要理解P问题、NP问题、NPC问题、NP-hard问题,需要先弄懂几个概念:
- 什么是多项式时间?
- 什么是确定性算法?什么是非确定性算法?
- 什么是规约/约化?
文章目录
多项式时间(Polynomial time)
什么是时间复杂度?
时间复杂度并不是表示一个程序解决问题需要花多少时间,而是当程序所处理的问题规模扩大后,程序需要的时间长度对应增长得有多快。也就是说,对于某一个程序,其处理某一个特定数据的效率不能衡量该程序的好坏,而应该看当这个数据的规模变大到数百倍后,程序运行时间是否还是一样,或者也跟着慢了数百倍,或者变慢了数万倍。
不管数据有多大,程序处理所花的时间始终是那么多的,我们就说这个程序很好,具有 的时间复杂度,也称常数级复杂度;数据规模变得有多大,花的时间也跟着变得有多长,比如找n个数中的最大值这个程序的时间复杂度就是 ,为线性级复杂度,而像冒泡排序、插入排序等,数据扩大2倍,时间变慢4倍的,时间复杂度是 ,为平方级复杂度。还有一些穷举类的算法,所需时间长度成几何阶数上涨,这就是 的指数级复杂度,甚至 的阶乘级复杂度。
不会存在 KaTeX parse error: Expected 'EOF', got '\*' at position 4: O(2\̲*̲n^2) 的复杂度,因为前面的那个"2"是系数,根本不会影响到整个程序的时间增长。同样地, 的复杂度也就是 的复杂度。因此,我们会说,一个KaTeX parse error: Expected 'EOF', got '\*' at position 7: O(0.01\̲*̲n^3)的程序的效率比O(100*n^2)的效率低,尽管在n很小的时候,前者优于后者,但后者时间随数据规模增长得慢,最终 的复杂度将远远超过 。我们也说, 的复杂度小于 的复杂度。
容易看出,前面的几类复杂度被分为两种级别,其中后者的复杂度无论如何都远远大于前者。像 , , 等,我们把它叫做多项式级复杂度,因为它的规模n出现在底数的位置;另一种像是 和 等,它是非多项式级的复杂度,其复杂度计算机往往不能承受。当我们在解决一个问题时,我们选择的算法通常都需要是多项式级的复杂度,非多项式级的复杂度需要的时间太多,往往会超时,除非是数据规模非常小。
确定性算法与非确定性算法
确定性算法:
设A是求解问题B的一个解决算法,在算法的整个执行过程中,每一步都能得到一个确定的解,这样的算法就是确定性算法。
非确定性算法:
设A是求解问题B的一个解决算法,它将问题分解成两部分,分别为猜测阶段和验证阶段,其中
- 猜测阶段:在这个阶段,对问题的一个特定的输入实例x产生一个任意字符串y,在算法的每一次运行时,y的值可能不同,因此,猜测以一种非确定的形式工作。
- 验证阶段:在这个阶段,用一个确定性算法(有限时间内)验证。①检查在猜测阶段产生的y是否是合适的形式,如果不是,则算法停下来并得到no;② 如果y是合适的形式,则验证它是否是问题的解,如果是,则算法停下来并得到yes,否则算法停下来并得到no。它是验证所猜测的解的正确性。
规约/约化
问题A可以约化为问题B,称为“问题A可规约为问题B”,可以理解为问题B的解一定就是问题A的解,因此解决A不会难于解决B。由此可知问题B的时间复杂度一定大于等于问题A。
《算法导论》中有一个例子:现在有两个问题:求解一个一元一次方程和求解一个一元二次方程。那么我们说,前者可以规约为后者,意即知道如何解一个一元二次方程那么一定能解出一元一次方程。我们可以写出两个程序分别对应两个问题,那么我们能找到一个“规则”,按照这个规则把解一元一次方程程序的输入数据变一下,用在解一元二次方程的程序上,两个程序总能得到一样的结果。这个规则即是:两个方程的对应项系数不变,一元二次方程的二次项系数为0。
从规约的定义中我们看到,一个问题规约为另一个问题,时间复杂度增加了,问题的应用范围也增大了。通过对某些问题的不断规约,我们能够不断寻找复杂度更高,但应用范围更广的算法来代替复杂度虽然低,但只能用于很小的一类问题的算法。存在这样一个NP问题,所有的NP问题都可以约化成它。换句话说,只要解决了这个问题,那么所有的NP问题都解决了。这种问题的存在难以置信,并且更加不可思议的是,这种问题不只一个,它有很多个,它是一类问题。这一类问题就是传说中的NPC问题,也就是NP-完全问题。
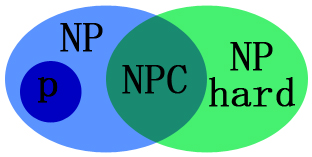
P类问题、NP类问题、NPC问题、NP难问题
-
P类问题:能在多项式时间内可解的问题。
-
NP类问题:在多项式时间内“可验证”的问题。也就是说,不能判定这个问题到底有没有解,而是猜出一个解来在多项式时间内证明这个解是否正确。即该问题的猜测过程是不确定的,而对其某一个解的验证则能够在多项式时间内完成。P类问题属于NP问题,但NP类问题不一定属于P类问题。
-
NPC问题:存在这样一个NP问题,所有的NP问题都可以约化成它。换句话说,只要解决了这个问题,那么所有的NP问题都解决了。其定义要满足2个条件:
- 它是一个NP问题;
- 所有NP问题都能规约到它。
- NP难问题:NP-Hard问题是这样一种问题,它满足NPC问题定义的第二条但不一定要满足第一条(就是说,NP-Hard问题要比 NPC问题的范围广,NP-Hard问题没有限定属于NP),即所有的NP问题都能约化到它,但是他不一定是一个NP问题。NP-Hard问题同样难以找到多项式的算法,但它不列入我们的研究范围,因为它不一定是NP问题。即使NPC问题发现了多项式级的算法,NP-Hard问题有可能仍然无法得到多项式级的算法。事实上,由于NP-Hard放宽了限定条件,它将有可能比所有的NPC问题的时间复杂度更高从而更难以解决。
以上四个问题之间的关系如下图所示:
P=NP?
- 此处会再次从不同的角度来讨论P与NP的定义。
“P=NP?” 通常被认为是计算机科学最重要的问题。在很早的时候,就有个数学家毫不客气的指出,P=NP? 是个愚蠢的问题,并且为了嘲笑它,专门在4月1号写了一篇“论文”,称自己证明了 P=NP。
首先,我们要搞清楚什么是“P=NP?” 为此,我们必须先了解一下什么是“算法复杂度”。为此,我们又必须先了解什么是“算法”。我们可以简单的把“算法”想象成一台机器,就跟绞肉机似的。我们给它一些“输入”,它就给我们一些“输出”。比如,绞肉机的输入是肉末,输出是肉渣。牛的输入是草,输出是奶。“加法器”的输入是两个整数,输出是这两个整数的和。“算法理论”所讨论的问题,就是如何设计这些机器,让它们更加有效的工作。就像是说如何培育出优质的奶牛,吃进相同数量的草,更快的产出更多的奶。
世界上的计算问题,都需要“算法”经过一定时间的工作(也叫“计算”),才能得到结果。计算所需要的时间,往往跟“输入”的大小有关系。你的牛吃越是多的草,它就需要越是长时间才能把它们都变成奶。这种草和奶的转换速度,通常被叫做“算法复杂度”。算法复杂度通常被表示为一个函数f(n),其中n是输入的大小。比如,如果我们的算法复杂度为n^2,那么当输入10个东西的时候,它需要100个单元的时间才能完成计算。当输入100 个东西的时候,它需要10000个单元的时间才能完成。当输入1000个数据的时候,它需要1000000个单元的时间。所谓的“P时间”,多项式时间,就是说这个复杂度函数f(n)是一个多项式。
“P=NP?”中的“P”,就是指所有这些复杂度为多项式的算法的“集合”,也就是“所有”的复杂度为多项式的算法。为了简要的描述以下的内容,我定义一些术语:
- “f(n)时间算法”=“能够在f(n)时间之内,解决某个问题的算法”
当f(n)是个多项式(比如 )的时候,这就是“多项式时间算法”(P时间算法)。当f(n)是个指数函数(比如 )的时候,这就是“指数时间算法”(EXPTIME算法)。很多人认为NP问题就是需要指数时间的问题,而NP跟EXPTIME,其实是风马牛不相及的。很显然,P不等于EXPTIME,但是P是否等于NP,却没有一个结论。
现在我来解释一下什么是NP。通常的计算机,都是确定性(deterministic)的。它们在同一个时刻,只有一种行为。如果用程序来表示,那么它们遇到一个条件判断(分支)的时候,只能一次探索其中一条路径。比如:
if (x == 0) {
one();
}
else {
two();
}
在这里,根据x的值是否为零,one()和two()这两个操作,只有一个会发生。然而,有人幻想出来一种机器,叫做“非确定性计算机”(nondeterministic computer),它可以同时运行这程序的两个分支,one()和two()。这有什么用处呢?它的用处就在于,当你不知道x的大小的时候,根据one()和two()是否“运行成功”,你可以推断出x是否为零。这种方式可以同时探索多种可能性。这不是普通的“并行计算”,因为每当遇到一个分支点,非确定性计算机就会产生新的计算单元,用以同时探索这些路径。这机器就像有“分身术”一样。当这种分支点存在于循环(或者递归)里面的时候,它就会反复的产生新的计算单元,新的计算单元又产生更多的计算单元,就跟细胞分裂一样。一般的计算机都没有 这种“超能力”,它们只有固定数目的计算单元。所以他只能先探索一条路径,失败之后,再回过头来探索另外一条。所以,它们似乎要多花一些时间才能得到结果。到这里,基本的概念都有了定义,于是我们可以圆满的给出P和NP的定义。P和NP是这样两个“问题的集合”:
P = “确定性计算机”能够在“多项式时间”解决的所有问题
NP = “非确定性计算机”能够在“多项式时间”解决的所有问题
(注意它们的区别,仅在于“确定性”或者是“非确定性”。)
“P=NP?”问题的目标,就是想要知道P和NP这两个集合是否相等。为了证明两个集合(A和 B)相等,一般都要证明两个方向:
- A 包含 B;
- B 包含 A。
上一个标题中我们已经说过NP包含了P。因为任何一个非确定性机器,都能被当成一个确定性的机器来用。你只要不使用它的“超能力”,在每个分支点只探索一条路径就行。所以“P=NP?”问题的关键,就在于P是否也包含了NP。也就是说,如果只使用确定性计算机,能否在多项式时间之内,解决所有非确定性计算机能在多项式时间内解决的问题。
我们来细看一下什么是多项式时间(Polynomial time)。我们都知道, 是多项式, 也是多项式。多项式与多项式之间,却有天壤之别。把解决问题所需要的时间,用“多项式”这么笼统的概念来描述,其实是非常不准确的做法。在实际的大规模应用中, 的算法都嫌慢。能找到“多项式时间”的算法,根本不能说明任何问题。对此,理论家们喜欢说,就算再大的多项式(比如 ),也不能和再小的指数函数(比如 )相比。因为总是“存在”一个M,当n>M的时候, 会超过 。可是问题的关键,却不在于M的“存在”,而在于它的“大小”。如果你的输入必须达到天文数字才能让指数函数超过多项式的话,那么还不如就用指数复杂度的算法。所以,“P=NP?”这问题的错误就在于,它并没有针对我们的实际需要,而是首先假设了我们有“无穷大”的输入,有“无穷多”的时间和耐心,可以让多项式时间的算法“最终”得到优势。
Reference:
[1] 对于“NP难问题”的理解:http://blog.csdn.net/u010021014/article/details/77839858
[2] 谈“P=NP?”:http://yinwang0.lofter.com/post/183ec2_4f6312
本博客与https://xuyunkun.com同步更新