版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/shouhuxianjian/article/details/76100591
lstm的结构就不重复废话了,推荐一个简单理解的:
[译] 理解 LSTM 网络
这个写的不错,首先从结构上清晰明了的知道了lstm中几个门的作用及操作过程。然而却缺少了矩阵计算级别的结构介绍,也就是今天一直疑惑的,每个门到底是个单神经元还是一层神经元。后面去找原文,也就是第一篇lstm的论文仍未解除心中疑惑,而且其中画的图还没有上面那个好理解。只能求知于tensorflow源码。
1 - 首先通过
from tensorflow.contrib import rnn
rnn.BasicLSTMCell()找到了源码 C:\Anaconda3\Lib\site-packages\tensorflow\python\ops\rnn_cell_impl.py中
class BasicLSTMCell(RNNCell):
......
def call(self, inputs, state):
"""Long short-term memory cell (LSTM).
Args:
inputs: `2-D` tensor with shape `[batch_size x input_size]`.
state: An `LSTMStateTuple` of state tensors, each shaped
`[batch_size x self.state_size]`, if `state_is_tuple` has been set to
`True`. Otherwise, a `Tensor` shaped
`[batch_size x 2 * self.state_size]`.
Returns:
A pair containing the new hidden state, and the new state (either a
`LSTMStateTuple` or a concatenated state, depending on
`state_is_tuple`).
"""
sigmoid = math_ops.sigmoid
# Parameters of gates are concatenated into one multiply for efficiency.
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(value=state, num_or_size_splits=2, axis=1)
concat = _linear([inputs, h], 4 * self._num_units, True)
# i = input_gate, j = new_input, f = forget_gate, o = output_gate
i, j, f, o = array_ops.split(value=concat, num_or_size_splits=4, axis=1)
print('i shape:%s'%i.shape)
new_c = (
c * sigmoid(f + self._forget_bias) + sigmoid(i) * self._activation(j))
new_h = self._activation(new_c) * sigmoid(o)
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)
return new_h, new_state通过写入上述print语句,并如《deep learning with tensorflow》中例子部分
n_hidden = 100
x = tf.placeholder("float", [128, 28, 28])
y = tf.placeholder("float", [128, 10])
weights = {
'out': tf.Variable(tf.random_normal([n_hidden, 10]))
}
biases = {
'out': tf.Variable(tf.random_normal([10]))
}
def RNN(x, weights, biases):
x = tf.transpose(x, [1, 0, 2])
x = tf.reshape(x, [-1, 28])
x = tf.split(axis=0, num_or_size_splits=28, value=x)
lstm_cell = rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)
outputs, states = rnn.static_rnn(lstm_cell, x, dtype=tf.float32)
return tf.matmul(outputs[-1], weights['out']) + biases['out']
pred = RNN(x, weights, biases)会输出
i shape:(128, 100)
i shape:(128, 100)
i shape:(128, 100)
i shape:(128, 100)
i shape:(128, 100)
i shape:(128, 100)
i shape:(128, 100)
i shape:(128, 100)
i shape:(128, 100)从而得知每个门其实是一层神经元,而非单个神经元,即如《Show and Tell: Lessons Learned from the 2015 MSCOCO Image Captioning Challenge》论文中的lstm结构:
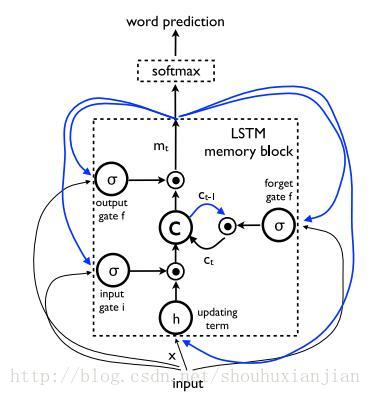
其中有输入门i、输出门f、遗忘门f等,而单拿输入门,是一个如下图的结构:
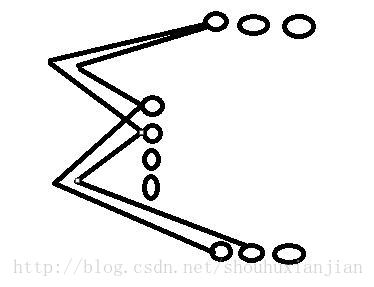
(==!,visio,coredraw都没装)
即是一个全连接层。