提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、 关于导入库和导入函数
import 模块:导入一个模块,注:相当于导入的是一个文件夹,每次使用模块中的函数都要确定引用
from…import XX:导入的是一个模块中的一个函数;注:相当于导入的是一个文件夹中的文件,是绝对路径
from…import * :是把一个模块中所有的函数都导入进来, 注:相当于导入的是一个文件夹中的所有文件,所有函数都是绝对路径
二、有关两个评价指标(Top-5错误率与Top-1错误率)
1.Top-5错误率
即对一个图片,如果概率前五中包含正确答案,即认为正确。
2.Top-1错误率
即对一个图片,如果概率最大的是正确答案,才认为正确。
ImageNet 举办一年一度的软件竞赛,叫做(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。主要内容是通过算法程序实现正确分类和探测识别物体与场景,评价标准就是Top-5 错误率。
三、confusion matrix 混淆矩阵、ROC曲线、AUC
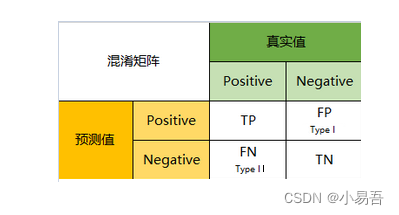
1.confusion matrix 混淆矩阵
混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第二类错误(Type II Error)
真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第一类错误(Type I Error)
真实值是negative,模型认为是negative的数量(True Negative=TN)
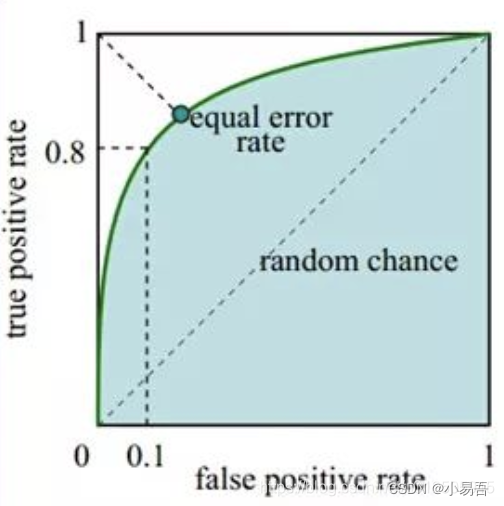
2.ROC曲线
受试者工作特征曲线ROC就是以假阳性概率(False positive rate)为横轴,真阳性(True positive rate)为纵轴所组成的坐标图。
真正例率(True Positive Rate,简称TPR):表示当前预测为正样本的数据中,真实的正样本占所有正样本的比例
TPR = TP / (TP + FN)
假正例率(False Positive Rate,简称FPR):表示当前被分到正样本的数据中,真实的负样本占所有负样本的比例。
FPR = FP / (TN + FP)
据模型的预测结果对样本进行排序,按顺序逐个把样本作为正样本进行预测,每次计算出TPR和FPT,分别以FPR为横坐标、以TPR为纵坐标作图,就得到了ROC曲线。ROC曲线示意图如下:
3.AUC
AUC (Area under Curve):ROC 曲线下的面积,介于 0.1 和 1 之间,作为数值可以直观的评价分类器的好坏,值越大越好。
AUC 值作为评价标准,被定义为 ROC 曲线下的面积,取值范围一般在 0.5 和 1 之间。使用AUC 值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应 AUC 更大的分类器效果更好。
AUC 的常用计算方法有:
(1) 梯形法则:早期由于测试样本有限,我们得到的 AUC 曲线呈阶梯状。曲线上的每个点向 X 轴做垂线,得到若干梯形,这些梯形面积之和也就是 AUC;
(2) Mann-Whitney 统计量: 统计正负样本对中,有多少个组中的正样本的概率大于负样本的概率。这种估计随着样本规模的扩大而逐渐逼近真实值。
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
居中的图片: 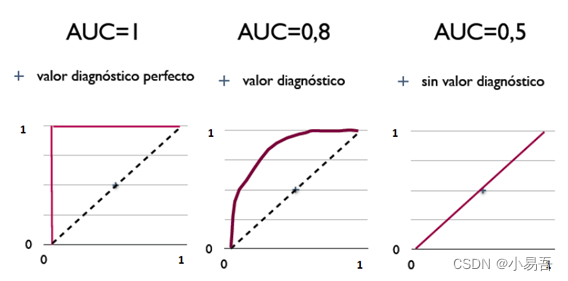
总结
本文深度学习的一些零碎知识点进行了部分整理,在后续学习中还会不断完善和补充。