一个真实的网站的很多网站的网页都不是静态的 HTML 文档,大部分都包含 JsvaScript
程序,很多信息都是通过 JavaScript 程序处理后才显示出来的,使用普通的爬虫程序不能爬
取这种网站的数据,我们必须使用一种能执行网页中 JavaScript 程序的工具,才能编写爬虫程序
爬取这类网站的数据,Selenium 就是这样一种工具。
本博是关于动态页面爬取的实践记录,通过flask自行设计一个小的动态页面,然后静态的爬取,再用selenium爬取,查看区别。
1、下载selenium,flask和 bs4
这里建议使用pycharm的包管理器下载,虽然pip也可以。异常指路——>selenium的异常处理
2、创建网页
2.1 本地模板
在本地创建如demo.html的文件,内容如下
<script>
function init()
{
http=new XMLHttpRequest();
http.open("get","/show",false);
http.send(null);
msg=http.responseText;
document.getElementById("sMsg").innerHTML=msg;
document.getElementById("jMsg").innerHTML="JavaScript Message";
}
</script>
<body onload="init()">
Testing<br>
<span id="hMsg">Html Message</span><br>
<span id="jMsg"></span><br>
<span id="sMsg"></span>
</body>
2.2 创建动态网页
在有本地文件的情况下,根目录的方法采用静态网页的创建方法,读取本地文件然后返回。
@app.route("/")
def index():
f = open('demo.html', 'rb')
data = f.read()
f.close()
return data
完整代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:LingInHeart
import flask
app=flask.Flask(__name__)
@app.route("/")
def index():
f = open('demo.html', 'rb')
data = f.read()
f.close()
return data
@app.route("/show")
def show():
return "Server Message"
app.run()
运行服务器的结果是:

3、普通爬虫爬取
建立服务器创建网页后,用requests来爬取网页,完整代码如下:
import requests
html=requests.get('http://127.0.0.1:5000/')
html.raise_for_status()
html.encoding=html.apparent_encoding
print(html.text)
结果是:
<script>
function init()
{
http=new XMLHttpRequest();
http.open("get","/show",false);
http.send(null);
msg=http.responseText;
document.getElementById("sMsg").innerHTML=msg;
document.getElementById("jMsg").innerHTML="JavaScript Message";
}
</script>
<body onload="init()">
Testing<br>
<span id="hMsg">Html Message</span><br>
<span id="jMsg"></span><br>
<span id="sMsg"></span>
</body>
很明显,id='jMsg’和id='sMsg’标签下的内容没能爬取到。
4、selenium动态爬取。
下载selenium后还需要配合浏览器工作的对应驱动。,例如要与 chrome 配合就要下载 chromedrive.exe 的驱动程序,然后把它复制到 python 的 scripts 目录下。
具体下载的方法。
4.1 使用selenium查看网页源代码
使用Chrome时调用:from selenium.webdriver.chrome.options import Options来控制浏览器。
chrome_options=Options()
#设置chrome浏览器无界面模式
chrome_options.add_argument('--headless')
#创建一个chrome浏览器
chrome= webdriver.Chrome()
#访问网站
chrome.get("http://127.0.0.1:5000")
#获得网页源代码
html=chrome.page_source
完整代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:LingInHeart
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
chrome_options=Options()
chrome_options.add_argument('--headless')
chrome= webdriver.Chrome(chrome_options=chrome_options)
chrome.get("http://127.0.0.1:5000")
html=chrome.page_source
print(html)
chrome.close()#关闭浏览器
部分结果:

易发现:id='jMsg’和id='sMsg’标签下的内容爬取到了。
4.2 爬取所需内容
完整代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:LingInHeart
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
chrome_options=Options()
#设置chrome浏览器无界面模式
chrome_options.add_argument('--headless')
chrome= webdriver.Chrome(chrome_options=chrome_options)#创建一个chrome浏览器
chrome.get("http://127.0.0.1:5000")#访问网站
html=chrome.page_source#获得代码
#print(html)
chrome.close()#关闭浏览器
soup=BeautifulSoup(html,"lxml")
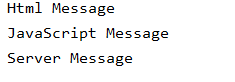
print(soup.find("span",attrs={"id":"hMsg"}).text,soup.find("span",attrs={"id":"jMsg"}).text
,soup.find("span",attrs={"id":"sMsg"}).text,sep='\n')
运行结果:

如果去掉源代码里的:
chrome_options=Options()
#设置chrome浏览器无界面模式
chrome_options.add_argument('--headless')
chrome= webdriver.Chrome(chrome_options=chrome_options)#创建一个chrome浏览器
修改为:chrome= webdriver.Chrome()这样会得到如下运行结果,但是运行过程中会弹出chrome浏览器的界面。
小拓展:
selenium 查找 HTML 元素
