版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/bqw18744018044/article/details/82599034
一、Reuters数据集是一个关于新闻短讯的数据集,其包含了46个互斥的主题,而且每个主题指定包含10个样例。
from keras.datasets import reuters
(train_data,train_labels),(test_data,test_labels) = reuters.load_data(num_words=10000)二、数据集的相关信息
print('the shape of train data is ',train_data.shape)
print('the shape of test data is ',test_data.shape)
print('an example of train data is ',train_data[10])the shape of train data is (8982,)
the shape of test data is (2246,)
an example of train data is [1, 245, 273, 207, 156, 53, 74, 160, 26, 14, 46, 296, 26, 39, 74, 2979, 3554, 14, 46, 4689, 4329, 86, 61, 3499, 4795, 14, 61, 451, 4329, 17, 12]
三、处理数据集
import numpy as np
# 神经网络的输入必须是tensor而不是list,所以需要将数据集处理为25000*8000
def vectorize_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
# one-hot编码
for i,sequence in enumerate(sequences):
results[i,sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)将labels通过to_categorical处理为one-hot编码(如果不使用one-hot编码,而是直接使用原始的label,那么loss function应选择sparse_categorical_crossentropy)
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels) #此时每个标签为一个46维的向量
one_hot_test_labels = to_categorical(test_labels)四、设计网络结构
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
# 对于46分类的问题,隐层的单元不能小于46,因此选择了64
model.add(layers.Dense(64,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(46,activation='softmax')) # 使用softmax输出46个主题的概率
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy', # 多分类问题选择categorical_crossentropy作为loss function,用来衡量预测分布与真实分布的距离
metrics=['accuracy'])
return model
model = build_model()五、划分验证集用于选择超参数epochs
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]六、训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,# 在全数据集上迭代20次
batch_size=512,# 每个batch的大小为512
validation_data=(x_val,y_val))Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 1s 182us/step - loss: 2.5287 - acc: 0.4945 - val_loss: 1.7224 - val_acc: 0.6110
Epoch 2/20
7982/7982 [==============================] - 1s 143us/step - loss: 1.4464 - acc: 0.6885 - val_loss: 1.3466 - val_acc: 0.7090
Epoch 3/20
7982/7982 [==============================] - 1s 142us/step - loss: 1.0951 - acc: 0.7656 - val_loss: 1.1712 - val_acc: 0.7440
Epoch 4/20
7982/7982 [==============================] - 1s 143us/step - loss: 0.8690 - acc: 0.8171 - val_loss: 1.0787 - val_acc: 0.7590
Epoch 5/20
7982/7982 [==============================] - 1s 144us/step - loss: 0.7024 - acc: 0.8480 - val_loss: 0.9848 - val_acc: 0.7840
Epoch 6/20
7982/7982 [==============================] - 1s 146us/step - loss: 0.5654 - acc: 0.8795 - val_loss: 0.9435 - val_acc: 0.8030
Epoch 7/20
7982/7982 [==============================] - 1s 144us/step - loss: 0.4570 - acc: 0.9039 - val_loss: 0.9107 - val_acc: 0.8020
Epoch 8/20
7982/7982 [==============================] - 1s 146us/step - loss: 0.3683 - acc: 0.9237 - val_loss: 0.9341 - val_acc: 0.7920
Epoch 9/20
7982/7982 [==============================] - 1s 144us/step - loss: 0.3019 - acc: 0.9312 - val_loss: 0.8936 - val_acc: 0.8090
Epoch 10/20
7982/7982 [==============================] - 1s 143us/step - loss: 0.2528 - acc: 0.9424 - val_loss: 0.9115 - val_acc: 0.8140
Epoch 11/20
7982/7982 [==============================] - 1s 141us/step - loss: 0.2176 - acc: 0.9476 - val_loss: 0.9180 - val_acc: 0.8110
Epoch 12/20
7982/7982 [==============================] - 1s 143us/step - loss: 0.1867 - acc: 0.9515 - val_loss: 0.9083 - val_acc: 0.8140
Epoch 13/20
7982/7982 [==============================] - 1s 143us/step - loss: 0.1696 - acc: 0.9521 - val_loss: 0.9354 - val_acc: 0.8060
Epoch 14/20
7982/7982 [==============================] - 1s 148us/step - loss: 0.1532 - acc: 0.9557 - val_loss: 0.9683 - val_acc: 0.8040
Epoch 15/20
7982/7982 [==============================] - 1s 158us/step - loss: 0.1387 - acc: 0.9557 - val_loss: 0.9707 - val_acc: 0.8130
Epoch 16/20
7982/7982 [==============================] - 1s 156us/step - loss: 0.1316 - acc: 0.9559 - val_loss: 1.0274 - val_acc: 0.8020
Epoch 17/20
7982/7982 [==============================] - 1s 157us/step - loss: 0.1217 - acc: 0.9577 - val_loss: 1.0270 - val_acc: 0.7970
Epoch 18/20
7982/7982 [==============================] - 1s 155us/step - loss: 0.1201 - acc: 0.9574 - val_loss: 1.0417 - val_acc: 0.8050
Epoch 19/20
7982/7982 [==============================] - 1s 156us/step - loss: 0.1141 - acc: 0.9588 - val_loss: 1.0975 - val_acc: 0.7990
Epoch 20/20
7982/7982 [==============================] - 1s 156us/step - loss: 0.1114 - acc: 0.9594 - val_loss: 1.0732 - val_acc: 0.8010
七、绘制loss和accuracy
x轴为epochs,y轴为loss
import matplotlib.pyplot as plt
%matplotlib inline
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()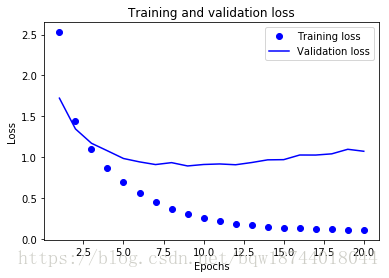
x轴为epochs,y轴为accuracy
plt.clf()
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.plot(epochs,acc,'bo',label='Training acc')
plt.plot(epochs,val_acc,'b',label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
八、选择合适的超参数,然后在所有训练集上重新训练模型
model.fit(partial_x_train,
partial_y_train,
epochs=9,# # 由loss图发现在epochs=9的位置上validation loss最低
batch_size=512,# 每个batch的大小为512
validation_data=(x_val,y_val))Train on 7982 samples, validate on 1000 samples
Epoch 1/9
7982/7982 [==============================] - 1s 149us/step - loss: 0.1060 - acc: 0.9568 - val_loss: 1.1084 - val_acc: 0.7970
Epoch 2/9
7982/7982 [==============================] - 1s 146us/step - loss: 0.1026 - acc: 0.9582 - val_loss: 1.1170 - val_acc: 0.8000
Epoch 3/9
7982/7982 [==============================] - 1s 143us/step - loss: 0.1029 - acc: 0.9593 - val_loss: 1.1004 - val_acc: 0.7950
Epoch 4/9
7982/7982 [==============================] - 1s 144us/step - loss: 0.1036 - acc: 0.9577 - val_loss: 1.1245 - val_acc: 0.7960
Epoch 5/9
7982/7982 [==============================] - 1s 144us/step - loss: 0.0977 - acc: 0.9585 - val_loss: 1.1591 - val_acc: 0.8030
Epoch 6/9
7982/7982 [==============================] - 1s 143us/step - loss: 0.0997 - acc: 0.9564 - val_loss: 1.2357 - val_acc: 0.7900
Epoch 7/9
7982/7982 [==============================] - 1s 144us/step - loss: 0.0969 - acc: 0.9577 - val_loss: 1.1817 - val_acc: 0.7960
Epoch 8/9
7982/7982 [==============================] - 1s 146us/step - loss: 0.0931 - acc: 0.9593 - val_loss: 1.2373 - val_acc: 0.7800
Epoch 9/9
7982/7982 [==============================] - 1s 144us/step - loss: 0.0958 - acc: 0.9584 - val_loss: 1.1882 - val_acc: 0.7970
<keras.callbacks.History at 0x7f2b844a1cf8>
评估模型在测试集上的loss和accuracy
results = model.evaluate(x_test,one_hot_test_labels)
results[1.3601689705971831, 0.7800534283700843]
九、生成预测值
predictions = model.predict(x_test)
print(predictions[0].shape)# 第0个样本预测值
print(np.sum(predictions[0]))# 所有预测值的和为1
print(np.argmax(predictions[0])) # 46个维度中最大的是第3个维度,即其属于第3个主题(46,)
0.9999999
3