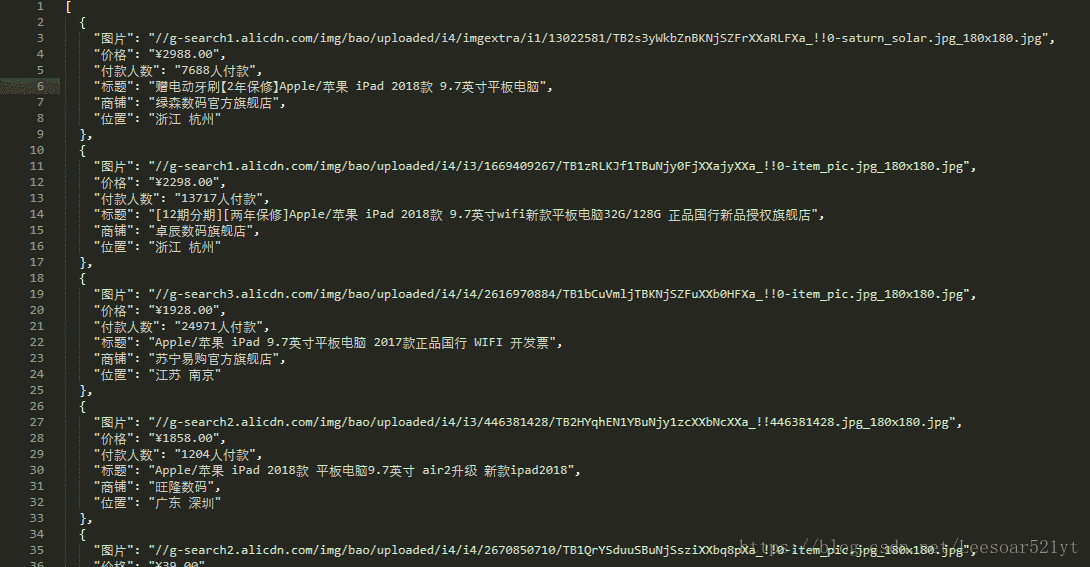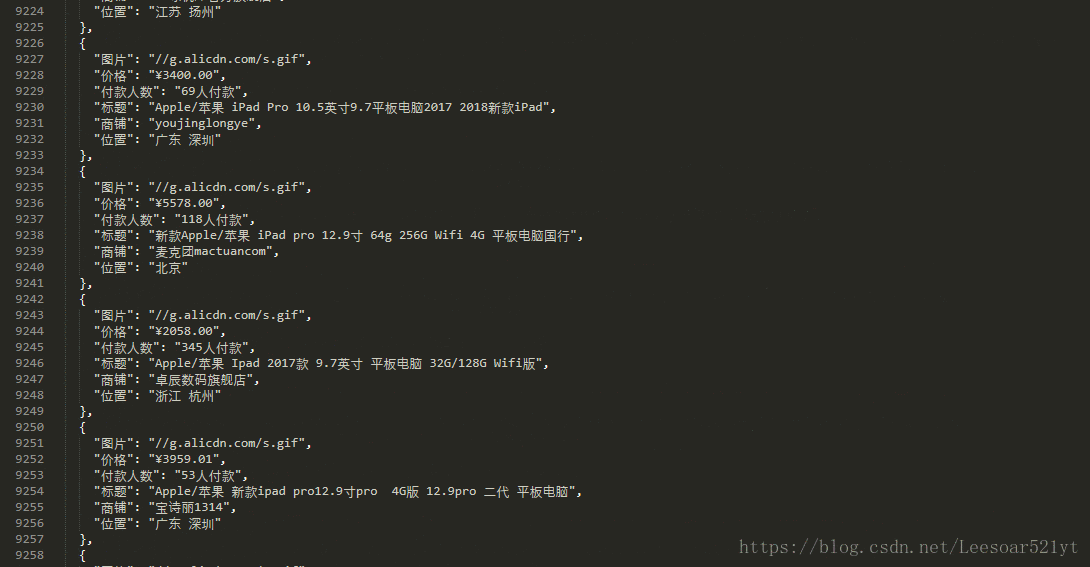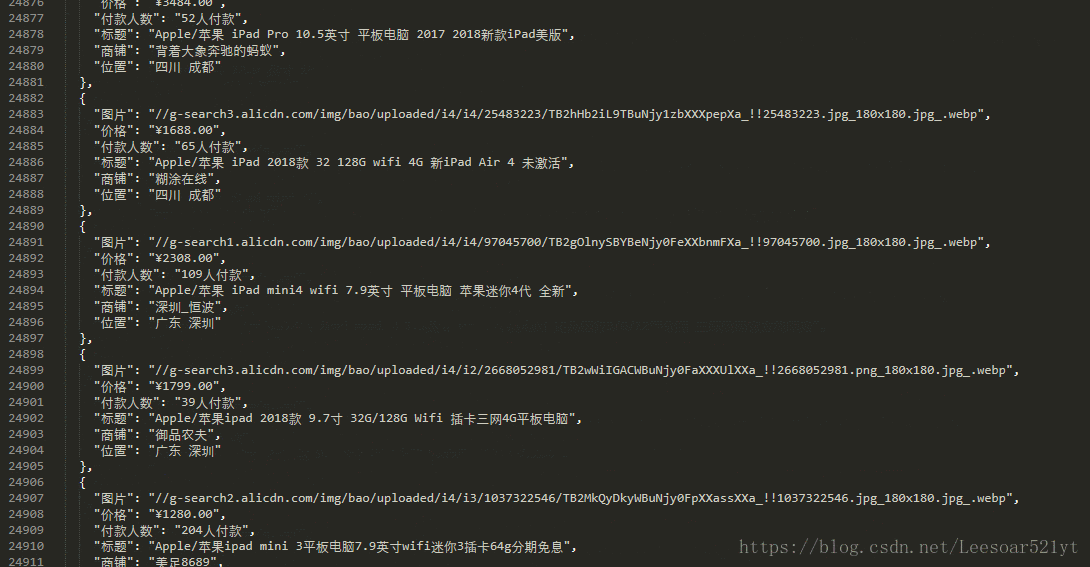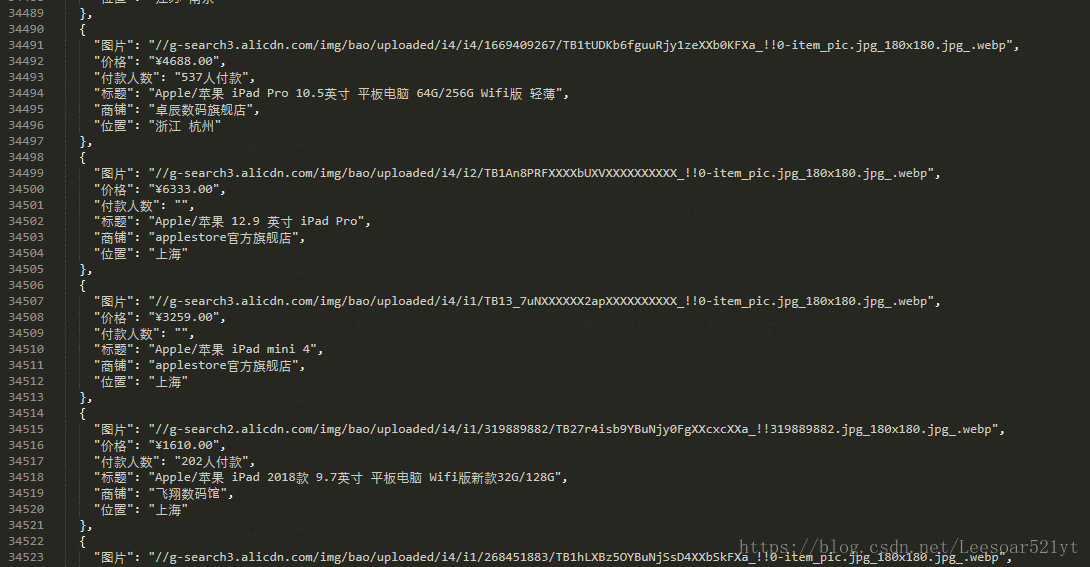
版权声明:来自 https://blog.csdn.net/Leesoar521yt/article/details/81461939
淘宝页面数据使用Ajax获取,所以最方便的方式还是采用Selenium抓取,最后将商品数据保存为json格式文件。
工具:ChromeDriver与Selenium
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from bs4 import BeautifulSoup
from json import dumps
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
KEYWORD = 'iPad'
def index_page(page):
"""
抓取当前页面
"""
print("正在爬取第", page, "页")
try:
url = 'https://s.taobao.com/search?q={}'.format(KEYWORD)
browser.get(url)
if page > 1:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.m-itemlist .items .item')))
get_products()
except TimeoutException:
index_page(page)
def get_products():
"""
美味汤提取宝贝信息
"""
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
html_list = soup.find('div', {'class': 'm-itemlist'}).find_all('div', {'data-category': 'auctions'})
product_list = []
for sub in html_list:
product = {
'图片': sub.find('div', {'class': 'pic'}).img['src'],
'价格': sub.find('div', {'class': 'price g_price g_price-highlight'}).get_text().strip(),
'付款人数': sub.find('div', {'class': 'deal-cnt'}).get_text(),
'标题': sub.find('div', {'class': 'row row-2 title'}).get_text().strip(),
'商铺': sub.find('div', {'class': 'shop'}).get_text().strip(),
'位置': sub.find('div', {'class': 'location'}).get_text()
}
product_list.append(product)
with open('./taobao.json', 'a', encoding='UTF-8') as f:
f.write(dumps(product_list, indent=2, ensure_ascii=False))
print('Finished.')
for page in range(1, 101):
index_page(page)无图无真相,结果如下: