前言
attention作为一种机制,有其认知神经或者生物学原理: 注意力的认知神经机制是什么?
大多数attention (gating) 技巧都可以直接加入现有的网络架构,通过合理设计初始化和训练步骤也可以利用现有网络的预训练参数。这大大扩展了这些技巧的适用范围。
参考此文:Recurrent Visual Attention源码解读
Mnih, Volodymyr, Nicolas Heess, and Alex Graves. “Recurrent models of visual attention.” Advances in Neural Information Processing Systems. 2014 . https://arxiv.org/abs/1406.6247
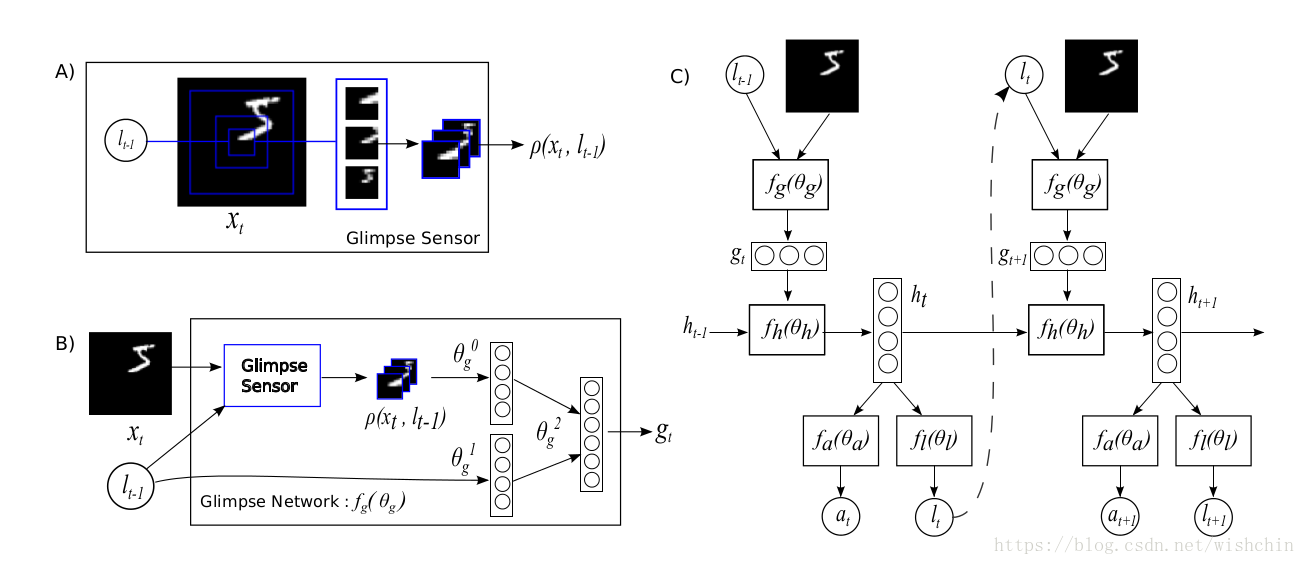
这篇文章处理的任务非常简单:MNIST手写数字分类。但使用了聚焦机制(Visual Attention),不是一次看一张大图进行估计,而是分多次观察小部分图像,根据每次查看结果移动观察位置,最后估计结果。使用 Attention 机制之后会增加计算量,但是性能水平能够得到提升。
Yoshua Bengio的高徒,先后供职于LISA和Element Research的Nicolas Leonard用Torch实现了这篇文章的算法。Torch官方cheetsheet的demo中,就包含这篇源码,作者自己的讲解也刊登在Torch的博客中,足见其重要性。
通过这篇源码,我们可以
- 理解聚焦机制中较简单的hard attention
- 了解增强学习的基本流程
- 复习Torch和扩展包dp的相关语法
一、Attention机制应用于NLP
Attention机制的基本思想是,打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。
Attention机制的实现是通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。
换一个角度而言,输出序列中的每一项的生成概率取决于在输入序列中选择了哪些项。
“在文本翻译任务上,使用attention机制的模型每生成一个词时都会在输入序列中找出一个与之最相关的词集合。之后模型根据当前的上下文向量 (context vectors) 和所有之前生成出的词来预测下一个目标词。
… 它将输入序列转化为一堆向量的序列并自适应地从中选择一个子集来解码出目标翻译文本。这感觉上像是用于文本翻译的神经网络模型需要“压缩”输入文本中的所有信息为一个固定长度的向量,不论输入文本的长短。”
— Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
虽然模型使用attention机制之后会增加计算量,但是性能水平能够得到提升。另外,使用attention机制便于理解在模型输出过程中输入序列中的信息是如何影响最后生成序列的。这有助于我们更好地理解模型的内部运作机制以及对一些特定的输入-输出进行debug。
“论文提出的方法能够直观地观察到生成序列中的每个词与输入序列中一些词的对齐关系,这可以通过对标注 (annotations) 权重参数可视化来实现…每个图中矩阵的每一行表示与标注相关联的权重。由此我们可以看出在生成目标词时,源句子中的位置信息会被认为更重要。”
— Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
数学解释请查看原文...
二、聚焦机制(Visual Attention)
使用Visual Attention详解..
- 聚焦机制(Attention):每次只看输入的一小部分,诸次移动观察范围。
- 循环神经网络(Recurrent NN):在每一次移动和输出之间建立记忆
- 增强学习(Reinforcement learning):在训练过程中,根据不可导的反馈,从当前位置产生探索性的采样。
增强学习过程
一个 recurrent neural network(RNN),按照时间顺序处理输入,一次在一张图像中处理不同的位置,逐渐的将这些部分的信息结合起来,来建立一个该场景或者环境的动态间隔表示。并非马上处理整张图像甚至bbox,在每一个步骤中,模型基于过去的信息和任务的需要选择下一个位置进行处理。这样就可以控制模型的参数和计算量,使之摆脱输入图像的大小的约束。这里和CNN有明显的不同。我们就是要描述这么一个端到端的优化序列,能够直接训练模型,最大化一个性能衡量,依赖于该模型在整个任务上所做的决策。利用反向传播来训练神经网络的成分和策略梯度来解决 the non-differentiabilities due to the control problem。RAM:The Recurrent Attention Model
本文将 attention problem 看做是目标引导的序列决策过程,能够和视觉环境交互。在每一个时间点,agent 只能根据有带宽限制的感知器来观察全局,即: it never senses the environment in full. 他只能在一个局部区域或者狭窄的频域范围进行信息的提取。The agent 可以自主的控制如何布置感知器的资源,即:选择感知的位置区域。该agent也可以通过执行 actions 来影响环境的真实状态。由于该环境只是部分可观察,所以他需要额外的信息来辅助其进行决定如何行动和如何最有效的布置感知器。每一步,agent 都会收到奖励或者惩罚,agent 的目标就是将奖励最大化。
三、LSTM的改进
CNN中的两种Attention机制:Stochastic “Hard” Attention And Deterministic “Soft” Attention。
通过attention机制计算出的 z^t被称为 context vector,是捕捉了特定区域视觉信息的上下文向量。
首先需要明确,attention要实现的是在解码的不同时刻可以关注不同的图像区域,进而可以生成更合理的词。那么,在attention中就有两个比较关键的量,一个是和时刻 t 相关,对应于解码时刻;另一个是输入序列的区域 ai,对应图像的一个区域。
实现这种机制的方式就是在时刻 t ,为输入序列的各个区域 i 计算出一个权重 αti。因为需要满足输入序列的各个区域的权重是加和为一的,使用Softmax来实现这一点。至于Softmax需要输入的信息,则如上所讲,需要包含两个方面:一个是被计算的区域 ai ,另一个就是上一时刻 t-1 的信息 ht−1:
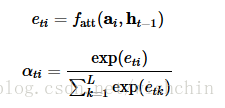
式中的 fatt是耦合计算区域 i 和时刻 t 这两个信息的打分函数。文中使用多层感知机,也算是最常用的了,我觉得是因为内积太简单,而双线性的参数太多,索性用最简单粗暴的 MLP 。但是我也看过一些paper里面用好几次attention时用不一样的打分函数。
现在,有了权重,就可以计算 z^t了:z^t=ϕ({ai},{αti} )
这个函数 ϕ就代指文中提出的两种attention机制,对应于将权重施加到图像区域到两种不同的策略。