输入输出可以划分为几个大类:
1.读取文本文件和其他更高效的磁盘存储格式
2.加载数据库中的数据
3.利用Web API操作网络资源
---------------------------------------------------------------------------
一、读写文本格式的数据
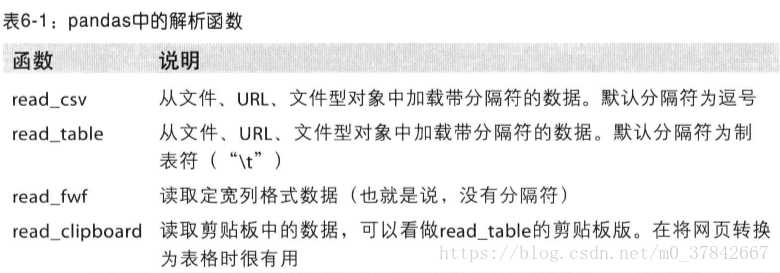

以逗号分隔的文件使用pd.read_csv。

表头的第一行会自动作为列名使用。
也可以使用read_table,只不过需要指定分隔符:
如果设置header=None,则pandas会为其分配默认的列名,也可以通过names=[]自己定义列名。

也可以通过index_col参数指定“message”列作为dataframe的索引:

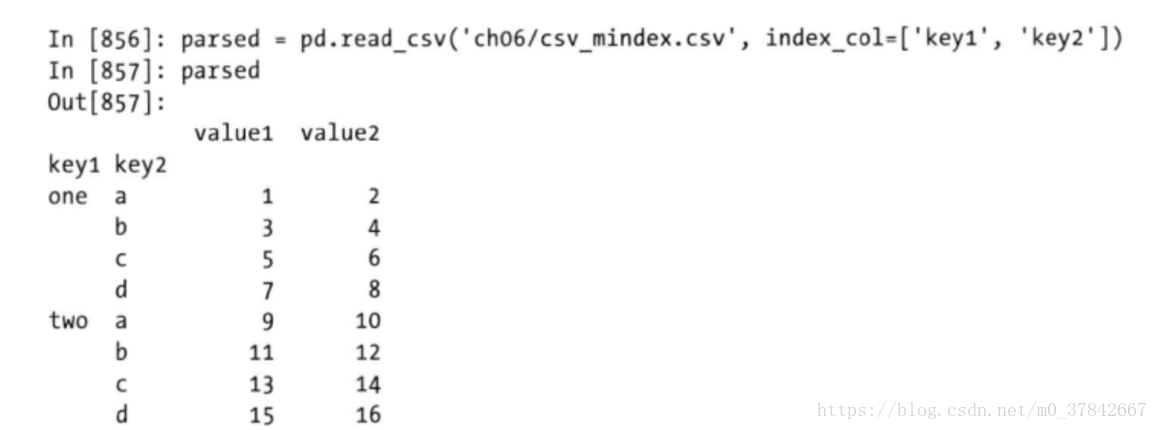
如果希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可:
如果分隔符不是固定的字符,那么可以编写正则表达式作为read_table的分隔符。

如果输入的表格模式为列名的数量比列的数量少1,那么没有列名的那列会自动被read_table识别为索引。
解析器函数中包含许多参数足以处理各种各样的异形文件格式:


接下来列出常用的功能:
1.用skiprows跳过文件的第一行、第三行和第四行

2.缺失值处理
pandas通常默认的标记值有NA、-1.#IND和NULL等
用pd.isnull函数可以判断是否为空值。
na_values可以添加一组用于表示缺失值的字符串【除了以上的默认标记】:

也可以用一个字典为各列指定不同的NA标记值:


二、逐块读取文本文件
对于很大的文件,读取的时候不能在屏幕上打印所有的数据:

如果只想读取几行,可以通过nrows指定:
pd.read_csv('dir',nrows=?)
逐块读取文件可以设置chunksize:

返回的是TextParser对象,可以进行迭代处理。例如,想要统计每1000行中某个column的值频次:

TextParser还有一个get_chunk方法,可以读取任意大小的块。
三、将数据写出到文本格式
利用dataframe的to_csv方法,可以将数据写到一个以逗号分隔的文件中:

可以直接将结果写出到sys.stdout,即在屏幕上打印出文本结果。

打印出的结果可以禁用行和列的标签:
data.to_csv(sys.stdout,index=False,header=False)
也可以只打印部分列,并以给定的顺序排列:
data.to_csv(sys.stdout,index=False,cols=['a','b','c'])
对于series,也有同样的to_csv方法打印结果。
如果要读取csv,可以采用from_csv方法:
Series.from_csv('dir',parse_dates=True)
四、手工处理分隔符格式
zip()是压缩,zip(*)是解压缩。
对于任何单字符分隔符文件,可以直接用python内置的csv模块。
import csv
f=open('ch06/ex7.csv')
reader=csv.reader(f)
csv.reader中也有很多关键字可以用来手动处理文件:

五、json数据
json:JavaScript Object Notation的简称,是通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。
json.loads:将JSON字符串转换成Python形式。
json.dumps:将Python对象转换成JSON格式。
六、读取Microsoft Excel文件
首先需要安装xlrd和openpyxl,才能使用ExcelFile方法。
xls_file=pd.ExcelFile('data.xls')
存放在某个工作表中的数据可以通过parse读取到DataFrame中:
table=xls_file.parse('Sheet1')
七、使用数据库
【参见数据库连接一章】
八、存取MongoDB中的数据
博主还没有搞懂mongodb,所以只能先把笔记记下来了TAT。
首先需要加载pymongo:

存储在MongoDB中的文档被组织在数据库的集合中。
访问集合tweets:tweets=con.db.tweets
将手上的twitter API的数据加载进来通过tweet.save存入集合中:

从集合中取数的查询语句是:
