过拟合和欠拟合
机器学习模型在训练数据集上表现出的误差叫做训练误差,在任意一个测试数据样本上表现出的误差的期望值叫做泛化误差。
欠拟合under-fitting:机器学习模型无法得到较低训练误差。
过拟合over-fitting:机器学习模型的训练误差远小于其在测试数据集上的误差。
但是训练误差的降低不一定意味着泛化误差的降低。机器学习既需要降低训练误差,又需要降低泛化误差。
图像表示
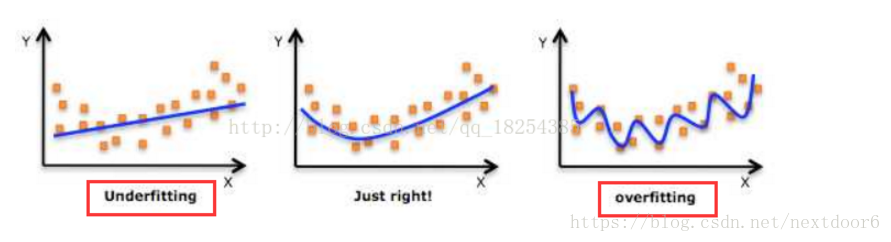
过拟合的解决方法
1.数据清洗,得到较纯的数据。
一般在对数据进行训练前,首先会对数据进行处理,处理的具体方法后续章节补充。
2.增加训练的数据量。
3.采用正则化方法。
采用正则化方法是在损失函数后面加入正则化惩罚项因子,在这里λ我们称做正则化参数。而通过调整λ 这个正则化参数的大小,进而达成平衡拟合训练的目标和保持参数值较小的目标。当最小化J(θ)时,λ 越大,θ越小,所以通过调节λ的值可以调节θ的大小从而调节拟合的程度,λ过大会导致欠拟合,过小会导致过拟合。
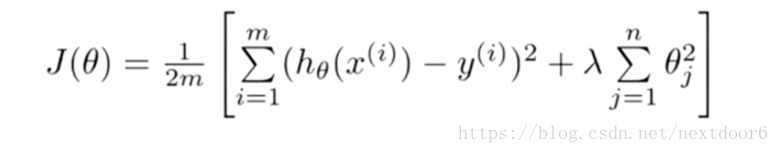
4.采用dropout方法。
样本不均衡时解决方式
上采样/下采样
下采样,对于一个不均衡的数据,让目标值(如0和1分类)中的样本数据量相同,且以数据量少的一方的样本数量为准。上采样就是以数据量多的一方的样本数量为标准,把样本数量较少的类的样本数量生成和样本数量多的一方相同,称为上采样。
下采样
获取数据时一般是从分类样本多的数据从随机抽取等数量的yang样本。
人工合成数据策略
SMOTE全称是Synthetic Minority Oversampling Technique即合成少数类过采样技术。,SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中 。
算法流程如下: 1. 对于少数类中的每一个样本xx,用欧式距离为标准计算它到少数类样本集SminSmin中所有样本的距离,得到其k近邻 2. 确定采样倍率NN,对于每一个少数类样本xx,从其k近邻中随机选择若干个样本,假设选择的近邻为x^x^ 3. 对于每一个随机选出的近邻x^x^,分别与原样本按照如下的公式构建新的样本 xnew=x+rand(0,1)∗(x^−x)
生成样本的数量和分类样本较多的数据量保持一致一致。