(一)聚簇索引
覆盖索引不是一种单独的索引类型(索引类型大致分为B-Tree索引、Hash索引、全文索引、空间数据索引、其他索引我们不是特别见到的这几大类),是一种数据存储方式,在索引存储结构结构上保存数据。InnoDB的聚簇索引实际上是在同一个结构中保存了B-Tree索引和数据行。
每一个表都有一个聚簇索引,并且只有一个。(覆盖索引除外,覆盖索引可以模拟多个聚簇索引)
聚簇索引的数据存储方式:
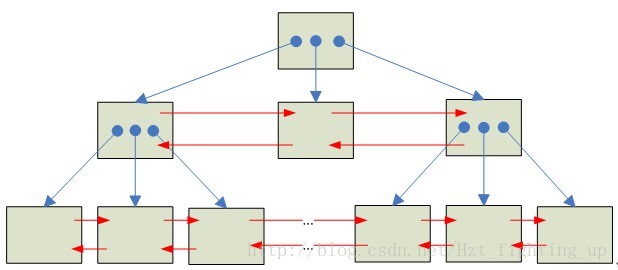
叶子节点:保存了行的全部数据(对应数据库中的一行数据)
非叶子节点:只包含了索引列和页面指针。在InnoDB存储引擎中索引列就是主键列。所以非叶子节点中保存的是主键和指向其他页面的指针。如果没有定义一个主键,InnoDB会选择一个唯一的非空索引代替,如果没有的话,会隐式定义一个主键来作为聚簇索引。
总结:聚簇索引通过主键将数据行紧凑的存储在一起。可以将聚簇索引理解为数据库中完整的一张数据表
聚簇索引的优点:
1)将相关数据保存在一起
2)数据访问速度更快
3)使用覆盖索引扫描的查询可以直接使用页节点中的主键值
聚簇索引的缺点:
1)聚簇数据最大限度地提高了I/O密集型应用的性能,如果数据放在内存中就没有优势了
2)插入速度依赖插入顺序
3)使全表扫描速度变慢
4)二级索引比想象中的大
5)更新聚簇索引列(主键)的代价很高
6)插入新行时可能面临页分裂
7)二级索引访问需要两次索引查找,而不是一次
在InnoDB存储引擎中,应尽可能地按照主键顺序插入数据,并且尽可能地使用单调递增的聚簇键的值来插入新行。因为聚簇索引中按照索引键的顺序进行存储的。如果插入的索引键的大小和前一个插入的索引键的大小没有任何关机,即是随机的,插入时会出现问题:
1):导致大量随机I/O
2):频繁的页分裂操作
3):数据碎片化
在高并发工作负载中,在InnoDB中按照主键顺序插入会造成明显的争用。并发插入可能导致间隙锁竞争。还有可能是auto_increment锁机制(类似于多线程并发中的i++操作),遇到这个问题可以更改为innodb_autonic_lock_mode配置
(二)二级索引
表上的每个非聚簇以外都是二级索引
二级索引中每个叶子节点中包含了索引列(这里不是主键,一般都是自己指定的索引),紧接着就是主键列
为什么二级索引需要两次索引?二级索引的叶子节点保存的不是指向行的物理位置的指针,而是行的主键值,所以二级索引需要在查找一次聚簇索引。
叶子节点存储主键值的目的:减少了当出现行移动或者数据分裂时二级索引的维护工作。使用主键值当作指针会让二级索引占用更多的空间,但换来在移动时无须更新二级索引中的主键指针。
(三)覆盖索引
什么是覆盖索引?如果一个索引包含所有需要查询的字段的值,则这个索引就为覆盖索引
使用覆盖索引可以极大提高性能,因为无需进行回表查询。主要优点有:
1):极大减少数据访问
2):如果二级主键能够覆盖查询,则可以避免对主键的二次查询
覆盖索引必须要存储索引列的值。mysql只能使用B-Tree索引做覆盖索引
覆盖索引也有一定的局限性。覆盖索引可能导致无法实现优化。MySQL查询优化器会在执行查询前判断是否有一个索引能够进行覆盖。如果索引覆盖了where条件中的字段,但不是整个查询的字段,则会使用回表方式读取数据
能够使用覆盖索引的情形:
1)查询语句的所有字段都包括在一个索引里面,且与字段顺序无关,比如我有一个索引
idx_payment_date(paymnet_date,amount,last_update)
则sql语句:
select amount,last_update,payment_date from payment
select amount,payment_date from payment
都将使用覆盖索引进行查询
而sql语句:
select customer_id,payment_date from payment
将不使用覆盖索引,因为customer_id字段不在那个索引里面
2)查询二级索引中的字段+主键字段。因为二级索引的叶子节点包含了主键的值