文章目录
二叉树和队列、链表等一样,都是常用的数据结构。前面我们介绍数组的数据结构,我们知道对于有序数组,查找很快,并介绍可以通过二分法查找,但是想要在有序数组中插入一个数据项,就必须先找到插入数据项的位置,然后将所有插入位置后面的数据项全部向后移动一位,来给新数据腾出空间,平均来讲要移动N/2次,这是很费时的。同理,删除数据也是。但是二叉树的出现很好地解决了这些问题。
一、什么是树结构
树(tree)是一种抽象数据类型(ADT),用来模拟具有树状结构性质的数据集合。它是由n(n>0)个有限节点通过连接它们的边组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
1、节点:上图的圆圈,比如A,B,C等都是表示节点。节点一般代表一些实体,在java面向对象编程中,节点一般代表对象。
2、边:连接节点的线称为边,边表示节点的关联关系。一般从一个节点到另一个节点的唯一方法就是沿着一条顺着有边的道路前进。在Java当中通常表示引用。
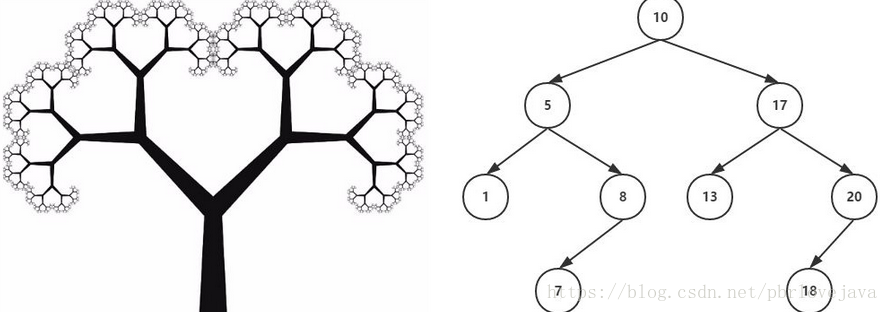
二、树的常用术语
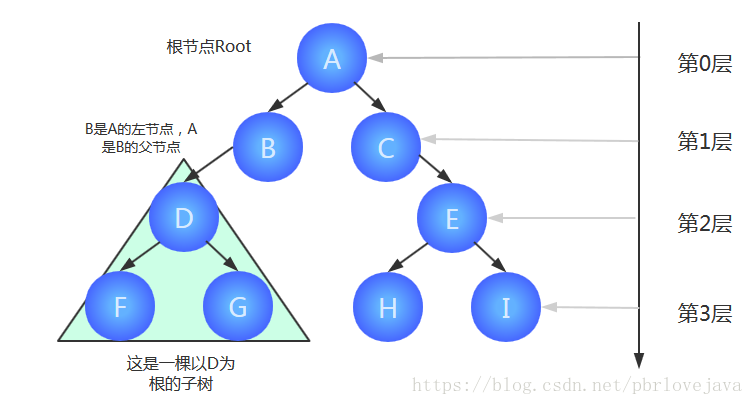
1、路径:顺着节点的边从一个节点走到另一个节点,所经过的节点的顺序排列就称为“路径”。
2、根:树顶端的节点称为根。一棵树只有一个根,如果要把一个节点和边的集合称为树,那么从根到其他任何一个节点都必须有且只有一条路径。A是根节点。
3、父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;B是D的父节点。
4、子节点:一个节点含有的子树的根节点称为该节点的子节点;D是B的子节点。
5、兄弟节点:具有相同父节点的节点互称为兄弟节点;比如上图的D和E就互称为兄弟节点。
6、叶节点:没有子节点的节点称为叶节点,也叫叶子节点,比如上图的A、E、F、G都是叶子节点。
7、子树:每个节点都可以作为子树的根,它和它所有的子节点、子节点的子节点等都包含在子树中。
8、节点的层次:从根开始定义,根为第一层,根的子节点为第二层,以此类推。
9、深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为0;
10、高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0;
三、二叉树
二叉树:树的每个节点最多只能有两个子节点
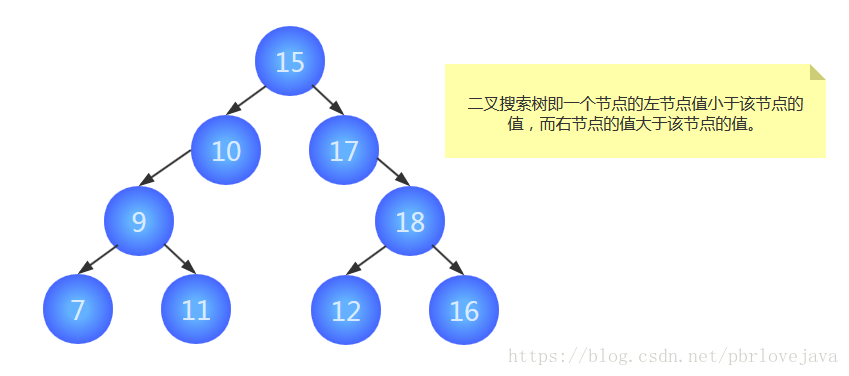
如果我们给二叉树加一个额外的条件,就可以得到一种被称作二叉搜索树(binary search tree)的特殊二叉树。
二叉搜索树要求:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。
四、用Java实现二叉树
1、二叉树的节点类
public class Node {
private Object data; //节点数据
private Node leftChild; //左子节点的引用
private Node rightChild; //右子节点的引用
//打印节点内容
public void display(){
System.out.println(data);
}
2、二叉树方法接口
public interface Tree {
//查找节点
public Node find(Object key);
//插入新节点
public boolean insert(Object key);
//删除节点
public boolean delete(Object key);
//Other Method......
}
3、查找节点
查找某个节点,我们必须从根节点开始遍历。
1、查找值比当前节点值大,则搜索右子树;
2、查找值等于当前节点值,停止搜索(终止条件);
3、查找值小于当前节点值,则搜索左子树;
public Node find(int key) {
Node current = root;
while(current != null){
if(current.data > key){//当前值比查找值大,搜索左子树
current = current.leftChild;
}else if(current.data < key){//当前值比查找值小,搜索右子树
current = current.rightChild;
}else{
return current;
}
}
return null;//遍历完整个树没找到,返回null
}
说明:用变量current来保存当前查找的节点,参数key是要查找的值,刚开始查找将根节点赋值到current。接在在while循环中,将要查找的值和current保存的节点进行对比。如果key小于当前节点,则搜索当前节点的左子节点,如果大于,则搜索右子节点,如果等于,则直接返回节点信息。当整个树遍历完全,即current == null,那么说明没找到查找值,返回null。
查找操作的时间复杂度:查找节点的时间取决于这个节点所在的层数,每一层最多有2n-1个节点,总共N层共有2n-1个节点,那么时间复杂度为O(logn),底数为2,这个复杂度和用二分法查找有序数组时的效率一样。
4、插入节点
要插入节点,必须先找到插入的位置。与查找操作相似,由于二叉搜索树的特殊性,待插入的节点也需要从根节点开始进行比较,小于根节点则与根节点左子树比较,反之则与右子树比较,直到左子树为空或右子树为空,则插入到相应为空的位置,在比较的过程中要注意保存父节点的信息 及 待插入的位置是父节点的左子树还是右子树,才能插入到正确的位置。
public boolean insert(int data) {
Node newNode = new Node(data);
if(root == null){//当前树为空树,没有任何节点
root = newNode;
return true;
}else{
Node current = root;
Node parentNode = null;
while(current != null){
parentNode = current;
if(current.data > data){//当前值比插入值大,搜索左子节点
current = current.leftChild;
if(current == null){//左子节点为空,直接将新值插入到该节点
parentNode.leftChild = newNode;
return true;
}
}else{
current = current.rightChild;
if(current == null){//右子节点为空,直接将新值插入到该节点
parentNode.rightChild = newNode;
return true;
}
}
}
}
return false;
}
5、遍历树
遍历树是根据一种特定的顺序访问树的每一个节点。比较常用的有前序遍历,中序遍历和后序遍历。而二叉搜索树最常用的是中序遍历。
1、中序遍历:左子树->根节点->右子树
2、前序遍历:根节点->左子树->右子树
3、后序遍历:左子树->右子树->根节点
//中序遍历
public void infixOrder(Node current){
if(current != null){
infixOrder(current.leftChild);
System.out.print(current.data+" ");
infixOrder(current.rightChild);
}
}
//前序遍历
public void preOrder(Node current){
if(current != null){
System.out.print(current.data+" ");
preOrder(current.leftChild);
preOrder(current.rightChild);
}
}
//后序遍历
public void postOrder(Node current){
if(current != null){
postOrder(current.leftChild);
postOrder(current.rightChild);
System.out.print(current.data+" ");
}
}
6、查找最大值和最小值
要找最小值,先找根的左节点,然后一直找这个左节点的左节点,直到找到没有左节点的节点,那么这个节点就是最小值。同理要找最大值,一直找根节点的右节点,直到没有右节点,则就是最大值。
//找到最大值
public Node findMax(){
Node current = root;
Node maxNode = current;
while(current != null){
maxNode = current;
current = current.rightChild;
}
return maxNode;
}
//找到最小值
public Node findMin(){
Node current = root;
Node minNode = current;
while(current != null){
minNode = current;
current = current.leftChild;
}
return minNode;
}
7、删除节点
删除节点是二叉搜索树中最复杂的操作,删除的节点有三种情况,前两种比较简单,但是第三种却很复杂。
1、该节点是叶节点(没有子节点)
2、该节点有一个子节点
3、该节点有两个子节点
下面我们分别对这三种情况进行讲解。
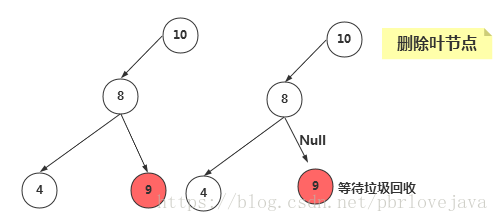
1、删除没有子节点的节点
要删除叶节点,只需要改变该节点的父节点引用该节点的值,即将其引用改为 null 即可。要删除的节点依然存在,但是它已经不是树的一部分了,由于Java语言的垃圾回收机制,我们不需要非得把节点本身删掉,一旦Java意识到程序不在与该节点有关联,就会自动把它清理出存储器。
@Override
public boolean delete(int key) {
Node current = root;
Node parent = root;
boolean isLeftChild = false;
//查找删除值,找不到直接返回false
while(current.data != key){
parent = current;
if(current.data > key){
isLeftChild = true;
current = current.leftChild;
}else{
isLeftChild = false;
current = current.rightChild;
}
if(current == null){
return false;
}
}
//如果当前节点没有子节点
if(current.leftChild == null && current.rightChild == null){
if(current == root){
root = null;
}else if(isLeftChild){
parent.leftChild = null;
}else{
parent.rightChild = null;
}
return true;
}
return false;
}
删除节点,我们要先找到该节点,并记录该节点的父节点。在检查该节点是否有子节点。如果没有子节点,接着检查其是否是根节点,如果是根节点,只需要将其设置为null即可。如果不是根节点,是叶节点,那么断开父节点和其的 关系即可。
2、删除有一个子节点的节点
删除有一个子节点的节点,我们只需要将其父节点原本指向该节点的引用,改为指向该节点的子节点即可。
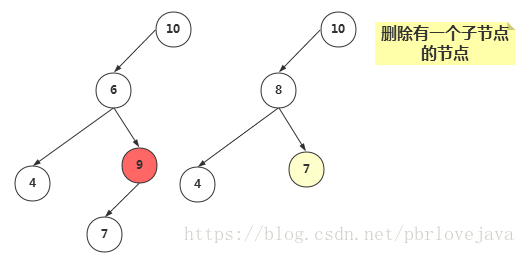
//当前节点有一个子节点
if(current.leftChild == null && current.rightChild != null){
if(current == root){
root = current.rightChild;
}else if(isLeftChild){
parent.leftChild = current.rightChild;
}else{
parent.rightChild = current.rightChild;
}
return true;
}else{
//current.leftChild != null && current.rightChild == null
if(current == root){
root = current.leftChild;
}else if(isLeftChild){
parent.leftChild = current.leftChild;
}else{
parent.rightChild = current.leftChild;
}
return true;
}
五、二叉树的效率
从前面的大部分对树的操作来看,都需要从根节点到下一层一层的查找。
一颗满树,每层节点数大概为2n-1,那么最底层的节点个数比树的其它节点数多1,因此,查找、插入或删除节点的操作大约有一半都需要找到底层的节点,另外四分之一的节点在倒数第二层,依次类推。
总共N层共有2n-1个节点,那么时间复杂度为O(logn),底数为2。
在有1000000 个数据项的无序数组和链表中,查找数据项平均会比较500000 次,但是在有1000000个节点的二叉树中,只需要20次或更少的比较即可。
有序数组可以很快的找到数据项,但是插入数据项的平均需要移动 500000 次数据项,在 1000000 个节点的二叉树中插入数据项需要20次或更少比较,在加上很短的时间来连接数据项。
同样,从 1000000 个数据项的数组中删除一个数据项平均需要移动 500000 个数据项,而在 1000000 个节点的二叉树中删除节点只需要20次或更少的次数来找到他,然后在花一点时间来找到它的后继节点,一点时间来断开节点以及连接后继节点。
所以,树对所有常用数据结构的操作都有很高的效率。
遍历可能不如其他操作快,但是在大型数据库中,遍历是很少使用的操作,它更常用于程序中的辅助算法来解析算术或其它表达式。
五、参考资料
1、YSOcean的博客 https://www.cnblogs.com/ysocean/p/8032642.html
2、二叉树百度百科 https://baijiahao.baidu.com/s?id=1583299413874922957&wfr=spider&for=pc
3、雨落川下雪的博客 https://www.cnblogs.com/feile/p/5391492.html