首先,讲一下kd树的概念,实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。这在特征空间的维数大及训练数据容量大时尤其必要。k近邻法最简单的实现是线性扫描(穷举搜索),即要计算输入实例与每一个训练实例的距离。计算并存储好以后,再查找K近邻。当训练集很大时,计算非常耗时。为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。
看来统计学习中的kd树的讲解,感觉讲的有点啰嗦,我个人对kd树的理解是这样的。
首先,你对你的数据集中的第一个属性进行一次划分,可以根据他的中位数进行一个划分,然后第一个属性划分完之后你可以再根据第二个属性进行划分,同样的你可以根据他的中位数进行划分,然后继续对剩下的属性进行一个划分,划分完之后就形成了一个如下图的kd树。假设数据集是
T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平衡kd树:
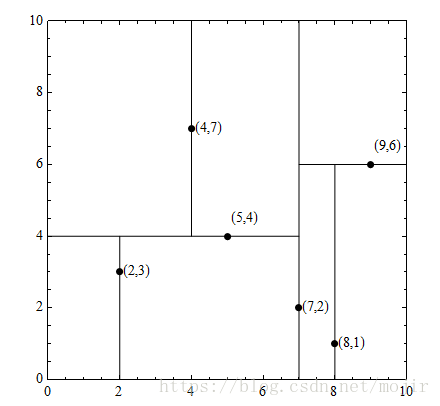
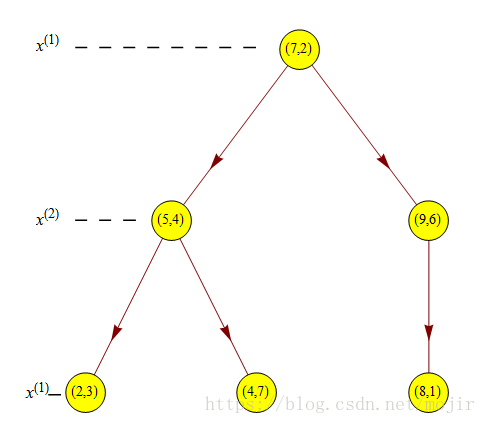
但是,就算形成了一个平衡树,也可能这颗树的搜索效率不是一个最好的。