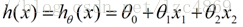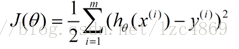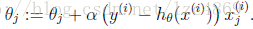1、线性回归的主要思想就是通过历史数据拟合出一条直线,用这条直线对新的数据进行预测。(例如:位于线性函数两边的分别为A.B类)
2、现实世界中的影响因素很多,因此我们需要使用多元线性函数来描述一个事件(结果)
3、多元线性函数:研究二分类观察结果y与一些影响因素(x1,x2,x3,…,xn)之间关系的一种多变量分析方法,例如医学中根据病人的一些症状来判断它是否患有某种病。
4、多元线性回归公式:
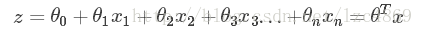
5、sigmoid函数:
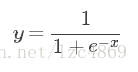
将多元线性函数z带入到sigmoid函数中,我们就得到了广义线性回归模型
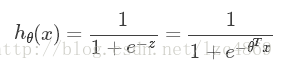
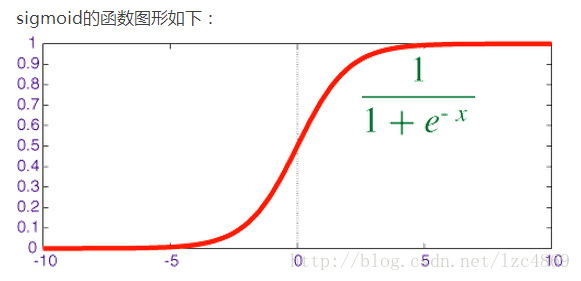
6、sigmoid的函数输出是介于(0,1)之间的,中间值是0.5,这样我们可以将sigmoid函数看成样本数据的概率密度函数
因为 hθ(x) 输出是介于(0,1)之间,也就表明了数据属于某一类别的概率,例如 :
hθ(x)<0.5 则说明当前数据属于A类
hθ(x)>0.5 则说明当前数据属于B类
7、如何使用广义线性回归模型
考虑具有n个独立变量的向量X=(x1,x2,x3,…,xn),设条件慨率P(y=1|X)=p为根据观测量相对于某事件发生的概率。那么Logistic回归模型可以表示为
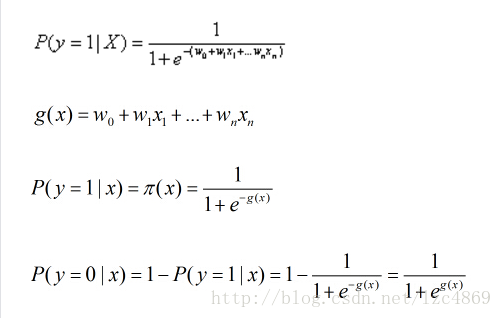
所以事件发生与不发生的概率之比为
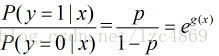
这个比值称为事件的发生比,对其取对数得到
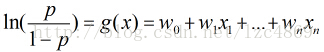
假设有m个观测样本,观测值分别为y1,y2,y3,…ym,设Pi=P(yi=1| xi) 为给定条件下得到yi=1的概率,则yi=0的概率为P(yi=0 | xi)=1 - pi,所以得到一组观测值的概率为
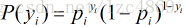
因为各个观测样本之间相互独立,那么它们的联合分布为各边缘分布的乘积。得到似然函数
然后我们的目标是求出使这一似然函数的值最大的参数估计,托福口语最大似然估计就是求出参数w0,w1,w2,w3,…wn,使得L(w)取得最大值,对函数L(w)取对数得到
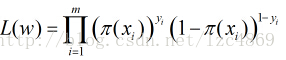
最终变形为
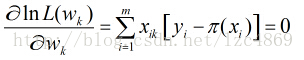
其中 yi 为真实值

8、 确定最佳回归系数的过程,也就是对数据集进行训练的过程4.
求最佳回归系数的步骤如下:
1. 列出分类函数:当h(x) > 0 为 A 类,h(x) < 0 为B类
(θ 指回归系数,在实践中往往会再对结果进行一个Sigmoid转换)
2. 给出分类函数对应的错误估计函数:
(m为样本个数)
只有当某个θ向量使上面的错误估计函数J(θ)取得最小值的时候,这个θ向量才是最佳回归系数向量。
3. 采用梯度下降法或者最小二乘法求错误函数取得最小值的时候θ的取值:
后一个状态和前一个状态
为表述方便,上式仅为一个样本的情况,实际中要综合多个样本的情况需要进行一个求和 (除非你使用后面会介绍的随机梯度上升算法), 将步骤 2 中的错误函数加上负号,就可以把问题转换为求极大值,梯度下降法转换为梯度上升法。