
上文已经介绍了利用过欠(过)采样的方式来解决正负样本不均衡的问题,本篇文章,我们介绍解决正负样本不均衡问题的第二招——通过正负样本的惩罚权重解决样本不均衡。
我们先假设现在有这样一个数据集:数据集中有100个0样本,10个1样本,总共有110个样本。则0、1样本的比例是10:1。在以下的所有方法介绍中,我们都以处理这个数据集为例。
一、简单粗暴法:
1、原理
先看这样一个例子:假如我要参加一场既考语文又考数学的考试,但是我手里有一套语文模拟卷和十套数学模拟卷,因为我能够练习的语文题比较少,所以我对于这套语文卷就要更加重视一些。
同理,给样本量较少的类别的损失值赋予更高的权重,给样本量较多的类别损失值赋予更低的权重,简单粗暴地为小样本标签增加损失函数的权值,可以让模型更关注类别较少的样本中所含的信息。
我们以交叉损失函数来例,详细说明具体的执行过程。
正常的交叉熵损失函数计算公式如下所示:
Loss = −ylg( p ) − (1−y)lg(1−p)
如果对于一个1样本,我们的模型给出该样本是1样本的概率为0.3,则Loss值为-lg(0.3)= 0.52。
如果对于一个0样本,我们的模型给出该样本是1样本的概率为0.7(即预测是0样本的概率也为0.3),则Loss将获得-log(0.3)= 0.52。
可以看到,对于0、1样本有相同的偏差情况下,模型给出的损失函数是一样的。
对于上边的数据集来说,既然1样本只有0样本的1/10,我们可以令1样本的损失权重增加10倍,新的损失函数变成了:
Loss2 = −10ylg ( p ) − 1(1−y)lg(1−p)
对于上述1样本来说,虽然我们的模型给出正样本的概率为0.3,Loss2的值则会变为-10lg(0.3)= 5.2;对于上述的负样本来说,loss2依旧是0.52。
这意味着,对于每个预测错误的1样本,我们模型就会给予相对于0样本来说10倍的损失值,从而使得模型对预测错误的正样本有足够的重视,保证充分利用仅有的正样本。
2、在scikit-learn的实现
以上这个过程在大多数算法中都不用我们自己实现,在scikit-learn中,很多模型和算法都提供了一个接口,来让我们根据实际样本量的比例调整类别权重。
以SVM算法为例,通过设置class_weigh的值,来手动指定不同的类别权重,比如我们想要将正负样本损失权重比例设置为10:1,只需要添加这样的参数:class_weight= {1:10,0:1} 。
当然,我们也可以进一步偷懒,只需要:class_weight = 'balanced',那么SVM会将权重设置为与不同类别样本数量呈反比的权重来进行自动均衡处理,权重计算公式为:样本总数量 / (类别数 *某类样本数量 )。
对于上边所示的数据集来说,经过计算,0样本的权重为:110/(2100) = 0.55,1样本的权重为:110/(210)= 5.5。可以看到,0、1样本数量的比例是10:1,计算之后0、1样本损失权重的比例就是:0.55:5.5 = 1:10,正好和样本数量成反比。
SVM、决策树、随机森林等算法都可以用这种方法来指定。
1) 首先导入需要的包以及生成一个正负样本不均衡的数据集:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
import numpy as np
############################ 生成不均衡的分类数据集###########
from sklearn import datasets
X,Y = datasets.make_classification(n_samples = 1000,
n_features = 4,
n_classes = 2,
weights = [0.95,0.05])
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.1,random_state=0)
这里生成的0样本和1样本的比例是95:5。
2)不对正负样本进行处理训练一个SVM分类器
SVM_model = SVC(random_state = 66) #设定一个随机数种子,保证每次运行结果不变化
SVM_model.fit(train_x,train_y)
pred1 =SVM_model.predict(train_x)
accuracy1 = recall_score(train_y,pred1)
print('在训练集上的召回率:\n',accuracy1)
pred2 = SVM_model.predict(test_x)
accuracy2 = recall_score(test_y,pred2)
print('在测试集上的召回率:\n',accuracy2)
输出结果:
在训练集上的召回率:
0.56
在测试集上的召回率:
0.2
因为0、1样本非常不均衡,就算模型把所有的样本都判断为0样本,模型也会获得95%的正确率,而且在实际使用中,我们更希望模型能够把少量样本筛选出来,比如反洗钱中的可疑交易、信用卡中的不良贷款等。
所以这里我们用召回率来评判对正样本的检测效果,可以看到,在正常情况下,在测试集上的召回率只有0.2。
3)对正负样本损失值设置不同权重训练一个SVM分类器
SVM_model2 = SVC(random_state = 66,class_weight = 'balanced') #设定一个随机数种子,保证每次运行结果不变化
SVM_model2.fit(train_x,train_y)
pred1 =SVM_model2.predict(train_x)
accuracy1 = recall_score(train_y,pred1)
print('在训练集上的召回率:\n',accuracy1)
pred2 = SVM_model2.predict(test_x)
accuracy2 = recall_score(test_y,pred2)
print('在测试集上的召回率:\n',accuracy2)
输出:
在训练集上的召回率:
0.8
在测试集上的召回率:
0.8
可以看到,给正样本足够的权重之后,召回率有了明显的上升,变为0.8。
(这里如果用精确度来评价,你会发现这里精确度反而下降了,不用担心这是模型为了找出1样本而误判了一部分0样本,这是正常现象。)
另外,有一些算法可能没有提供接口,我们也可以训练时在fit函数中通过sample_weight参数进行指定。具体可以参考scikit-learn文档。
注意:如果一不小心两个参数都使用了,那么最终正负样本的权重是:class_weight*sample_weight
二、更加精细化的处理方法:
在第一种方法中,我们简单粗暴地通过各类样本量的反比来确定损失权重,这种方法效果已经会非常显著了。但是,上面的改进并没有对一些更难分类的样本做一些处理,我们不仅希望平衡样本,而且希望将易分类的样本提供的loss比重减小,将难分类的样本提供的loss比重增大。这就好比:我们不仅要更关注这套语文模拟卷,更要重点关注这套卷子里做错的题。Focal loss(权重动态调整)的思想就是完美地兼顾了这两个方面。
Focal loss提出的原始想法是用来解决图像检测中类别不均衡的问题,这里多说一句,图像检测领域是一个典型的正负样本不均衡的领域,因为在一张图像中,大多数情况下,目标总是占据图像的一小部分,占据图像大部分的是背景。如果你日常处理一些样本不均衡的数据问题,不妨看看图像检测领域,找找灵感。
我们依旧以为二分类交叉熵损失函数为例。Focal losss损失函数在的基础上从
变成了:
仔细看这个公式,损失函数的权重是由两个权重共同决定:
,第一个权重不必多说,就是方法一中的根据正负样本量自定义的损失权重,重点看第二个权重。
若是对于某个1样本来说,模型预测其为1样本的概率是0.9,那么第二个权重为:(1-0.9)^ 2 = 0.01,而如果模型预测某个样本为1样本的概率是0.6,那么第二个权重变为:(1-0.6)^2 = 0.16。样本预测越不准确,损失值所占的权重就会更大。
原论文中有一张图形象地说明了,横坐标代表预测对的概率,纵坐标代表损失值,,中间红色虚线代表预测对的概率是0.5,虚线左半边代表模型预测偏差很大,右半边代表模型预测偏差较小。gamma = 0时,就是第二个权重项不参与下的损失值:
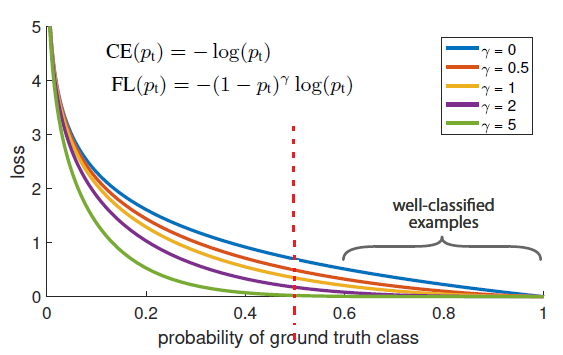
可以看到,相对于图中蓝色曲线来说,随着gamma增大,在红线的左半边,几条曲线损失值差别不大,但是红线的右半边,损失值迅速趋近于0。
而且更巧妙的是,一般来说,如果0样本远比1样本多的话,模型肯定会倾向于将样本预测为0这一类(全部样本都判为0类,模型准确率依旧很高),上边的第二个权重也会促使模型花更多精力去关注数量较少的1样本。
总结一句话,Focal loss就是在,进一步对比较难分类的样本加大损失权重,使模型对分错的样本更加重视,从而使得模型快速收敛,且获得更好的性能表现。
关于Focal loss的思想,scikit-learn中还没有实现,感兴趣的可以自己实现。
