简介
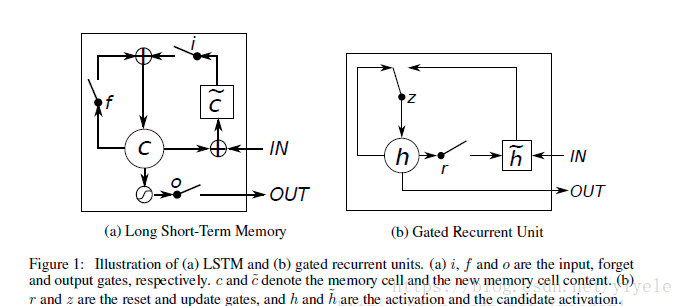
GRU是LSTM的一种变体,其将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,是非常流行的变体。
使用LSTM的原因之一是解决RNN Deep Network的Gradient错误累积太多,以至于Gradient归零或者成为无穷大,所以无法继续进行优化的问题。GRU的构造更简单:比LSTM少一个gate,这样就少几个矩阵乘法。在训练数据很大的情况下GRU能节省很多时间。
GRU模型
与LSTM不同,GRU只有两个门了,分别为更新门和重置门,即图中的
和
。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
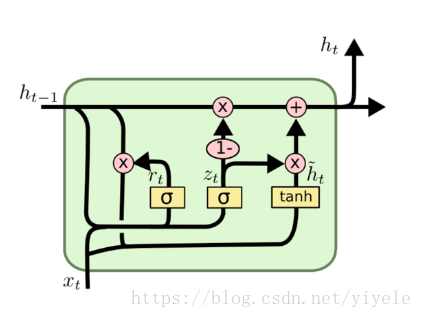
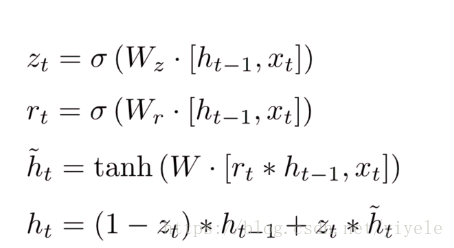
GRU训练
从前面的公式中可以看到需要学习的参数就是
那些权重参数,其中前三个权重都是拼接的,所以在学习时需要分割出来,即
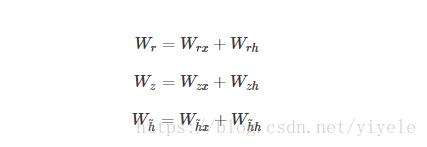
输出层的输入
。
设某时刻的损失函数为
,则某样本的损失为
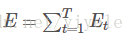
与前面LSTM网络类似,最终可以推出
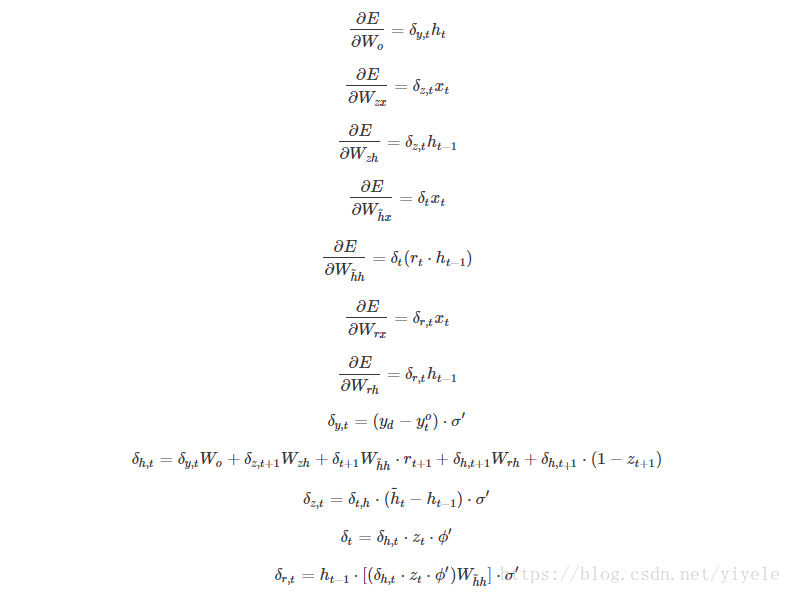
GRU与LSTM
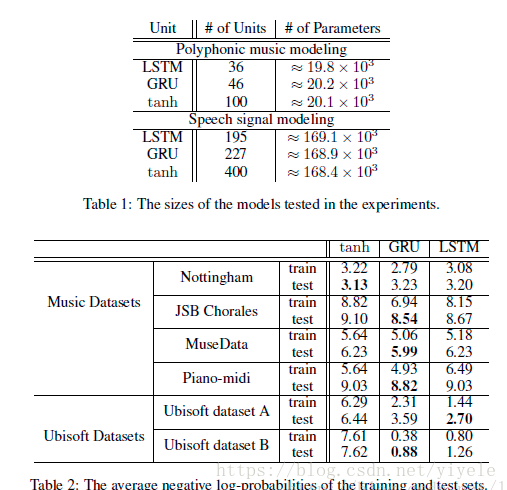
参考资料:
https://blog.csdn.net/wangyangzhizhou/article/details/77332582
https://blog.csdn.net/lreaderl/article/details/78022724
