利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集
-
目标站点分析
今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方法不太一样,对它的抓取需要抓取后台传来的JSON数据,
先来看一下今日头条的源码结构:我们抓取文章的标题,详情页的图片链接试一下:

看到上面的源码了吧,抓取下来没有用,那么我看下它的后台数据:‘
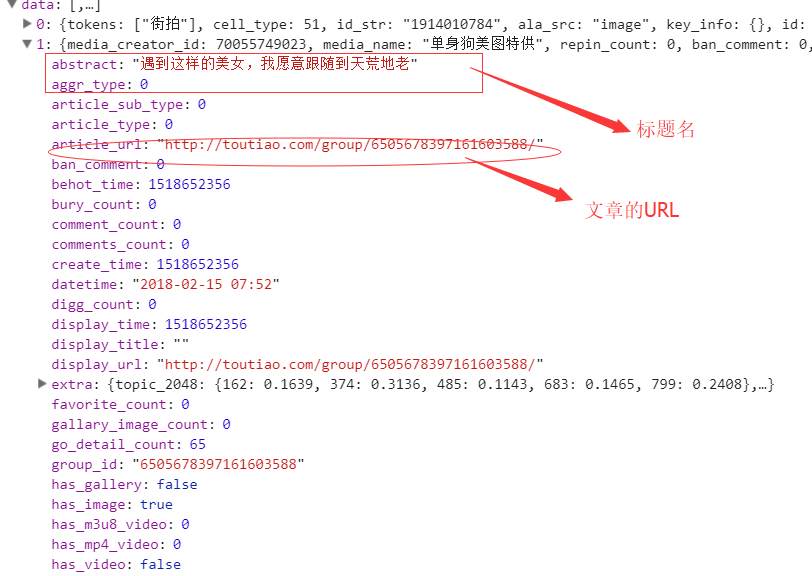
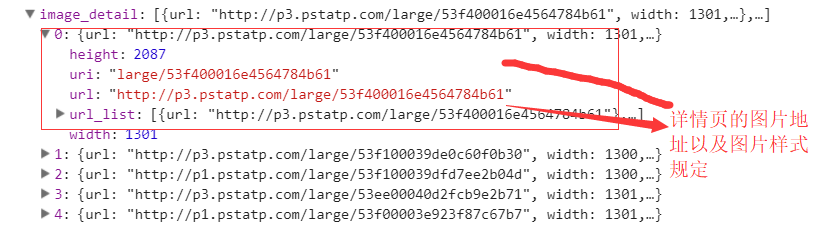
所有的数据都在后台的JSON展示中,所以我们需要通过接口对数据进行抓取


提取网页JSON数据
执行函数结果,如果你想大量抓取记得开启多进程并且存入数据库:

看下结果:

总结一下:网上好多抓取今日头条的案例都是先抓去指定主页,获取文章的URL再通过详情页,接着在详情页上抓取,但是现在的今日头条的网站是这样的,在主页的接口数据中就带有详情页的数据,通过点击跳转携带数据的方式将数据传给详情页的页面模板,这样开发起来方便节省了不少时间并且减少代码量
-
流程框架
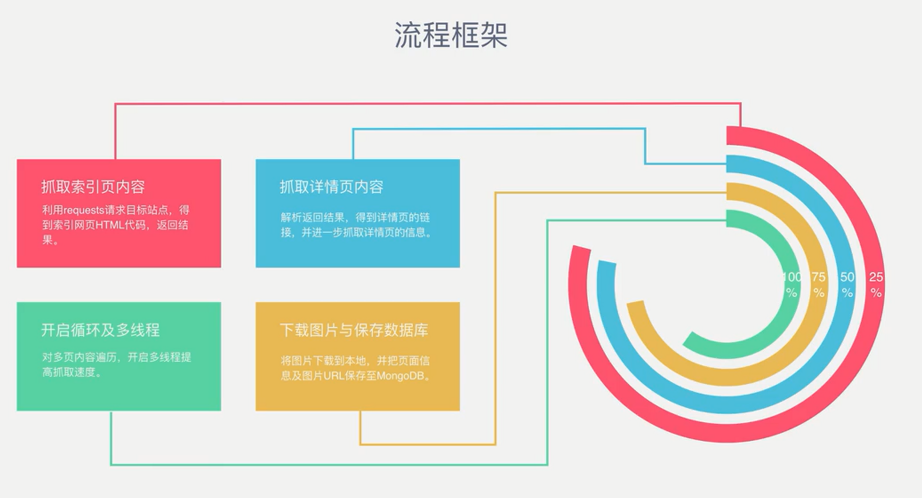
-
爬虫实战