聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。
在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
因此,MYSQL中不同的数据存储引擎对聚簇索引的支持不同就很好解释了。下面,我们可以看一下MYSQL中MYISAM和INNODB两种引擎的索引结构
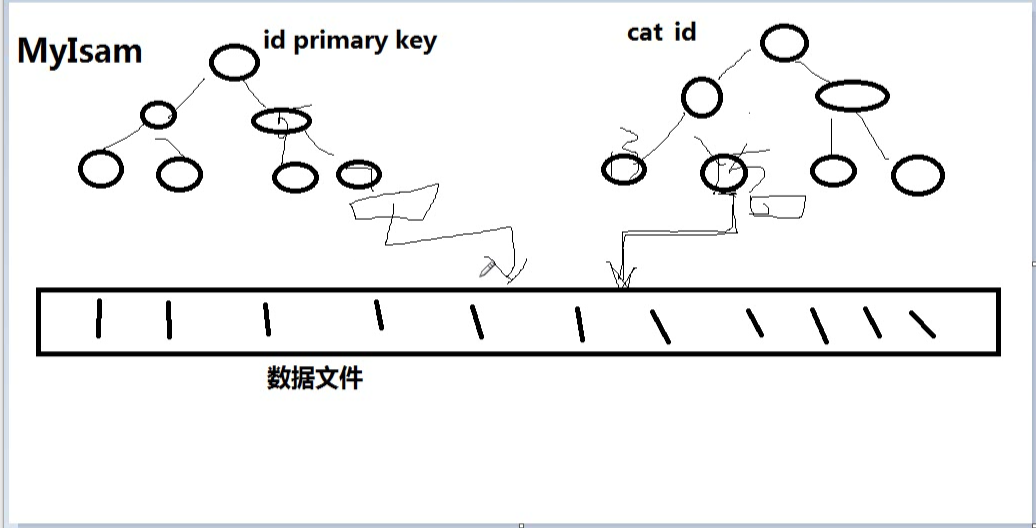
myisam的索引存储图如下,可以看出,无论是id还是cat_id,下面都存储有执行物理地址的值。通过主键索引或者次索引来查询数据的时候,都是先查找到物理位置,然后再到物理位置上去寻找数据。
innodb的索引存储图如下,我们会发现,主键索引下面直接存储有数据,而次索引下,存储的是主键的id。通过主键查找数据的时候,就会很快查找到数据,但是通过次索引查找数据的时候,需要先查找到对应的主键id,然后才能查找到对应的数据。
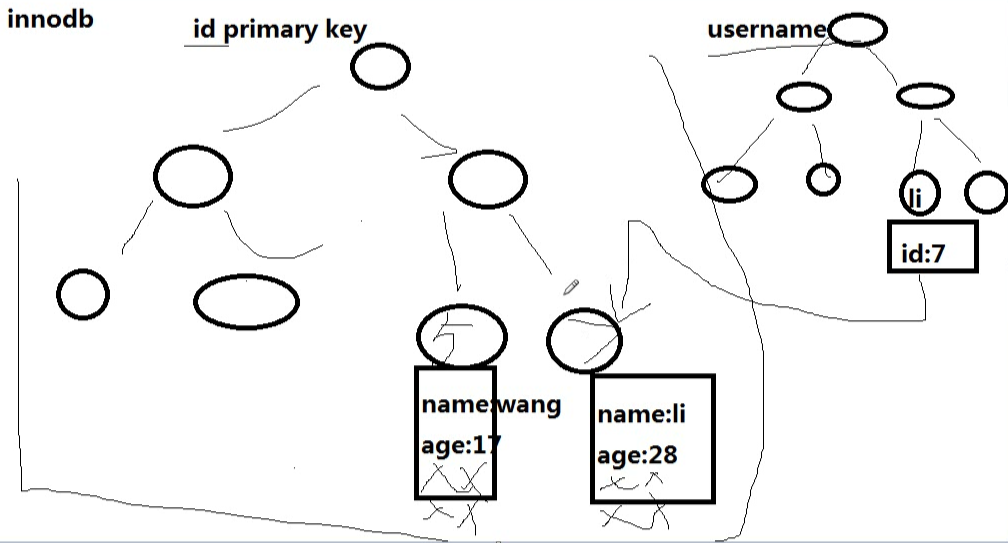
nnodb的主索引文件上 直接存放该行数据,称为聚簇索引,次索引指向对主键的引用
myisam中, 主索引和次索引,都指向物理行(磁盘位置).
注意: innodb来说,
1: 主键索引 既存储索引值,又在叶子中存储行的数据
2: 如果没有主键, 则会Unique key做主键
3: 如果没有unique,则系统生成一个内部的rowid做主键.
4: 像innodb中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”