https://zhuanlan.zhihu.com/p/36794078
如何减少泛化误差,是机器学习的核心问题。这篇文章首先将从六个角度去探讨什么是泛化能力,接着讲述有那些提高泛化能力的方法,这些正则化方法可以怎样进行分类,最后会通过讲述一篇论文,来说明目前的正则化方法在解释深度神经泛化能力方面的问题。本文假设读者对深度学习具有基本的了解,清楚卷积神经网络的前向传播和训练过程。如何提高泛化能力是一个面试中常见的问题,由于这个问题有太多的答案,如何有条理的组织自己的回答,本文第二部分可以供参考。
泛化能力最直接的定义是训练数据和真实数据间的差异,训练模型的目地是要模型在完全陌生的数据上进行测试的。因此在进行交叉验证的时候,要保证测试集和训练集有相同的数据分布。而当测试集和训练集本身的分布就不一致的时候,则可以使用将训练集和测试集混合的Adversarial Validation来应对。
泛化能力还可以看成模型的稀疏性。正如奥斯姆的剪刀指出的,面对不同的解释时,最简单的解释是最好的解释。在机器学习中,具有泛化能力的模型中应该有很多参数是接近0的。而在深度学习中,则是待优化的矩阵应该对稀疏性有偏好性。
泛化能力的第三种解释是生成模型中的高保真能力。具有泛化能力的模型应在其每个抽象层次具有重构特征的能力。第四种解释是模型能够有效的忽视琐碎的特征,或者说在无关的变化下都能找到相同的特征。比如CNN就能够忽视其关注特征所在的位置,而capsule网络则能够忽略特征是否旋转。去除掉越来越多的无关特征后,才能保证模型对真正在意的特征的准确生成能力。这和上述的第三点是相辅相成的。
泛化能力还可以看成模型的信息压缩能力。这里涉及到解释为什么深度学习有效的一种假说,信息瓶颈(information bottleneck),说的是一个模型对特征进行压缩(降维)的能力越强,其就越更大的可能性做出准确的分类。信息压缩能力可以概括上述的四种关于泛化能力的解释,稀疏的模型因其结构而完成了信息的压缩,生成能力强,泛化误差低的模型因信息压缩而可能,而忽略无关特征是信息压缩的副产品。
理解泛化能力的最后一种角度是风险最小化。这是从博弈论的角度来看,泛化能力强的模型能尽可能降低自己在真实环境中遇到意外的风险,因此会在内部产生对未知特征的预警机制,并提前做好应对预案。这是一种很抽象的也不那么精确的解释,但随着技术的进步,人们会找出在该解释下进行模型泛化能力的量化评价方法。
当然,以上的6种对泛化能力的解释不是全部说的通的解释,未来会有更多理解泛化能力的角度。对同一个概念理解的越深,达到其的可能道路就越多,接下来让我们看看怎么做才能提高泛化能力。

在机器学习中,正则化很容易理解,不管是L1还是L2,都是针对模型中参数过大的问题引入惩罚项。而在深度学习中,要优化的变成了一个个矩阵,参数变得多出了几个数量级,过拟合的可能性也相应的提高了。而要惩罚的是神经网络中每个神经元的权重大小,从而避免网络中的神经元走极端抄近路。
最直接的正则化是在损失函数中加入惩罚项,比如L2正则化,又称权重衰减(weight decay)关注的是权重平方和的平方根,是要网络中的权重接近0但不等于0,而在L1正则中,要关注的是权重的绝对值,权重可能被压缩成0。在深度学习中,L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。神经网络需要每一层的神经元尽可能的提取出有意义的特征,而这些特征不能是无源之水,因此L2正则用的多一些。
而深度学习中最常用的正则化技术是dropout,随机的丢掉一些神经元。类似的方法是drop link,即随机的丢掉一些网络中的连接。丢掉的神经元既可以在隐藏层,也可以在输入层。dropout是一种将模型进行集成的算法,每一个不完整的网络,都可以看成是一个弱分类器。由于要引入随机性,dropout适合本身就相对复杂的网络,一个三个隐藏神经元的三层神经网络就不要让神经元随机的耍大牌了。
另一个增加模型泛化能力的方法是数据增强,比如将原始图像翻转平移拉伸,从而是模型的训练数据集增大。数据增强已经是深度学习的必需步骤了,其对于模型的泛化能力增加普遍有效,但是不必做的太过,将原始数据量通过数据增加增加到2倍可以,但增加十倍百倍就只是增加了训练所需的时间,不会继续增加模型的泛化能力了。

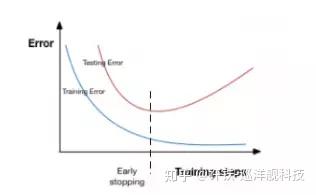
另一个增加泛化能力的方法是提前停止(early stopping),就是让模型在训练的差不多的时候就停下来,比如继续训练带来提升不大或者连续几轮训练都不带来提升的时候,这样可以避免只是改进了训练集的指标但降低了测试集的指标。
最后一个改善模型泛化能力的方式是批量正则化(BN),就是将卷积神经网络的每层之间加上将神经元的权重调成标准正态分布的正则化层,这样可以让每一层的训练都从相似的起点出发,而对权重进行拉伸,等价于对特征进行拉伸,在输入层等价于数据增强。注意正则化层是不需要训练。
除了上述的四种方法,权重共享,随机梯度下降及其改进方法,例如Adam,都可以看做是另一种正则化的方法。而我还脑洞过一种正则化的方法,在卷积网络中的pooling层,可以做average pooling,也可以做max pooling,能不能在池化层引入随机性,在每次训练时一定比例的池化层神经员做max pooling,另外的做average pooling。这个方法是集成模型的套路,将不同的池化策略看成弱分类器的区别。当然我还没有试验过这样的方法,但由于池化层的影响不大,所以对这个方法的效果不乐观。
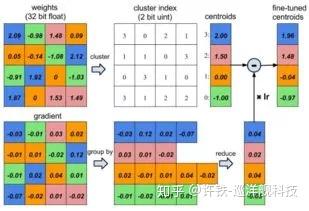
权重共享的示意图,就是神经员去模仿周围神经元的权重。
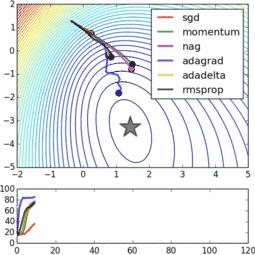
随机梯度下降的动态示意图,通过引入随机性避免局部最优,也可看成通过引入随机项来避免模型中的参数过大(回忆统计学中均值回归,说的是两诺贝尔奖得主的子女智商很大可能要比他们的父母低,因为他们的父母碰巧拿到了影响智商的随机项中的最高值,而他们的后代从概率上不应该还是这么幸运)
正则化的方法,可以分为显式的和隐式的,前者的目的就是提高泛化能力,包括dropout,drop link,权重共享,数据增强,L1和L2惩罚项。结合泛化能力的六个解释,Drop Connect 和 Dropout 相似的地方在于它涉及在模型中引入稀疏性,不同之处在于drop connect引入的是权重的稀疏性而不是层的输出向量的稀疏性,权重共享和数据增强对应的忽视无关的细节,L1正则是增加模型的稀疏性,L2正则关注的是让模型在每一层生成的特征更加真实准确。
而隐式的正则化,则是其出现的目的不是为了正则化,而正则化的效果是其副产品,包括early stopping,批量标准化,随机梯度下降。另一种分类的方式是训练时的正则化和模型构建时的正则化。前者只用在模型训练时,而后者在训练和模型实际运行时都会出现。前者包括随机梯度下降,early stopping dropout和drop link,这些技巧都不会用在训练好的模型中。
最后让我们看一篇17年ICLR上的论文,Understanding Deep Learning Requires Re-thinking Generalization,这篇文章的作者想看看深度学习为什么具有超过之前方法的泛化能力,为了定义清楚这个问题,他观察了机器视觉领域成熟的网络,例如ImageNet和AlexNet,在不改变模型的超参数,优化器和网络结构和大小时,在部分/全部随机标签的CIFAR 10数据集,以及加入了高斯噪音的图片上的表现。如果在随机生成的分类标签上,模型表现的也很好,这对于模型的泛化能力意味着什么了?

先让我们看看文中给出的数据,A图指出,不管怎样在模型中怎样引入随机性,在图像中加入随机噪音,对像素进行随机洗牌,还是用随机生成的像素点组成的图片,哪怕图像的标签都是随机生成的,模型也能让训练集上的误差达到最小值。这很反直觉,在上述的情况下,人脑是学不到什么的,但深度学习却可以。这说明神经网络的有效容量是足够大的,甚至足够使用暴力记忆的方式记录整个数据集。但这并不是我们想要的。而在部分随机标签的情况下,模型用暴力记忆的方式记住了数据点,而对正确标注的数据进行了正常的特征提取。
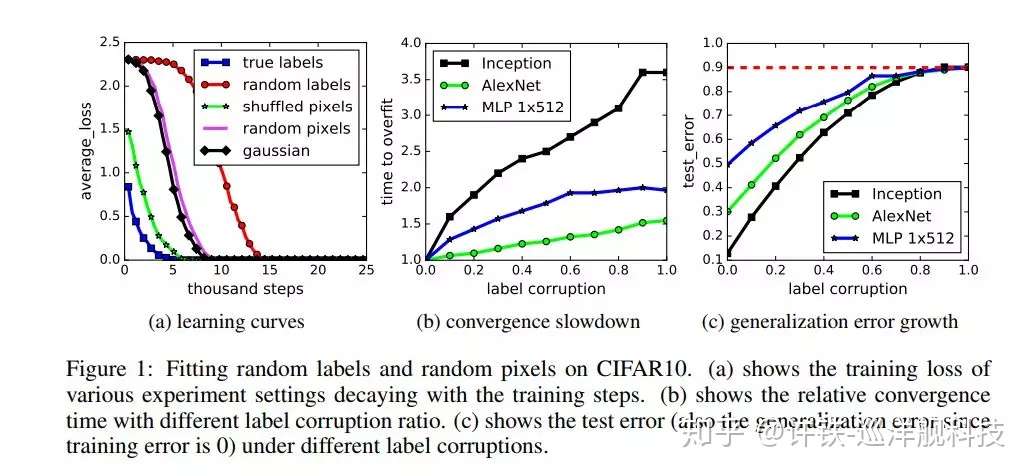
接下来B图讨论的是在不同比例的label是随机产生的情况下模型训练所需的时间,这里得出的结论是即便使用越来越多的随机标签,进行优化仍然是很容易的。实际上,与使用真实标签进行训练相比,随机标签的训练时间仅仅增长了一个小的常数因子。而且不管模型本身的结构有多么复杂,在随机标签的数据下训练起来时间都不会增长太多。这里多层感知机的训练时间增长要高于AlexNet,这点令我意外,在待优化的参数相差不多的前提下,可能的原因我猜测是CNN中待优化的参数相对均匀的原因。
而C图展示了在是不同比例的随机标签下,不同的网络结构在测试集下的表现,这里选择的都是在训练集上错误为0的网络结构。可以看出深度学习网络即使在拟合随机数据时,仍能保持相对良好的泛化能力。这意味着标签随机化仅仅是一种数据转换,学习问题的其他性质仍保持不变。当全部的标签都是随机生成的时候,那么理论的泛化误差就是0.9(这里是十分类问题,随机猜有10%的机会是对的),但只要部分的标签不是随机生成的时候,那越复杂,容量越大的模型表现的泛化能力就越好。在40%的标签是随机生成的时候,如果网络完全没有暴力的对数据点的记忆,那么模型的最好表现应该是0.4×0.9+0.6×0.1即0.42,任何比这个好的表现都说明正则化的方法没有完全的阻止神经网络去死记硬背,但我们看到即使最好的模型,其训练时误差都能到0。但越先进的模型,在避免模型brute force式的记忆上做的越好,从而使测试集上误差更接近理论最优值。
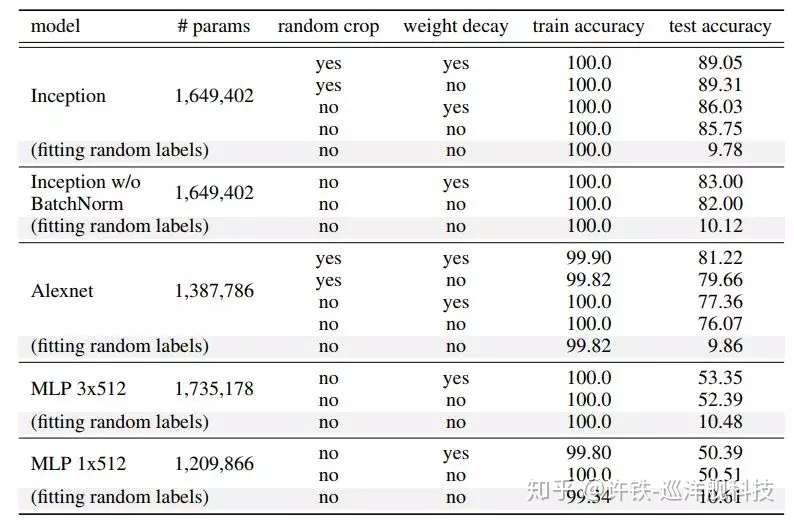
这里列出了不同的模型在不同的参数下的泛化能力,可以看出上文提到的drop link和权重衰减,标准正则化(BN)的效果,但没有列出我更关注数据,即在部分数据为随机标签时模型的泛化能力。
这篇文章的好处是其实验模式是可以很容易去重复的,你可以在Minst数据集上去重复类似的实验,还可以看看在加入了不同的正则化策略后,网络在部分随机标签的数据上表现的怎么样。我还没有做实验,但预测相比于原始的2个隐藏层的CNN,加入drop out或drop link的模型泛化效果最好,这时可以让那些拟合到随机生成的数据的神经元消失。而加入L2正则项的模型泛化能力最差,原因是这时小的权重还是会引入错误,从而干扰特征的提取。不过重复一遍,以上的不过是个人的脑洞,我是通过在脑中模拟人的大脑在这种情况下怎么表现的更好来思考这个问题的,这样一种自我中心的视角,并不适合理解深度神经网络。但这就是人的具身认知的极限了。
许多支撑神经网络有效性的依据都建立在这样一个猜想之上:“自然”数据往往存在于多维空间中一个非常窄的流形中。然而,随机数据并不具备这样的趋势。但很显然,这篇理论性的文章证伪了这个看法。我们并不理解是什么让神经网络具有好的泛化能力。而理解是什么让神经网络具有泛化能力,不止能让模型更具有可解释性,还能为构建更鲁棒的模型提供指导方向和设计原则。这么看来,现在的深度学习,更类似古代的炼金术而不是化学,还缺少一个统一的普世的理论架构。
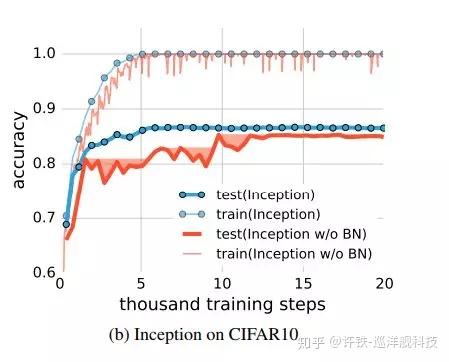
最后借着上面文章的图总结下这篇小文,通过从不同角度观察泛化能力,将深度学习中常用的分成了显式和隐式两类。下图可以看看early stopping的影响,在没有批量正则化的时候,early stopping并没有多少效果,等到满足条件(例如5次迭代时在训练集上准确度不明显变化)时,模型已经过拟合了,而再加入了批量正则化之后,early stopping可以发挥效果了,这说明正则化的方法要组合在一起用才会有效。
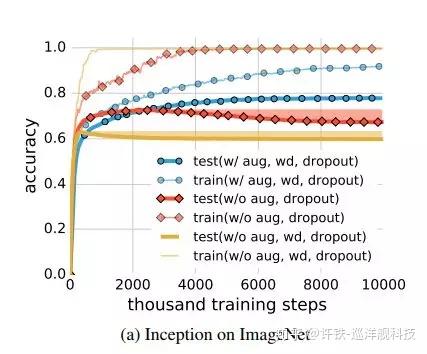
而下面的这幅图展示了权重衰减,数据增强和dropout三种方法在Inception网络上的效果,除了要看到使用正则化带来的泛化能力提高之外,还要看到正则化的技术能解释的泛化能力只是一部分,还要很多未知的因素,对神经网络的泛化能力做出了贡献。
这篇论文中只写了优化方法和网络结构对泛化能力的影响,而深度学习的另一个支柱优化函数的影响则没有提到。在分类任务上这点体现的不明显,但对于生成任务,改变的更多是优化的目标函数,比如各种GAN及其衍生模型,这时能很直觉的看出目标函数对泛化能力的影响。这与传统的观点是相悖的,传统的机器学习,能影响泛化能力的只是模型。但深度学习将数据和模型的界限变得模糊了,优化目标对泛化能力的影响这个问题该怎样变成一个可以量化的问题,类似这篇文章中做的,是一个值得思考的问题。可以在给GAN(点击查看相关介绍文章)的带标注输入数据中加入不同程度的随机性,但如何量化生成模型的泛化可靠性了?这值得深入的思考。
更多阅读
什么让深度学习与众不同-《Artificial Intuition》读书笔记上
《Artificial Intuition》读书笔记下 创造一种新的语言
下面是广告时间,总时长超过16个小时,全面的涵盖常见深度学习模型架构,优化方法。本文提到的正则化技术都有详细的逐行代码详解。超值的良心价。
