机器学习中常用的性能度量(评价指标)
混淆矩阵
在了解这几个常用指标之前,首先我们先了解一下混淆矩阵。
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。

如图所示,混淆矩阵中包含以下四种数据:真正(True Positive , TP): 被模型预测为正的正样本;假正(False Positive , FP):被模型预测为正的负样本;假负(False Negative , FN):被模型预测为负的正样本;真负(True Negative , TN):被模型预测为负的负样本。
假设给定的样本集为D={(x1,y1 ),(x2,y2 ),…,(xm,ym )},共计m 个样本,使用机器学习算法预测的结果为f(x),那么对于评价其预测性能f就是将预测结果f(x)与真实的标记ground truth做比较。
精度
所谓精度(accuracy),顾名思义就是指在机器学习的算法预测之后,预测正确了的样本占总样本的比例,计算公式如下:
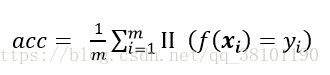
错误率
所谓错误率(error rate),是指在机器学习算法预测之后,分错的样本占样本总数的比例,计算公式如下:
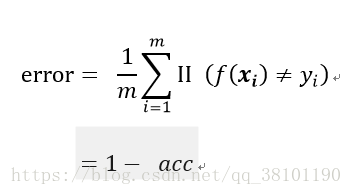
查准率(Precision,P)
查准率(Precision, P)表示被分为正例的示例当中实际值为正例的比例,其计算公式如下式:
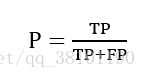
查全率(Recall,R)
查全率又称为召回率,其是覆盖面的度量,度量正例被分为正例的比例,其计算公式如下:
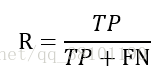
F-measure
当查准率P和查全率R指标出现矛盾的时候,这就需要综合考虑他们,最常见方法就是 F-Measure(即F-Score)。它是P和R的加权调和平均(越大越好), 比P-R曲线平衡点更常用。F1是F-measure的特例,其计算公式如下:
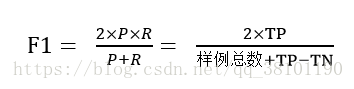
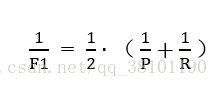
扫描二维码关注公众号,回复:
3506287 查看本文章
