版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u010598445/article/details/52793592
Abstract
一个结合梯度特征HOG及颜色特征的实时跟踪算法,速度达到80FPS,即每秒80帧图像。
Introduction
Staple: Sum of Template And Pixel-wise LEarners
对于目前的主流跟踪算法,采用的tracking-by-detection策略,即先检测目标的位置,以HOG检测为例 ,对同一个目标,可能得到多个目标的矩形框,如下图所示。有的时候直接通过NMS(non-maximum suppression 非极大值抑制)处理保证只有一个解。不过多数跟踪算法宁可错杀,也不愿放过一个。HOG Object Detection 可以参考 Histogram of Oriented Gradients and Object Detection

Related Work
- Online learning and Correlation Filters:在线学习+协同过滤
- Robustness to deformation:应对形变
- Schemes to reduce model drift:应对漂移问题
- Combining multiple estimates:结合多种估计
- Long-term tracking with re-detection:长期跟踪及重复检测
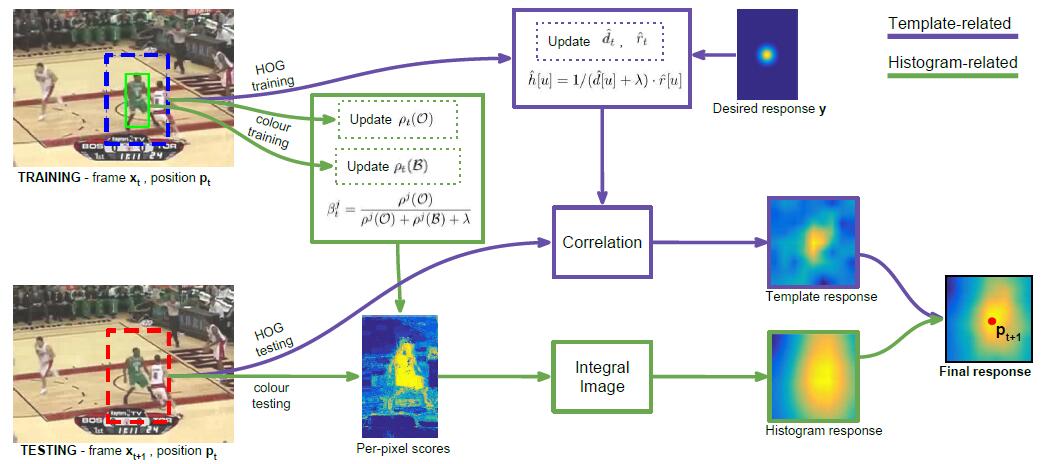
Proposed Approach
符号及含义
-
t frame index, 帧索引,帧下标 -
xt 第t帧图像,x 指代任意一帧图像 -
pt 第t帧图像中目标对应的矩形,当然,这个是最优的,p 指代任意一帧图像 -
St 第t帧图像中目标对应的所有矩形,所以我们有pt=argmaxp∈Stf(T(xt,p);θt−1) -
f(T(x,p);θ) 依据模型参数θ ,计算得到目标在图像x 对应矩形p 的分数(score)。这个分数当然是越高越好,所以选择取最大分数时的矩形p 作为最优的矩形pt 。对于T(x,p) 可以暂时肤浅地理解为检测出来的梯度特征与颜色特征。同样参数θ 也可以暂时肤浅地理解为预测的梯度特征与颜色特征。然后f(T(x,p);θ) 求预测特征与检测特征之间的匹配的情况,匹配分数越高,就越可能对应实际的目标矩形pt 。 -
θ 模型参数θ 可以通过损失最小化求出,设损失函数为L(θ;Xt) ,在这里Xt={(xi,pi}ti=1 并不是帧的集合{x1,x2,...,xt} ,而是{(x1,p1),(x2,p2),...,(xt,pt)} ,这样包含之前每一帧中目标的位置。对参数的复杂度加以惩罚,最终得到:θt=argminθ∈Ω{L(θ;Xt)+λR(θ)} -
f(x) 回到对p 进行打分的函数,前面提到要结合梯度特征与颜色特征,考虑算法的实时性,当然用线性方式结合速度快,这样有f(x)=ctmplftmpl(x)+chistfhist(x)
抱歉这里的x 理应对应T(x,p);θ ,但原文中就是这么用的。tmpl 就是template(梯度特征),hist就是histogram(颜色直方图特征) -
ftmpl(x;h) 考虑梯度特征的打分函数,这里 与T 以及前面的函数T(xt,p) 应该没有任何联系。∈ℤ2 为有限的网格(finite grid),可以理解为图像中一像素的位置坐标(x,y)。T 应该为向量的转置。这里h为模型参数,ϕx 为图像梯度特征。这样,对于每一点,我们有:ftmpl(x;h)=∑u∈h[u]Tϕx[u] -
fhist(x;β) 考虑颜色特征的打分函数,有一点点不同,在这里,β 同样是模型参数, 也同样是有限的网格(finite grid)fhist(x;β)=βT(1∣∣∑u∈ψx[u]) -
θ 参数θ=(h,β) -
L(θ,XT) 损失函数=∑Tt=1wtl(xt,pt,θ) ,这里每帧的损失函数l(x,p,θ)=cost(p,argmaxq∈Sf(T(x,q);θ)) ,在这里,p 自然是正确的矩形。 - 然后得到参数的解:
ht=argminh{Ltmpl(h;Xt)+12λtmpl∥h∥2} βt=argminβ{Lhist(β;Xt)+12λhist∥β∥2}
Online least-squares optimisation
上面仅仅介绍了原文的前10个公式,原文一共26个公式,就不一一介绍了。接下来主要讲大概。
这一小节通过梯度下降求解损失函数
Learning the template score
再次梯度下降求
Learning the histogram score
还是梯度下降求
Search strategy
本文假设矩形窗口