目录
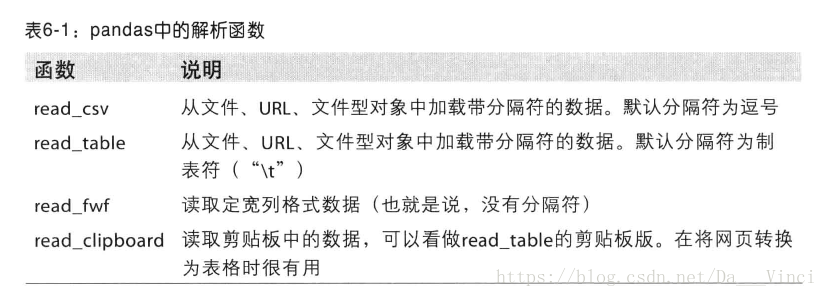
读写文本格式的数据
>>> import pandas as pd
Backend TkAgg is interactive backend. Turning interactive mode on.
>>> pd.read_csv('D:\python\DataAnalysis\data\\1.txt')
Empty DataFrame
Columns: [1, 2, 3, 4, 5, 6, 7]
Index: []
>>> pd.read_table('D:\python\DataAnalysis\data\\1.txt',sep=',')
Empty DataFrame
Columns: [1, 2, 3, 4, 5, 6, 7]
Index: []


逐块读取文本文件
>>> pd.read_csv('D:\python\DataAnalysis\data\\1.txt',nrows=5)
1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
3 1 2 3 4 5 6 7
4 1 2 3 4 5 6 7将数据写出到文本
>>> data = pd.read_csv('D:\python\DataAnalysis\data\\1.txt')
>>> data.to_csv('D:\python\DataAnalysis\data\\1.txt',na_rep='NULL',index=False,header=False,sep='|')
>>> data
1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
3 1 2 3 4 5 6 7
4 1 2 3 4 5 6 7
5 1 2 3 4 5 6 7
6 1 2 3 4 5 6 7
7 1 2 3 4 5 6 7
8 1 2 3 4 5 6 7手工处理分割符格式
>>> import csv
>>> f = open('D:\python\DataAnalysis\data\\new.csv')
>>> reader = csv.reader(f,delimiter=',')
>>> for line in reader:
... print line
...
["'a'", "'b'", "'c'"]
["'1'", "'2'", "'3'"]
["'1'", "'2'", "'3'", "'4'"]
>>> lines = list(csv.reader(open('D:\python\DataAnalysis\data\\new.csv')))
>>> header,values = lines[0],lines[1:]
>>> data_dict = {h:v for h,v in zip(header,zip(*values))}
>>> data_dict
{"'a'": ("'1'", "'1'"), "'b'": ("'2'", "'2'"), "'c'": ("'3'", "'3'")}

网络数据提取
>>> from lxml.html import parse
>>> from urllib2 import urlopen
>>> parsed = parse(urlopen('http://finance.yahoo.com/q/op?s=AAPL+Options'))
>>> doc = parsed.getroot()
>>> links = doc.findall('.//a')
>>> links[15:20]
[<Element a at 0xc976048>, <Element a at 0xc976138>, <Element a at 0xc976188>, <Element a at 0xc976778>, <Element a at 0xc976638>]
>>> for lnk in links:
... lnk.get('href')
... lnk.text_content()
...
>>> urls = [lnk.get('href') for lnk in doc.findall('.//a')]
>>> urls[-10:]
['http://facebook.com/yahoofinance', 'http://yahoofinance.tumblr.com', '/', '/watchlists', '/portfolios', '/screener', '/calendar', '/industries', '/personal-finance', '/tech']