机器学习中训练样本不均衡问题
1. 训练样本不均衡
在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的。当我们把这些算法直接应用于实际数据时,大多数情况下都无法取得理想的结果。因为实际数据往往分布得很不均匀,都会存在“长尾现象”,也就是所谓的“二八原理”。下图是新浪微博交互分布情况:
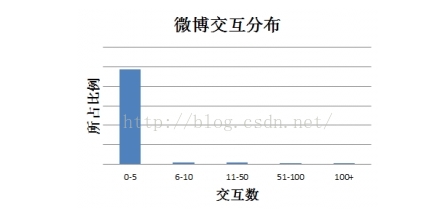
可以看到大部分微博的总互动数(被转发、评论与点赞数量)在0-5之间,交互数多的微博(多于100)非常之少。如果我们去预测一条微博交互数所在档位,预测器只需要把所有微博预测为第一档(0-5)就能获得非常高的准确率,而这样的预测器没有任何价值。那如何来解决机器学习中数据不平衡问题呢?这便是这篇文章要讨论的主要内容。
严格地讲,任何数据集上都有数据不平衡现象,这往往由问题本身决定的,但我们只关注那些分布差别比较悬殊的;另外,虽然很多数据集都包含多个类别,但这里着重考虑二分类,因为解决了二分类中的数据不平衡问题后,推而广之就能得到多分类情况下的解决方案。综上,这篇文章主要讨论如何解决二分类中正负样本差两个及以上数量级情况下的数据不平衡问题。
不平衡程度相同(即正负样本比例类似)的两个问题,解决的难易程度也可能不同,因为问题难易程度还取决于我们所拥有数据有多大。比如在预测微博互动数的问题中,虽然数据不平衡,但每个档位的数据量都很大——最少的类别也有几万个样本,这样的问题通常比较容易解决;而在癌症诊断的场景中,因为患癌症的人本来就很少,所以数据不但不平衡,样本数还非常少,这样的问题就非常棘手。综上,可以把问题根据难度从小到大排个序:大数据+分布均衡<大数据+分布不均衡<小数据+数据均衡<小数据+数据不均衡。说明:对于小数据集,机器学习的方法是比较棘手的。对于需要解决的问题,拿到数据后,首先统计可用训练数据有多大,然后再观察数据分布情况。经验表明,训练数据中每个类别有5000个以上样本,其实也要相对于特征而言,来判断样本数目是不是足够,数据量是足够的,正负样本差一个数量级以内是可以接受的,不太需要考虑数据不平衡问题(完全是经验,没有理论依据,仅供参考)。
2. 解决方法
解决这一问题的基本思路是让正负样本在训练过程中拥有相同的话语权,比如利用采样与加权等方法。为了方便起见,我们把数据集中样本较多的那一类称为“大众类”,样本较少的那一类称为“小众类”。
欠采样:就是把多余的样本去掉,保持这几类样本接近,在进行学习。(可能会导致过拟合)
过采样:就是增加比较少样本那一类的样本数量,比如你可以收集多一些数据,或者对数据增加噪声,如果是图像还可以旋转,裁剪,缩放,平移等,或者利用PCA增加一些样本,等方法
加正则项:就是直接采用不均衡数据进行训练,可以在代价函数那里需要增加样本权重,用来平衡这个问题,也就是类别数量少的那一类代价就高,权重就比较大。在评价模型好坏的时候也需要考虑样本权重问题。
-