版权声明:可以转载奥 https://blog.csdn.net/Jiajikang_jjk/article/details/82931443
使用Ajax爬去今日头条街拍图片
Ajax背景了解
Ajax ,全称为Asynchronous JavaScript and XML ,即异步的JavaScript 和XML 。它不是一门编程语言,而是利用JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
通常我们遇到的网页,对于更新内容需要刷新整个页面,这也就是Ajax的优点所在。对于个网页,只需要刷新我们更新的部分,其他内容不比刷新。这个过程其实就是后台和服务器之间的数据交互的过程。获取数据之后在使用js改变网页,这样内网页的内容就更新了。这就是Ajax的功劳。
目的:爬去今日头条街拍图片
思路分析
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+ , Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else { //code for IE6, IES
xmlhttp=new ActiveXObject (” Microsoft.XMLHTTP ”);
}
xmlhttp.onreadystatechange=function() {
if(xmlhttp.ready5tate == 4 && xmlhttp.status==200) {
document.getElementByld("myDiv").innerHTML=xmlhttp.responseText;
xmlhttp.open("POST ”,"/ajax /”, true);
xmlhttp.send();
发送请求
1: 创建了一个XMLHttpRequest 然后调用onreadystatechange属性设置监听
2:调用open()和send()方法向某个链接发送请求
解析内容
3:响应得到之后,onreadystatechange对应的方法便会触动。
4:利用xmlhttp的responseText得到响应的内容-->返回的结果可能是html,json
5:然后在方法中使用js处理
渲染页面
目的: 爬去今日头条的街拍美图--保存到本地
思路分析:
1:安装requests库
2:今日头条首页网址
https://www.toutiao.com/
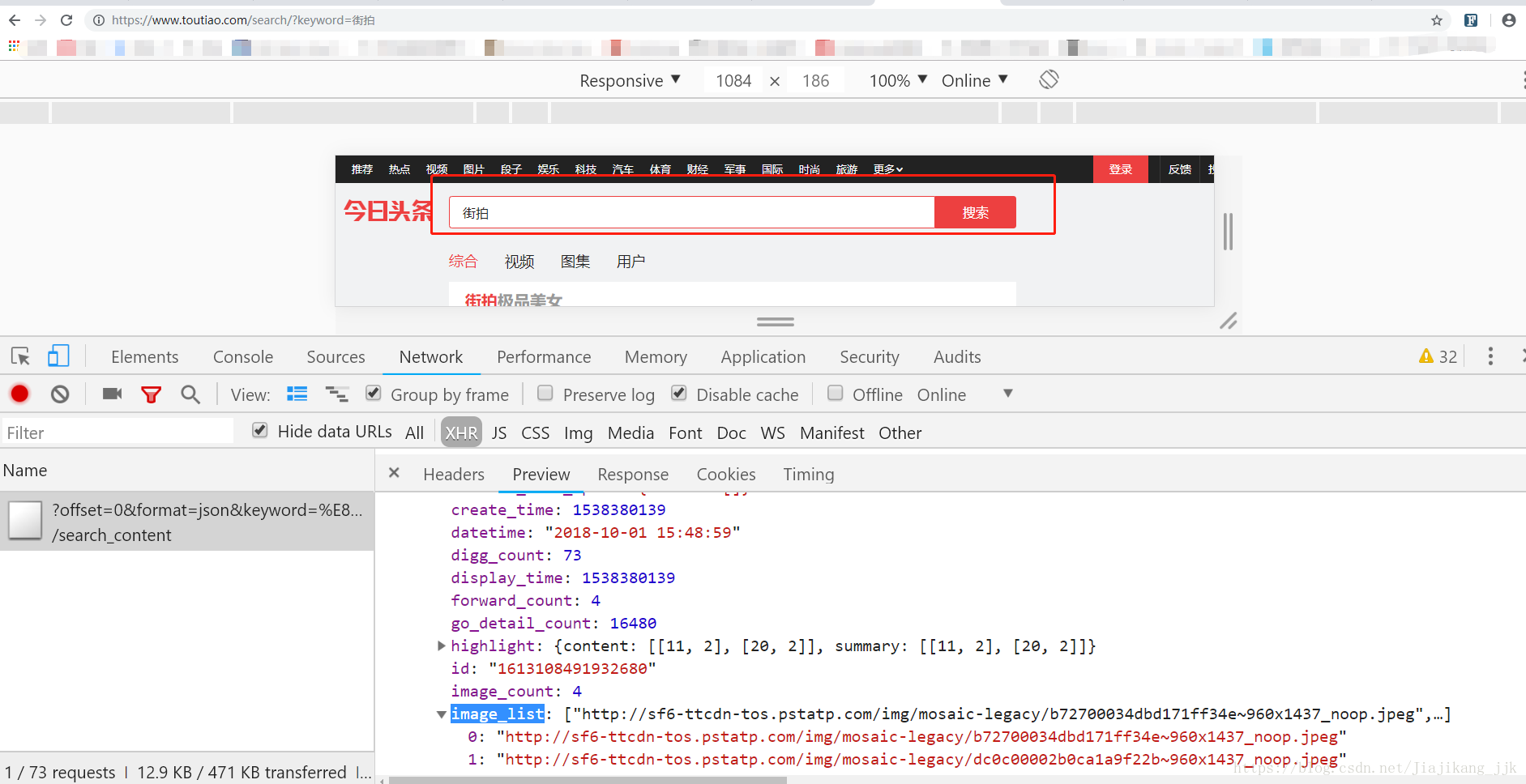
3:搜索街拍
https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
点击XHR以此来确定ajax请求。
获取每条图片的url
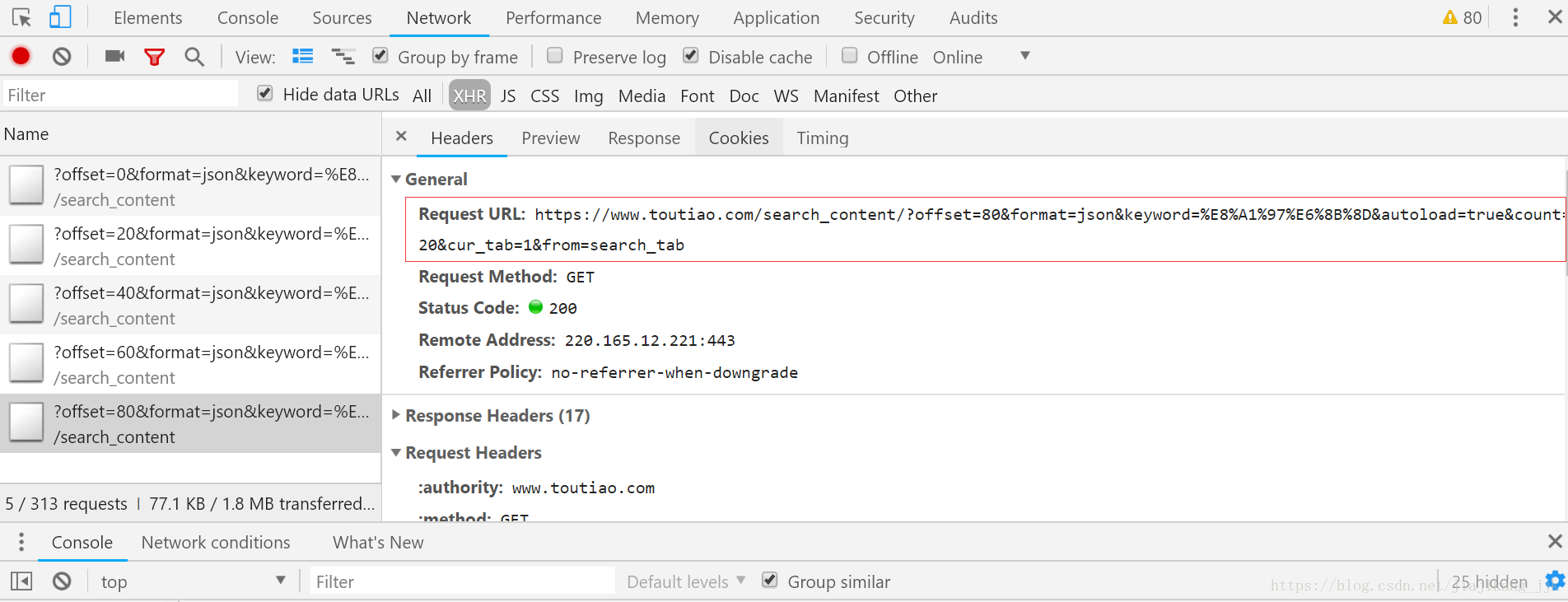
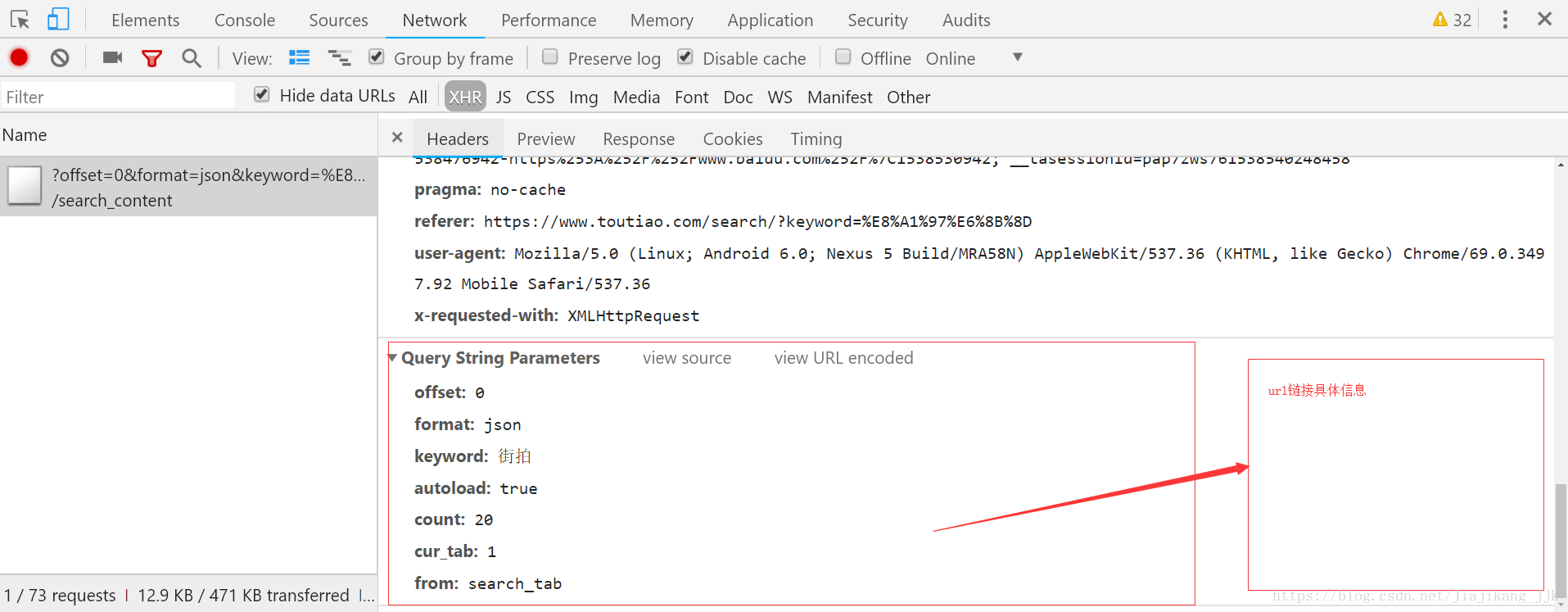
4:分析url的规律
Request URL: https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1&from=search_tab
a:offset=20&
b:format=json&
c:keyword=%E8%A1%97%E6%8B%8D&
d:autoload=true&
e:count=20&
f:cur_tab=1&
g:from=search_tab
进行了多次滚动加载ajax之后,发现所有的url都具有a,b,c,d,e,f,g且只要b在发生变化
变化的规律是:0,20,40,60,,,,,以此可以获得count的参数的个数
5:通过接口获取数据
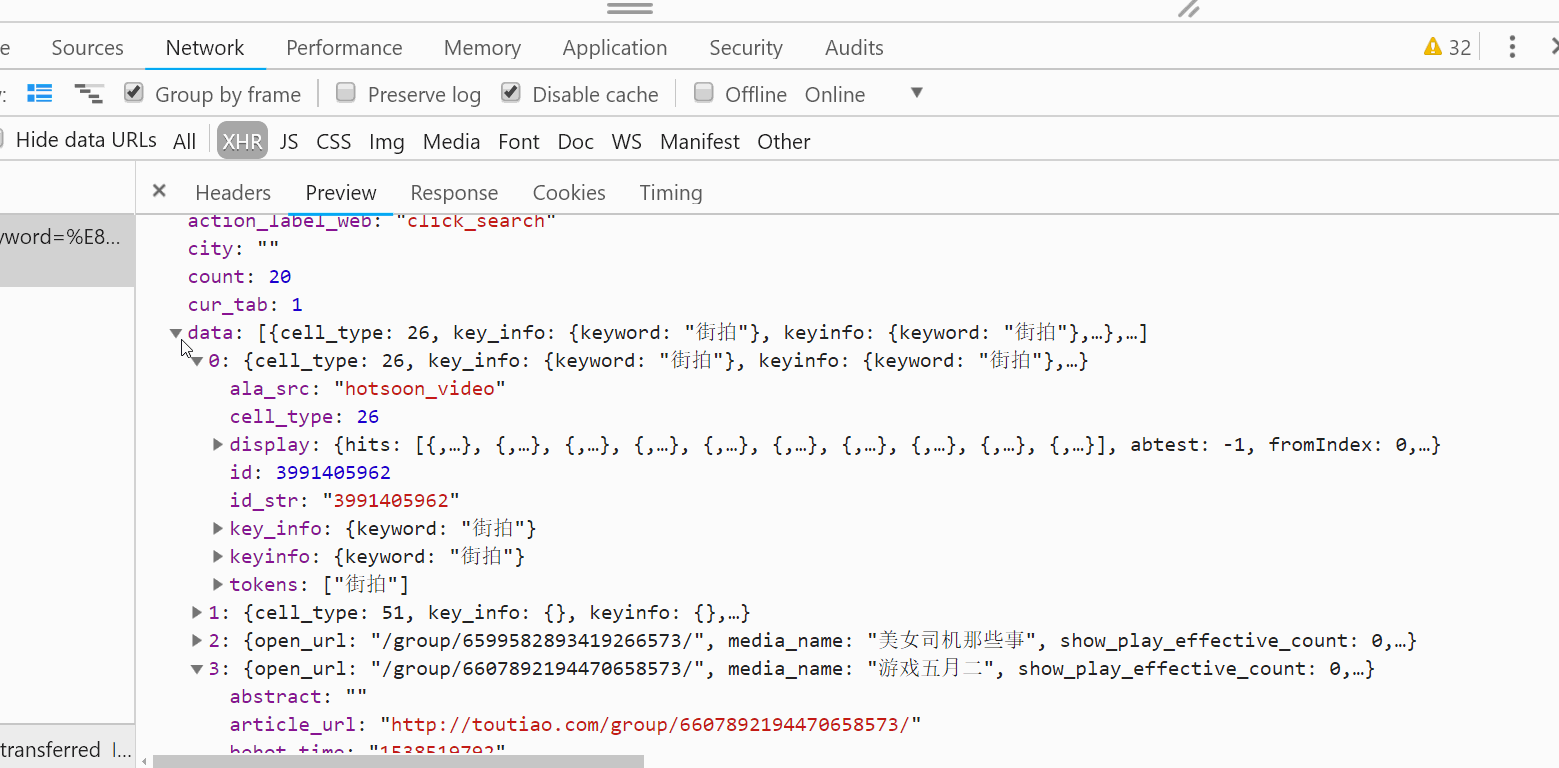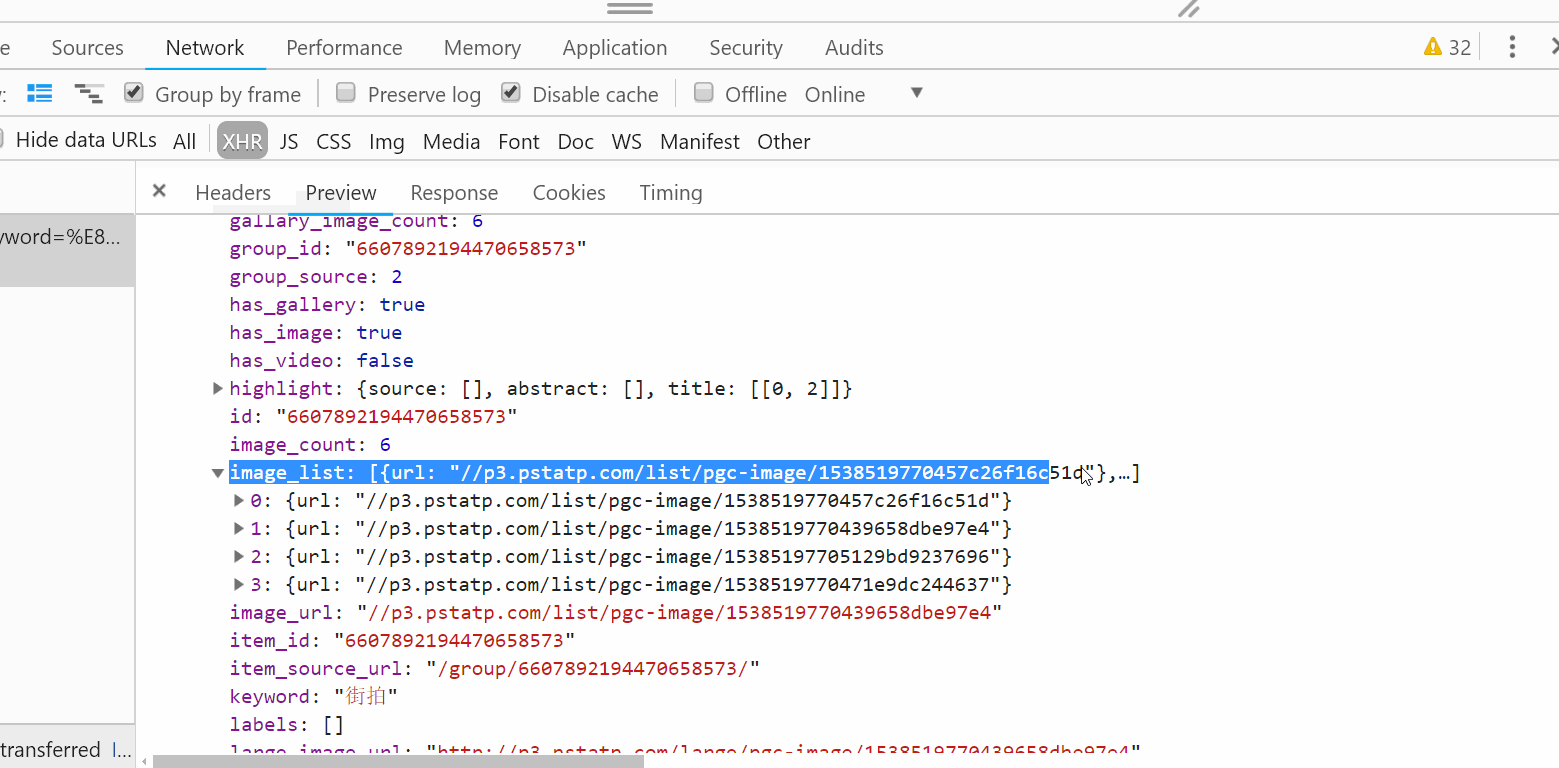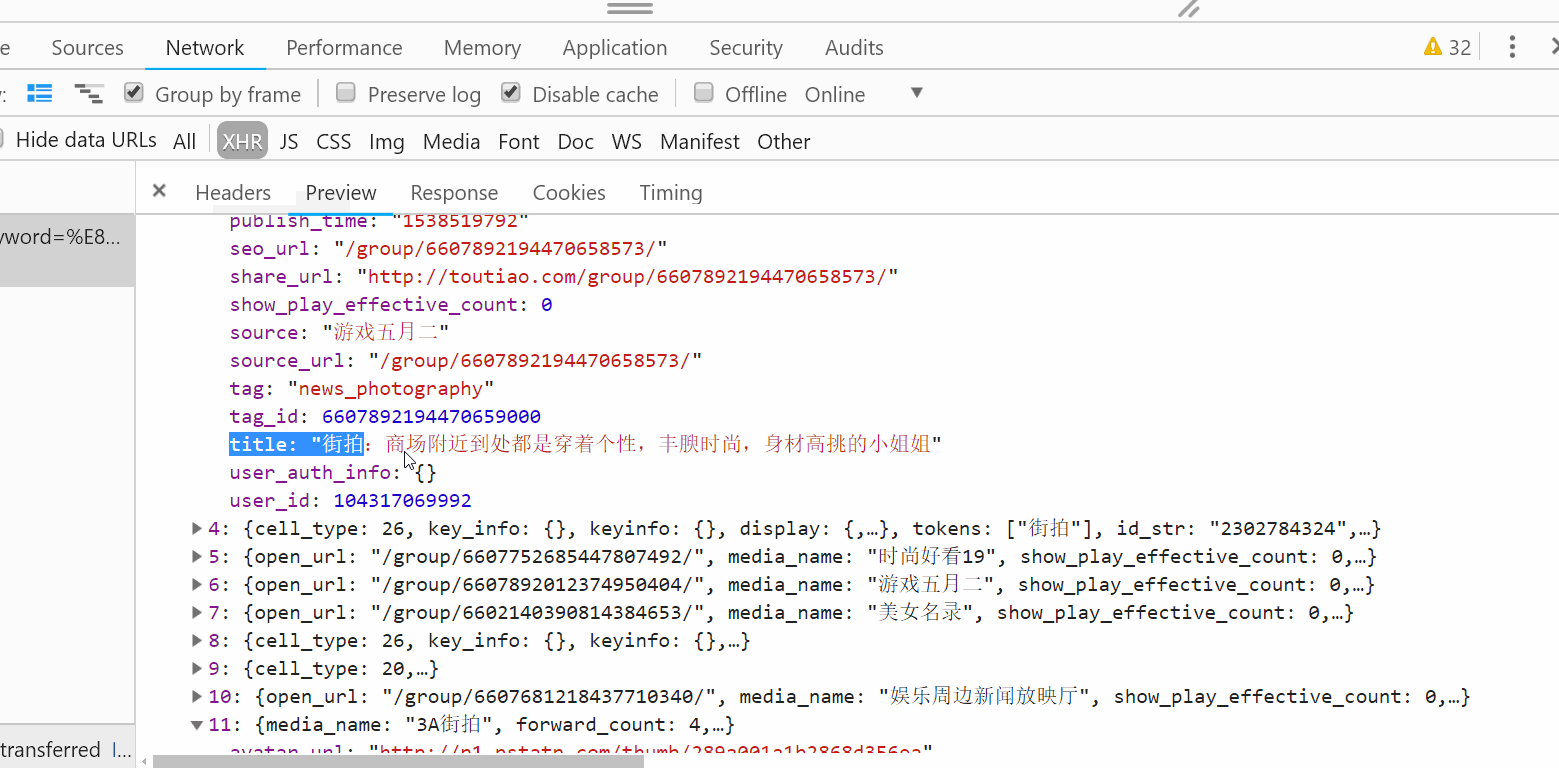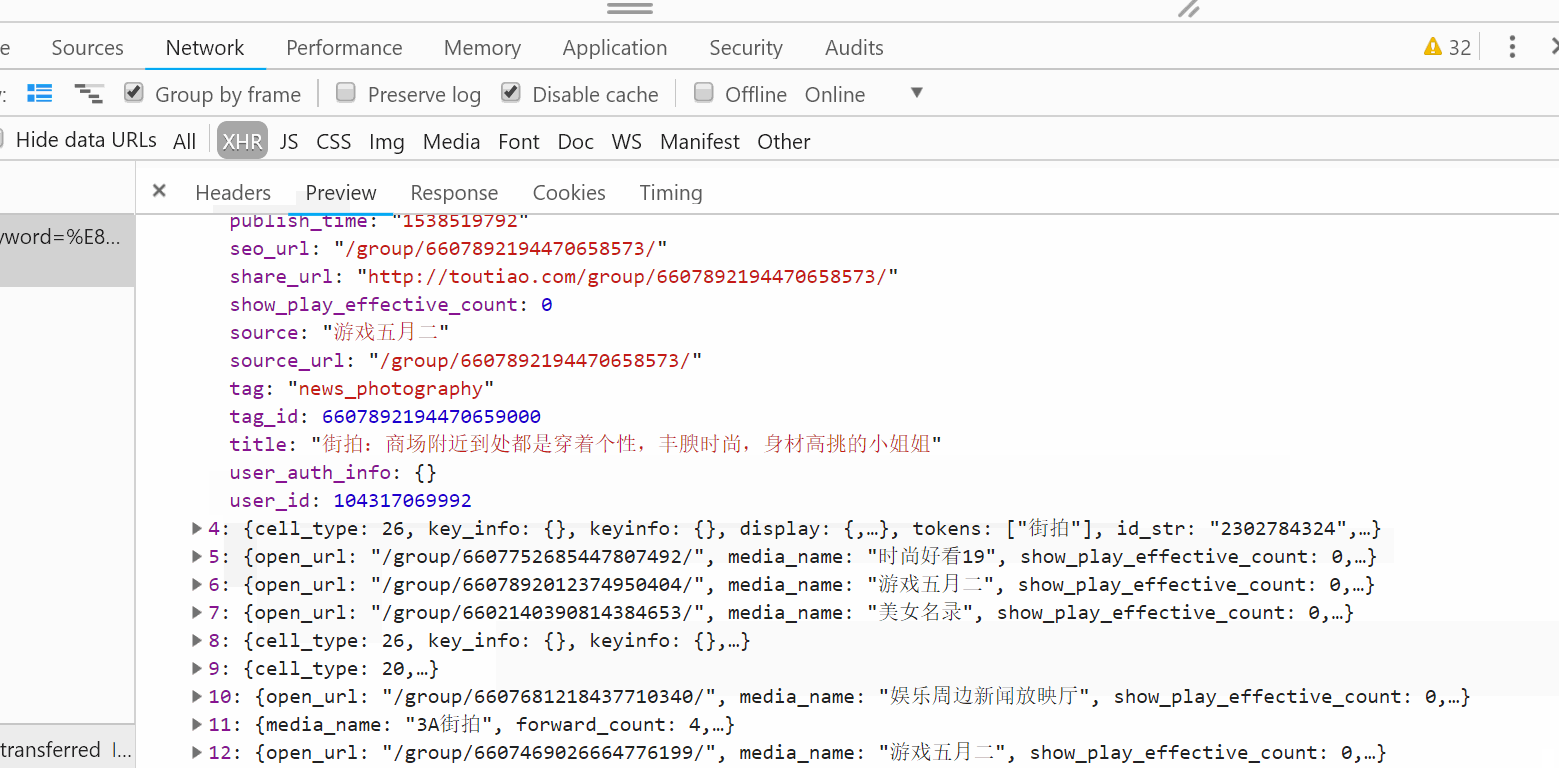
6:解析数据
根据P12查每条数据的image_list的url,返回图片的链接和图片所属的标题。
7:下载保存
构造一个offset数组,遍历offset获取图片的链接,并将其下载
F12获取相关数据
1:今日头条首页
2:爬去链接的首页
3:链接分析
4:解析数据分析
代码
"""
author:jjk
datetime:2018/10/2
coding:utf-8
project name:Pycharm_workstation
Program function: 爬去今日头条的街拍美图--保存到本地
"""
import requests
from urllib.parse import urlencode
from requests import codes
import os
from hashlib import md5
from multiprocessing.pool import Pool
# 第一步:定义get_page()加载单个Ajax请求的结果,使用offset作为参数传递
# 1:get请求,requests请求获取页面
def get_page(offset):
params = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'cur_tab': '1',
'from': 'search_tab'
}
base_url = 'https://www.toutiao.com/search_content/?'# 基础链接
url = base_url + urlencode(params)# 获取完整图片链接
try:
response = requests.get(url)# 获取url
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
# 第二步:解析方法:提取每条数据中image_detail字段中的每一张图片的链接
def get_images(json):
if json.get('data'):# 获取源码中的data
data = json.get('data') # 将获取到的data赋值给data
for item in data:# 遍历data数组
if item.get('cell_type') is not None:# 判断获取的类型不是规范
continue
title = item.get('title')# 获取标题
images = item.get('image_list')# 获取存储图片url列表
for image in images:
yield {
'image':'https:'+ image.get('url'),
'title':title
}
def save_image(item):
# 保存图片路径,os.path.sep:路径分隔符
img_path = 'img' + os.path.sep + item.get('title')
# 如果路径不存在
if not os.path.exists(img_path):
# 以获取的img_path创建目录
os.makedirs(img_path)
try:
response = requests.get(item.get('image'))
if codes.ok == response.status_code:
# 文件路径->图片路径+路径分隔符+格式化
# 请求的内容使用哈希函数自动生成文件名
file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format(
file_name=md5(response.content).hexdigest(),
file_suffix='jpg')
if not os.path.exists(file_path):
# 如果文件路径不存在,以二进制写方式写入内容
with open(file_path, 'wb') as f:
f.write(response.content)
print('Downloaded image path is %s' % file_path)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
# %符号标记转换说明符的开始
print('Failed to Save Image,item %s' % item)
# 第四步:构造一个offset数组,提取图片链接,并将其下载
def main(offset):
json = get_page(offset)# 调用get_page()方法获取请求链接
for item in get_images(json):# 遍历get_images()方法
print(item)
save_image(item)# 保存图片
# 定义一个起始页和一个终止页
GROUP_start = 0
Group_end = 7
# 第五步 执行函数
if __name__ == '__main__':
pool = Pool()
# 以x*20为一组的遍历
groups = ([x * 20 for x in range(GROUP_start,Group_end + 1)])
# map()实现多线程下载
pool.map(main, groups)
# 关闭
pool.close()
# 如果主线程阻塞后,让子进程继续运行完成之后,在关闭所有的主进程
pool.join()
