我的归纳:
(1)InnoDB的主键采用聚簇索引存储,使用的是B+Tree作为索引结构,但是叶子节点存储的是索引值和数据本身(注意和MyISAM的不同)。
(2)InnoDB的二级索引不使用聚蔟索引,叶子节点存储的是KEY字段加主键值。因此,通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。
(3)MyISAM的主键索引和二级索引叶子节点存放的都是列值与行号的组合,叶子节点中保存的是数据的物理地址
(4)MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址
(5)为什么用B+Tree 不是BTree:
B-Tree:如果一次检索需要访问4个节点,数据库系统设计者利用磁盘预读原理,把节点的大小设计为一个页,那读取一个节点只需要一次I/O操作,完成这次检索操作,最多需要3次I/O(根节点常驻内存)。数据记录越小,每个节点存放的数据就越多,树的高度也就越小,I/O操作就少了,检索效率也就上去了。
B+Tree:非叶子节点只存key,大大滴减少了非叶子节点的大小,那么每个节点就可以存放更多的记录,树更矮了,I/O操作更少了。所以B+Tree拥有更好的性能。
下面是原文中对聚簇索引的介绍,介绍的很简单易懂:
1.聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。
一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。
在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
因此,MySQL中不同的数据存储引擎对聚簇索引的支持不同就很好解释了。
2.下面,我们可以看一下mysql中MYISAM和INNODB两种引擎的索引结构。
如原始数据为:
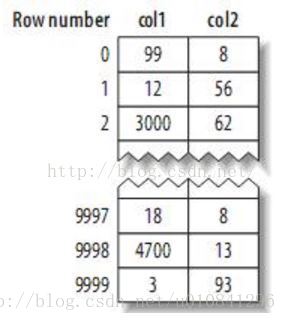
MyISAM引擎的数据存储方式如图:
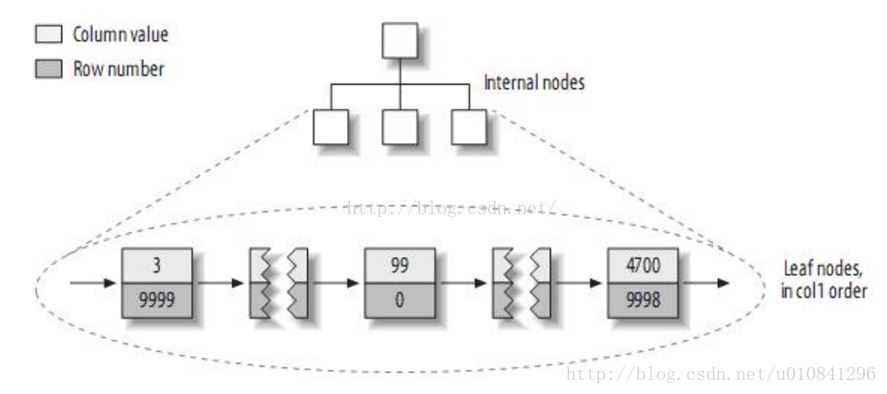
(1)MYISAM是按列值与行号来组织索引的。它的叶子节点中保存的实际上是指向存放数据的物理块的指针。
从MYISAM存储的物理文件我们能看出,MYISAM引擎的索引文件(.MYI)和数据文件(.MYD)是相互独立的。
(2)而InnoDB按聚簇索引的形式存储数据,所以它的数据布局有着很大的不同。它存储数据的结构大致如下:
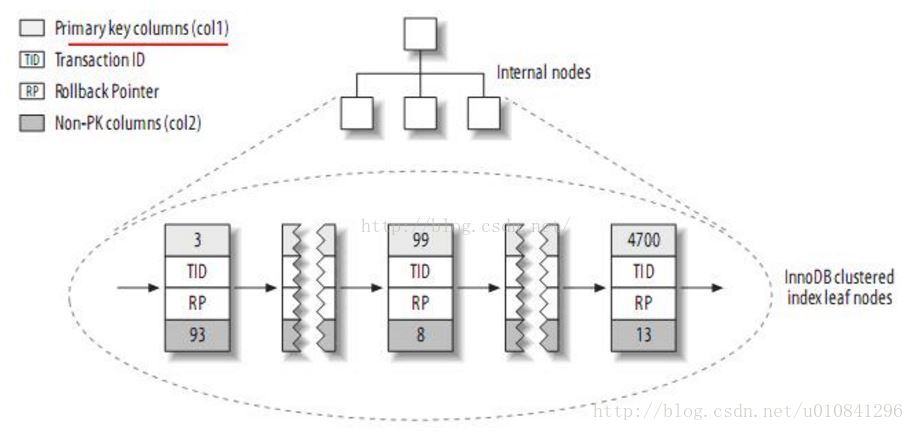
注:聚簇索引中的每个叶子节点包含主键值、事务ID、回滚指针(rollback pointer用于事务和MVCC)和余下的列(如col2)。
(3)INNODB的二级索引与主键索引有很大的不同。InnoDB的二级索引的叶子包含主键值,而不是行指针(row pointers),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为InnoDB不需要更新索引的行指针。其结构大致如下:
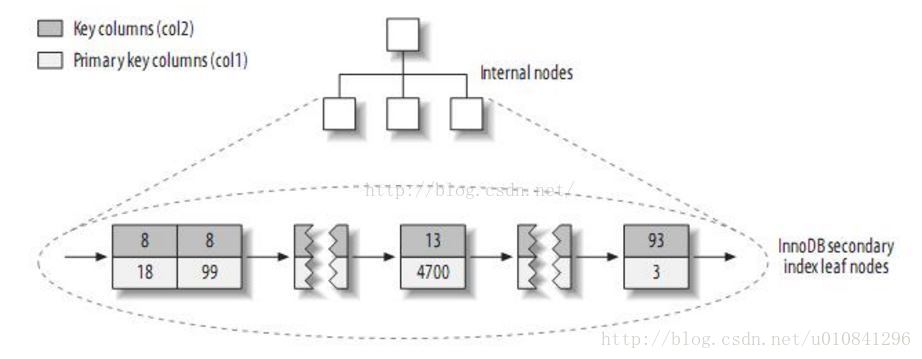
INNODB和MYISAM的主键索引与二级索引的对比:
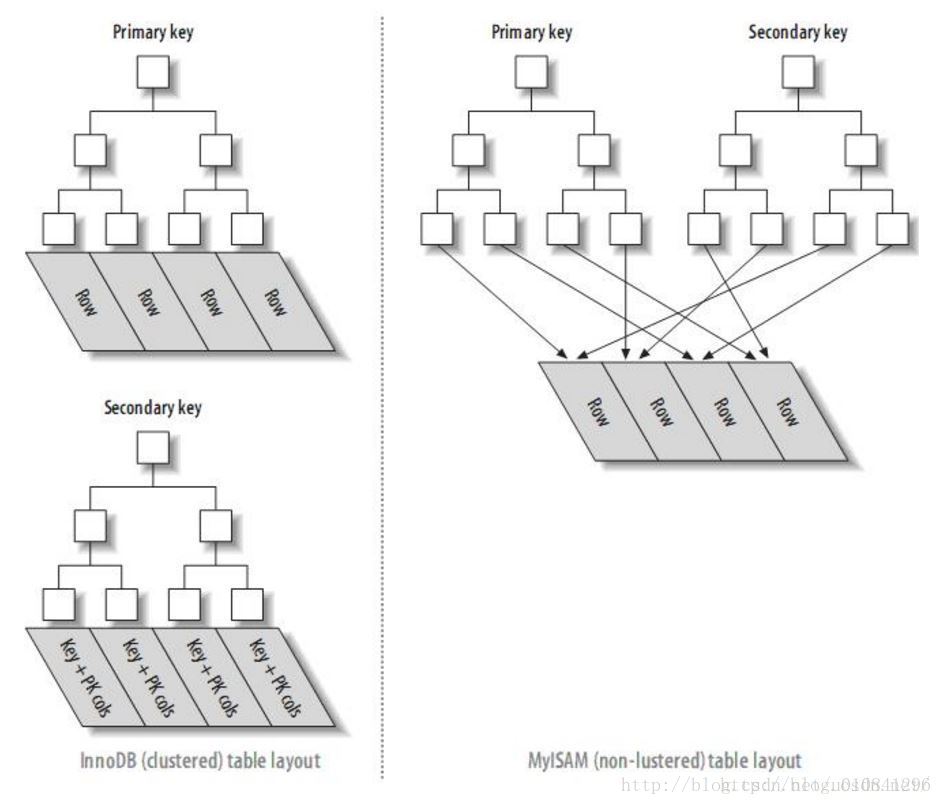
(4)InnoDB的的二级索引的叶子节点存放的是KEY字段加主键值。因此,通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。而MyISAM的二级索引叶子节点存放的还是列值与行号的组合,叶子节点中保存的是数据的物理地址。所以可以看出MYISAM的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做PRIMARY的唯一、非空的索引,且MYISAM引擎中可以不设主键。