1、前提
MySQL索引一直是面试中的常客,一提起索引,很多人都能答出来我知道Hash索引和B+树索引,Hash是比较简单的,那么B+树索引就有点复杂了。
在创建表的时候,我们可以看到引擎有MyISAM , InnoDB等等,这两种是我们经常说到的,从5.5版本及以后引擎就默认为InnoDB了,也说的是从5.1版本之后就默认是InnoDB了,不过这个不用纠结,反正现在使用的mysql基本都默认引擎为InnoDB,我们这篇文章都是基于InnoDB来说的。

2、定义概念
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引以找到特定值,然后顺指针找到包含该值的行。这样可以使对应于表的SQL语句执行得更快,可快速访问数据库表中的特定信息。
当表中有大量记录时,若要对表进行查询,第一种搜索信息方式是全表搜索,是将所有记录一一取出,和查询条件进行一一对比,然后返回满足条件的记录,这样做会消耗大量数据库系统时间,并造成大量磁盘I/O操作;第二种就是在表中建立索引,然后在索引中找到符合查询条件的索引值,最后通过保存在索引中的ROWID(相当于页码)快速找到表中对应的记录。
3、索引类型
根据数据库的功能,可以在数据库设计器中创建四种索引:单列索引、唯一索引、主键索引和聚集索引。
主键索引,唯一索引什么的,都比较简单,这里就不展开介绍了。主要介绍一下聚集索引。
4、聚集索引和非聚集索引
定义概念
聚集索引也称为聚簇索引(Clustered Index),聚类索引,簇集索引 。同样,非聚集索引也称为非聚簇索引,非聚类索引,非簇集索引。
聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
在InnoDB中,MySQL中的数据是按照主键的顺序来存放的。那么聚簇索引就是按照每张表的主键来构造一颗B+树,B+树是在B树的基础上改进的,不会的可以看一下之前的文章。叶子节点存放的就是整张表的行数据。由于表里的数据只能按照一颗B+树排序,因此一张表只能有一个聚簇索引。
引入一个问题:如果表没有建主键怎么办?(一般都会建主键的)
回答是,如果没有主键,则按照下列规则来建聚簇索引
- 没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引。
- 如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
ps:**自增主键和uuid作为主键的区别是什么呢?**由于主键使用了聚簇索引,如果主键是自增id,那么对应的数据一定也是相邻地存放在磁盘上的,写入性能比较高。如果是uuid的形式,频繁的插入会使innodb频繁地移动磁盘块,写入性能就比较低了。
实例讲解聚集索引
先来创建一个表user如下:pId是主键,有字段name和birthday。

这里我们说的是InnoDB引擎,那主键索引也是一个聚集索引,底层结构是B+树。
下面一张图是简略的图,如果你清楚了B+树的结构,那理解起来这个就很轻松了。
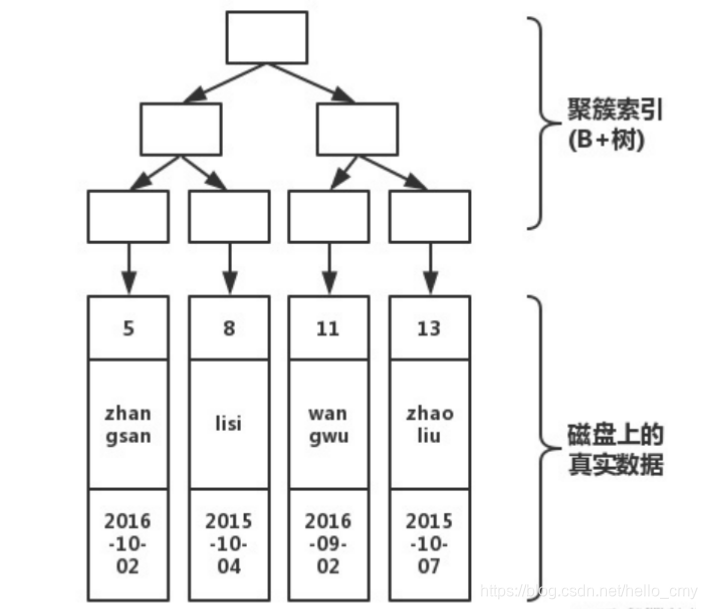
图示很清楚,上半部分是主键形成的B+树,下半部分是磁盘上存储的真实数据。
当我们执行以下语句:
select * from user where pId = 11
那么执行流程如下:
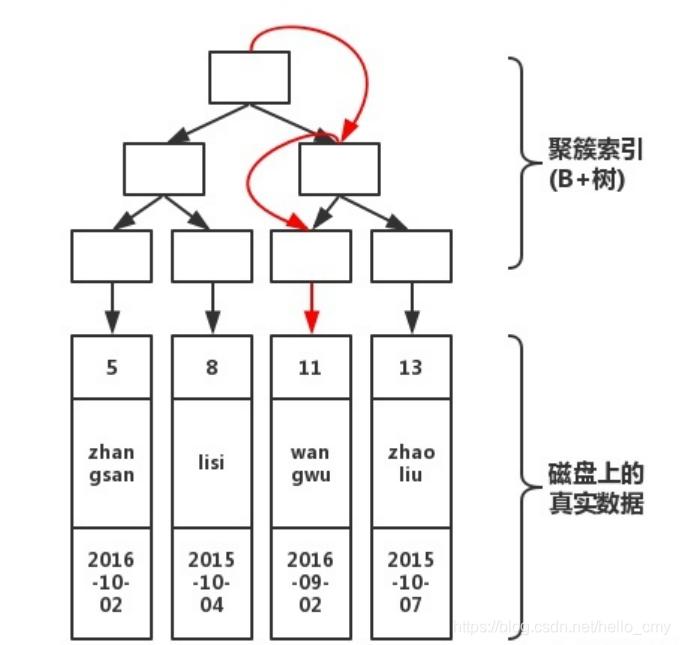
如上图所示,从根开始,经过3次查找,就可以找到真实数据。如果不使用索引,那就要在磁盘上,逐行扫描,直到找到数据位置。显然,使用索引速度会很快。但是,在写入数据的时候,需要维护这颗B+树的结构,因此写入性能会下降!
接下来咱们再理解一下非聚集索引,给name字段加非聚集索引。通过执行下面命令来添加索引,你也可以使用可视化工具来添加索引。
CREATE INDEX NAME ON test(NAME);
咱们再来看看给name添加索引之后,结构图是什么样子的?
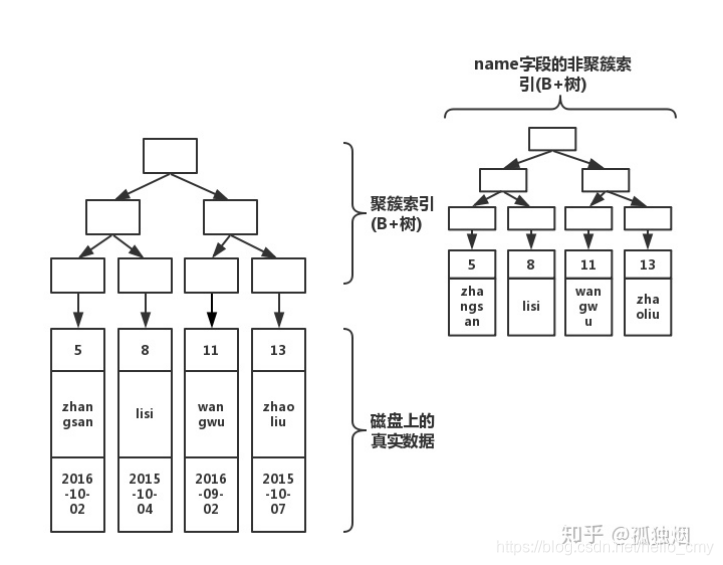
从上面图中,我们可以看到根据索引name新生成了一棵B+树。 我们每加一个索引,就会增加表的体积, 占用磁盘存储空间。并且这里还有一点变化,叶子节点,非聚簇索引的叶子节点并不是真实数据,它的叶子节点依然是索引节点,存放的是该索引字段的值以及对应的主键索引(聚簇索引)。
如果我们执行下列语句
select * from user where name = 'lisi'
我们现在加了非聚集索引之后,这条sql语句怎么去查询呢?
再来一张图:

通过上图我们看到,先从非聚簇索引树开始查找,找到name为lisi的叶子节点,根据lisi的主键pId,再去聚簇索引B+树中去找,就能拿到pId对应的行数据。
再看下面的这一条语句,在查询的时候在非聚簇索引上就找到了要的name值,那么就不会再去聚簇索引上查找了。效率更高。
select name from user where name = 'lisi'
总结
通过上面的例子,我们看到多加一个索引,就会多生成一颗非聚簇索引树。所以说,索引不能乱加。在做插入操作的时候,需要同时维护这几颗树的变化!如果索引太多,插入性能就会下降!
5、索引的优缺点
优点:
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
缺点:
1.索引需要占物理空间。
2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
图来自于https://zhuanlan.zhihu.com/p/62018452