目标检测算法中,因为产生的备选框特别多,需要删减。而删减的方法是NMS(非极大抑制算法)。网上很多算法是自己编写功能代码。但是这不是tensorflow中自带的功能,所以在使用tensorflow恢复模型的时候,sess并不能hold住他们。因此别人需要用的时候,还需要额外的配置这些代码,如果采用TensorFlow自带的一些功能,那么调用pb文件的时候就可以直接实现一步到位的结果。下面结合一下YOLO3中的yolo_predict中的代码,介绍一下tensorflow中对目标检测算法比较常见的一些功能。
def predict(self, inputs, image_shape):
"""
Introduction
------------
构建预测模型
Parameters
----------
inputs: 处理之后的输入图片
image_shape: 图像原始大小
Returns
-------
boxes: 物体框坐标
scores: 物体概率值
classes: 物体类别
"""
model = yolo(config.norm_epsilon, config.norm_decay, self.anchors_path, self.classes_path, pre_train = False)
output = model.yolo_inference(inputs, config.num_anchors // 3, config.num_classes, training = False)
boxes, scores, classes = self.eval(output, image_shape, max_boxes = 20)
return boxes, scores, classes在经过model.yolo_inference()后,是输出的三个Tensor,这在我之前的一篇文章里面有过介绍。但是生成的备选框和每个备选框对应的分数太多。我们需要通过自己设定的threshold进行赛选。这个赛选就是通过eval()方法实现的。
def eval(self, yolo_outputs, image_shape, max_boxes = 20):
"""
Introduction
------------
根据Yolo模型的输出进行非极大值抑制,获取最后的物体检测框和物体检测类别
Parameters
----------
yolo_outputs: yolo模型输出
image_shape: 图片的大小
max_boxes: 最大box数量
Returns
-------
boxes_: 物体框的位置
scores_: 物体类别的概率
classes_: 物体类别
"""
anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
boxes = []
box_scores = []
input_shape = tf.shape(yolo_outputs[0])[1 : 3] * 32
# 对三个尺度的输出获取每个预测box坐标和box的分数,score计算为置信度x类别概率
for i in range(len(yolo_outputs)):
_boxes, _box_scores = self.boxes_and_scores(yolo_outputs[i], self.anchors[anchor_mask[i]], len(self.class_names), input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
boxes = tf.concat(boxes, axis = 0)
box_scores = tf.concat(box_scores, axis = 0)
mask = box_scores >= self.obj_threshold
max_boxes_tensor = tf.constant(max_boxes, dtype = tf.int32)
boxes_ = []
scores_ = []
classes_ = []
for c in range(len(self.class_names)):
class_boxes = tf.boolean_mask(boxes, mask[:, c])
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
nms_index = tf.image.non_max_suppression(class_boxes, class_box_scores, max_boxes_tensor, iou_threshold = self.nms_threshold)
class_boxes = tf.gather(class_boxes, nms_index)
class_box_scores = tf.gather(class_box_scores, nms_index)
classes = tf.ones_like(class_box_scores, 'int32') * c
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
boxes_ = tf.concat(boxes_, axis = 0)
scores_ = tf.concat(scores_, axis = 0)
classes_ = tf.concat(classes_, axis = 0)
return boxes_, scores_, classes_1. tf.shape():
这个不用多说了,就是获取tensor的维度。
input_shape = tf.shape(yolo_outputs[0])[1 : 3] * 32
这句代码就是恢复darknet网络输入的图片尺寸(这里相对于原图尺寸也是经过resize的)。下面经过三次循环,分别求出尺寸为13,26,52的Tensor对应的备选框和分数进行赛选。从而程序进入:
def boxes_and_scores(self, feats, anchors, classes_num, input_shape, image_shape):
def boxes_and_scores(self, feats, anchors, classes_num, input_shape, image_shape):
"""
Introduction
------------
将预测出的box坐标转换为对应原图的坐标,然后计算每个box的分数
Parameters
----------
feats: yolo输出的feature map
anchors: anchor的位置
class_num: 类别数目
input_shape: 输入大小
image_shape: 图片大小
Returns
-------
boxes: 物体框的位置
boxes_scores: 物体框的分数,为置信度和类别概率的乘积
"""
box_xy, box_wh, box_confidence, box_class_probs = self._get_feats(feats, anchors, classes_num, input_shape)
boxes = self.correct_boxes(box_xy, box_wh, input_shape, image_shape)
boxes = tf.reshape(boxes, [-1, 4])
box_scores = box_confidence * box_class_probs
box_scores = tf.reshape(box_scores, [-1, classes_num])
return boxes, box_scores接着进入:
def _get_feats(self, feats, anchors, num_classes, input_shape):
def _get_feats(self, feats, anchors, num_classes, input_shape):
"""
Introduction
------------
根据yolo最后一层的输出确定bounding box
Parameters
----------
feats: yolo模型最后一层输出
anchors: anchors的位置
num_classes: 类别数量
input_shape: 输入大小
Returns
-------
box_xy, box_wh, box_confidence, box_class_probs
"""
num_anchors = len(anchors)
anchors_tensor = tf.reshape(tf.constant(anchors, dtype=tf.float32), [1, 1, 1, num_anchors, 2])
grid_size = tf.shape(feats)[1:3]
predictions = tf.reshape(feats, [-1, grid_size[0], grid_size[1], num_anchors, num_classes + 5])
# 这里构建13*13*1*2的矩阵,对应每个格子加上对应的坐标
grid_y = tf.tile(tf.reshape(tf.range(grid_size[0]), [-1, 1, 1, 1]), [1, grid_size[1], 1, 1])
grid_x = tf.tile(tf.reshape(tf.range(grid_size[1]), [1, -1, 1, 1]), [grid_size[0], 1, 1, 1])
grid = tf.concat([grid_x, grid_y], axis=-1)
grid = tf.cast(grid, tf.float32)
# 将x,y坐标归一化为占416的比例
box_xy = (tf.sigmoid(predictions[..., :2]) + grid) / tf.cast(grid_size[::-1], tf.float32)
# 将w,h也归一化为占416的比例
box_wh = tf.exp(predictions[..., 2:4]) * anchors_tensor / tf.cast(input_shape[::-1], tf.float32)
box_confidence = tf.sigmoid(predictions[..., 4:5])
box_class_probs = tf.sigmoid(predictions[..., 5:])
return box_xy, box_wh, box_confidence, box_class_probs
2. tf.range():
进入函数内部可以看到其定义为: range(start, limit=None, delta=1, dtype=None, name="range"):就是产生一个等差数列。delta为步子的大小。以尺寸为13的那个Tensor来讲tf.range(13) = [0,1,2,...,...,12].
3. tf.title()
tf.tile()应用于需要张量扩展的场景,具体说来就是:
如果现有一个形状如[width, height]的张量,需要得到一个基于原张量的,形状如[batch_size,width,height]的张量,其中每一个batch的内容都和原张量一模一样(引用自)
最终形成了gridx = gridy =[13,13,1,1],grid = tf.cast(grid,tf.float32).,其shape = (13,13,1,2),表示在13*13的矩阵,其channel为1,每一个channel里面有两个数据表示也就是他们的坐标值。
然后通过yolo的特征图到darknet的输入图直接的映射关系,输出备选框在输入图像的坐标和长宽,每一个框的置信度以及类别分数。
随后程序进入:
def correct_boxes(self, box_xy, box_wh, input_shape, image_shape):
def correct_boxes(self, box_xy, box_wh, input_shape, image_shape):
"""
Introduction
------------
计算物体框预测坐标在原图中的位置坐标
Parameters
----------
box_xy: 物体框左上角坐标
box_wh: 物体框的宽高
input_shape: 输入的大小
image_shape: 图片的大小
Returns
-------
boxes: 物体框的位置
"""
box_yx = box_xy[..., ::-1]
box_hw = box_wh[..., ::-1]
input_shape = tf.cast(input_shape, dtype = tf.float32)
image_shape = tf.cast(image_shape, dtype = tf.float32)
new_shape = tf.round(image_shape * tf.reduce_min(input_shape / image_shape))
offset = (input_shape - new_shape) / 2. / input_shape
scale = input_shape / new_shape
box_yx = (box_yx - offset) * scale
box_hw *= scale
box_mins = box_yx - (box_hw / 2.)
box_maxes = box_yx + (box_hw / 2.)
boxes = tf.concat([
box_mins[..., 0:1],
box_mins[..., 1:2],
box_maxes[..., 0:1],
box_maxes[..., 1:2]
], axis = -1)
boxes *= tf.concat([image_shape, image_shape], axis = -1)
return boxes这个函数主要是计算了从输入图像尺寸到原图的映射。
4:tf.round():
四舍五入的函数,切输入必须是浮点型。
再次回到eval函数,此后经过三次循环,把输出的所有框和框对应的类的分数信息都分别加入到了boxes和box_scores.
然后对box_scores的分数大于threshold的进行赛选留下。
5:tf.boolean_mask():
这个函数的作用就是对通过threshold的box_scores和boxses进行保留。其作用可参考该文章
6:tf.image.non_max_suppression():
这个就是TensorFlow自带的计算NMS的函数。非常方便。
7:gather(params, indices, validate_indices=None, name=None, axis=0)
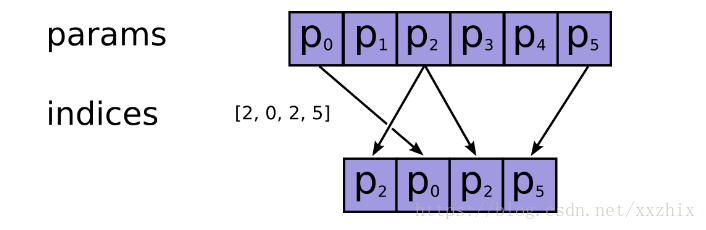
这张图很清楚了解释了该函数的用法。
8:tf.ones_like():
创建一个将所有元素都设置为1的Tensor。