先贴出来传统的FIR滤波器实现结构作为后面的对比:
传统的FIR滤波器的实现结构:
(【 FPGA 】FIR滤波器开篇之传统抽头延迟线FIR滤波器实现介绍)
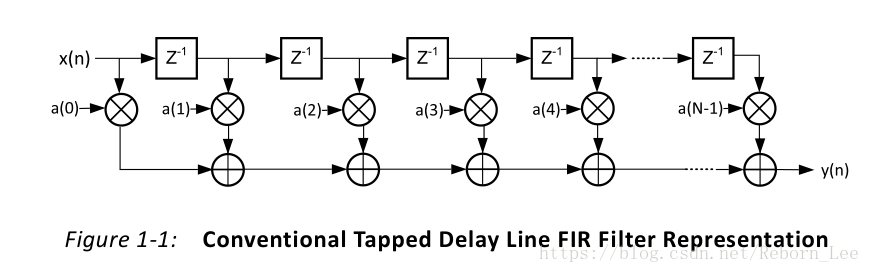
图1
实现公式如下:
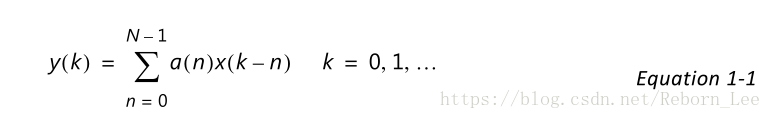
上面贴出的博文也说了,这种结构对于概念的理解很有帮助,但是实际的FPGA实现不用!
我们以10阶的FIR滤波器为例,也就是有11个系数(抽头),那么它的输出就是上式的N改为11即可。也即:
(1)
这里提前声明下,由于图片来源不同,所以为了统一符号,这里的h(n)和a(n)都一样,都表示滤波器的系数,也就是抽数代表的数值。

相关博文:【 FPGA 】FIR 滤波器的架构
下面是脉冲型乘累加结构的FIR滤波器的一种形式,可称为流水线直接型,脉动型乘累加结构简写为SMAC结构,英文名:Systolic Multiply-Accumulate(SMAC)。
这个词:Systolic,英文翻译为收缩,脉动等,那如何理解呢?
我看到了这样的一句话,仅供参考:脉动型FIR滤波器是对直接型的升级,在每个操作后都加入流水线级,每个动作都打一拍,就跟心脏跳动一样,因此称为脉动型,这种结构非常适用于高速数据流的处理。
这句话来源:(http://my.bj51.org/article/id/13902)
下面通过公式推导,看看这种结构是如何实现FIR滤波器的。

图2
上图(网上资源)与下图(Xilinx官方数据手册)等价:
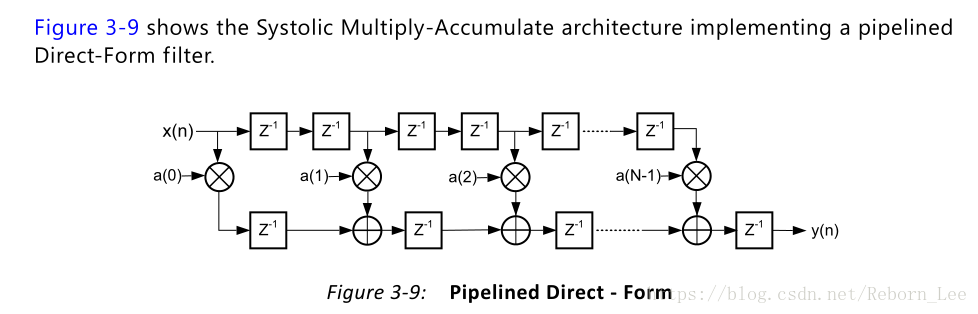
图3
以图二为例:(手稿)
与直接型结构不同的是,输入数据到下一个处理单元都需要打2拍,这是为了使乘法后的累加数据同步,下面是验证过程:

(天天用键盘,突然手写,感觉好艰难,不过也好过敲公式。)
可见,使用这种SMAC结构的FIR滤波器可以实现传统滤波器的功能,只不过有点延迟而已。
那又有一个问题是FPGA是不是就是用这种结构的呢?那还不一定,因为数据手册上给出了多MAC实现的SMAC架构,如下图:
博文:FIR滤波器架构
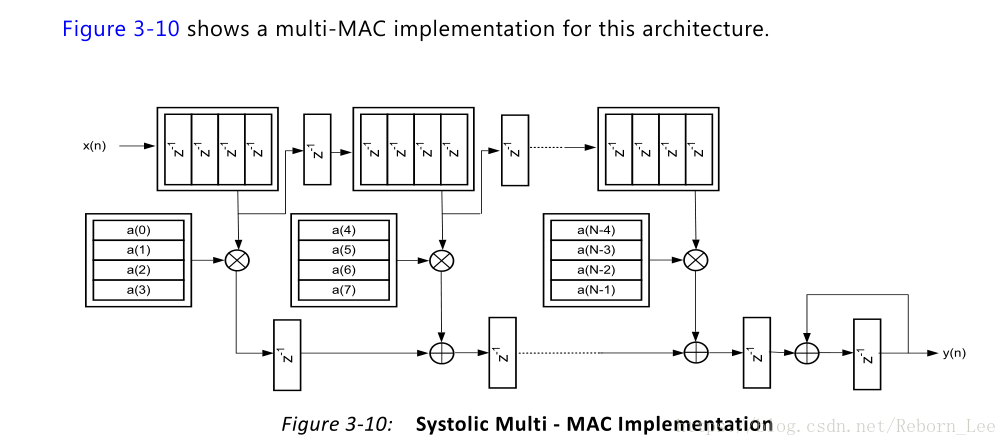
图4
这种多MAC的SMAC架构的实现,我还没看懂,不便分析。
在博文:【 FPGA 】FIR滤波器的采样速率与系统时钟速率不同时的资源消耗分析
在定制FIR滤波器的IP核的分析中,采用SMAC结构,发现在FPGA中消耗的资源是DSP slice,如下(选取了任意一张图):
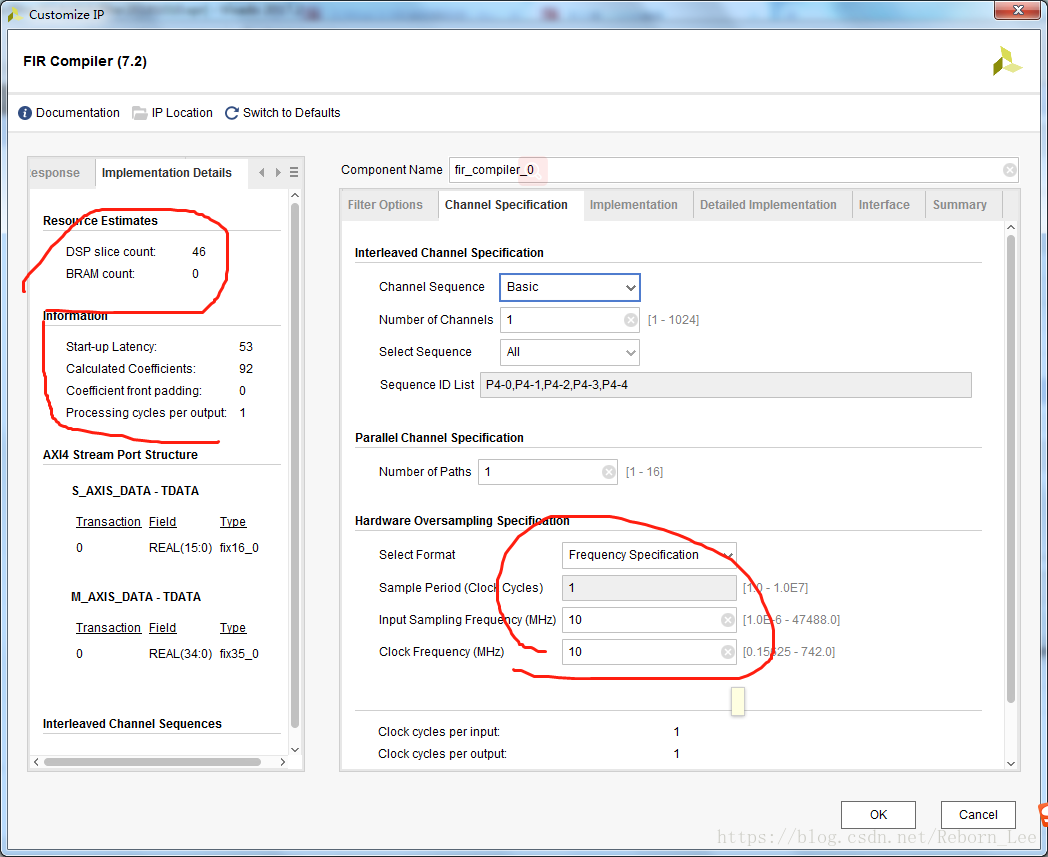
图5
为什么消耗的是DSP slice资源呢?博文中也作出了简单的分析,数据手册中有直接的答案,那就是该SMAC结构直接由DSP片支持,从而实现了区域高效和高性能的过滤器实现。
由此,我们过渡到下图:

图6
该图也来自互联网,还有下面这段话:
图6所示为11抽头系数脉动型FIR滤波器FPGA实现结构(实例与前几节相同),穿了一层“衣服”,采用Xilinx FPGA中的DSP48E1 实现,基本处理单元中的操作都可在一个DSP48E1中完成,输入数据经过DSP48E1中寄存2拍后通过ACOUT输出,直接连接到下一个 DSP48E1中的ACIN端口,累加输出PCOUT直接连接到下一个DSP48E1中的PCIN端口,这些连接都没有经过FPGA的Fabric连线逻辑,而是通过DSP Block的内部走线连接,这样实现能够缩短路径的延时。
这段话来源:http://my.bj51.org/article/id/13902(下面的这种情况也是来源于此地址)
下图是通过线性相位实现的SMAC结构:

图7
如图7所示,各节点P1、P2、P3、P4、P5和y(n)的表达式如下
P1=x(n-5)h(0) + x(n-15)h(0)
P2=( P1 + (x(n-6)h(1) + x(n-14)h(1)) )Z-1=x(n-6)h(0) + x(n-16)h(0) + x(n-7)h(1) + x(n-15)h(1)
P3=( P2 + (x(n-8)h(2) + x(n-14)h(2)) )Z-1=x(n-7)h(0) + x(n-17)h(0) + x(n-8)h(1) + x(n-16)h(1) + x(n-9)h(2) + x(n-15)h(2)
P4=( P3 + (x(n-10)h(3) + x(n-14)h(3)) )Z-1=x(n-8)h(0) + x(n-18)h(0) + x(n-9)h(1) + x(n-17)h(1) + x(n-10)h(2) + x(n-16)h(2) + x(n-11)h(3) + x(n-15)h(3)
P5=( P4 + (x(n-12)h(4) + x(n-14)h(4)) )Z-1=x(n-9)h(0) + x(n-19)h(0) + x(n-10)h(1) + x(n-18)h(1) + x(n-11)h(2) + x(n-17)h(2) + x(n-12)h(3) + x(n-16)h(3) + x(n-13)h(4) + x(n-15)h(4)
y(n)=(P5 + x(n-14)h(5))Z-1= x(n-10)h(0) + x(n-20)h(0) + x(n-11)h(1) + x(n-19)h(1) + x(n-12)h(2) + x(n-18)h(2) + x(n-13)h(3) + x(n-17)h(3) + x(n-14)h(4) + x(n-16)h(4) + x(n-15)h(5)
因抽头系数对称,由h(0)=h(10),h(1)=h(9),h(2)=h(8),h(3)=h(7),h(4)=h(6)可得
y(n)= x(n-10)h(0) + x(n-11)h(1) + x(n-12)h(2) + x(n-13)h(3) + x(n-14)h(4) + x(n-15)h(5) + x(n-16)h(6) + x(n-17)h(7) + x(n-18)h(8) + x(n-19)h(9) + x(n-20)h(10)
验证得到y(n)=yt(n-10),比普通脉动结构延时小,但是相比于其他结构的FIR滤波器延时还是较大的。
这是系数对称的情况,可以这么实现,如果系数不对称,恐怕就没有这么个对比了。
如果使用IP compiler去设计一个SMAC结构的FIR滤波器,其内容具体使用那种结构,那就不知道了,只能说大概就是如此。
写到这里,似乎还是不满意。因为对它的时序关系还不是太了解。那下篇博文是不是应该分析下时序问题呢?我去看看再说!