动作。
DDPG训练
DDPG的核心思想是迭代更新动作网络和评价网络模型,给定从T帧中随机取的N组
,评价模型Q(s,a)通过强化学习中的贝尔曼公式得到,利用目标网络
和
m,最小化下式
y值是由预测动作的回报和折扣的目标Q值得到
。然后动作模型根据链式法则反向更新
训练迭代的时候随机取出训练集的一段序列帧和对应的goundtruth,第t帧的训练组就可以得到(s_t,a_t,r_t,s_t’)。在探索动作时有一个随机探索的概率用于增强鲁棒性,然后迭代更新评价网络和动作网络。
具体伪代码如下:
训练过程的改进
改进的原因是动作空间的广泛性,因此需要缩小搜索空间。
因为在那么多动作中找到一个正回报的动作概率太小,所有利用初始帧的监督信息来初始化动作网络,即最小化二范损失来fine-tune,因为初始目标信息已知,所以标准动作是可以计算的。
第二点是为了解决正负样本的比例不均衡问题,因此使用了专家决策来指导学习的过程,传统DDPG算法的
概率动作探索是加上噪声进行随机探索,而这里以
的概率用专家决策代替动作模型的输出,随着训练过程的进行,概率逐渐降低。
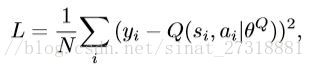
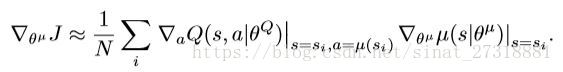

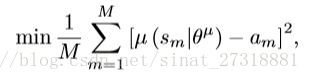
2.3在线跟踪
初始化
使用初始帧的groundtruth初始化动作-评价网络,根据gt在周围选出M个候选目标框再计算对应的action,然后corp出M块patch即state,然后使用上面说过的二范loss进行fine-tune,在线跟踪的时候评价网络就成了二分类网络,即输出前景和背景的概率,初始化设计了一个标签l,对M个候选框,和gt计算交并比大于0.7时l为1否则为0,这样得到M个图像标签对{
},然后使用Adam优化方法优化下面这个loss
目的很显然,使正样本的前景概率和负样本的背景概率之和最大。
跟踪
首先根据上一帧给出的a在当前帧提取s,即图像块,然后输入动作网络得到a,然后就得到了新的预测目标信息和当前帧新的状态s’,然后输入评价网络,如果最后得分大于0,则认为结果a是可靠的,否则进行重检测,即在其周围取M个候选区域输入评价网络,选择得分最高的作为最后结果。
更新
由于实验中动作网络更可靠所以仅仅必要时更新评价网络,当某次的验证得分小于0,则认为网络不可靠了,然后使用前10帧的正负样本更新网络,和初始化评价网络的方法一样。
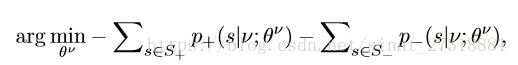
3.实验
3.1实验细节
训练时随机样本的选择按照以目标为中心生成高斯分布的样本。
离线训练使用了ImageNet Video的768个视频数据,随机选择了20到40个连续帧。
专家决策概率初始设置为0.5,每一万次迭代更新一次网络,一共进行了25万次迭代。
在线跟踪时选择了初始帧的500正样本和5000负样本初始化,只用其中的正样本来训练动作网络。
重检测更新评价网络时选了前面成功的帧里50正样本和150负样本。
3.2实验结果
代码使用了python和pytorch框架。
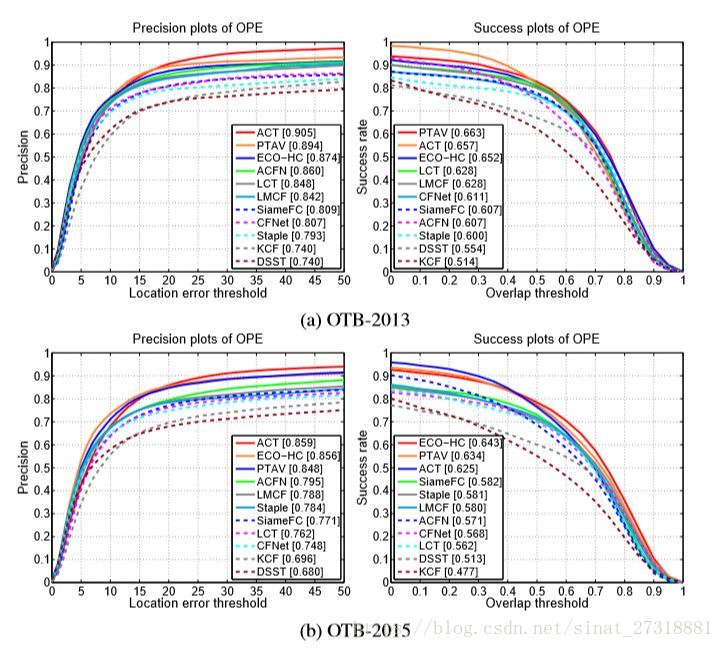
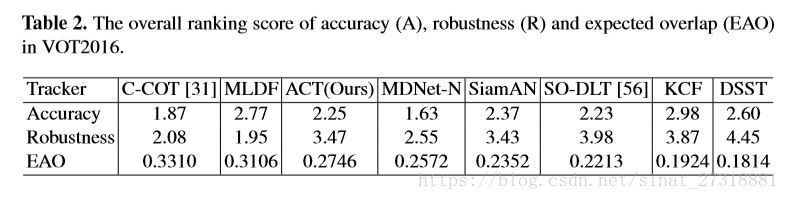
结果上在OTB13上超过ECO-HC了但是15上差2%,还是比较难的,但是方法本身还是有很多改进的地方的,VOT16的结果还算可以,这也是深度跟踪的优势数据集,速度方面报告为30fps。还算不错。