参考博文: 直觉理解LSTM和GRU
第一部分: LSTM
LSTM的结构
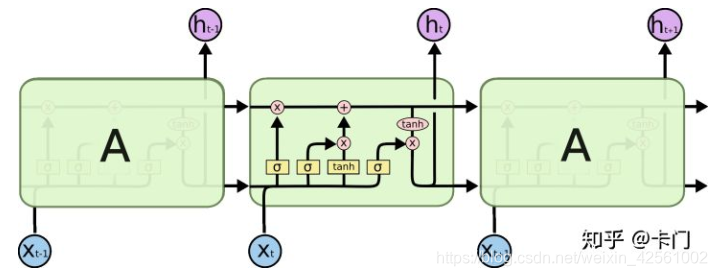
LSTM的原理
LSTM单元之间传递两个信息, c和h
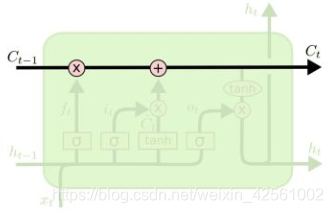
到
, 先遗忘一部分信息, 然后再加上新学到的一部分信息
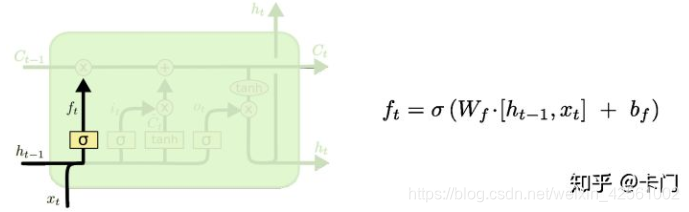
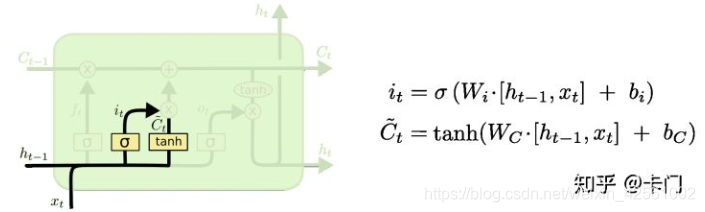
控制哪些需要忘掉,
用于生成新信息,
控制哪些新信息需要保留,
就完成了
但是
还没有完成,
还需要经过如下处理用于输出:
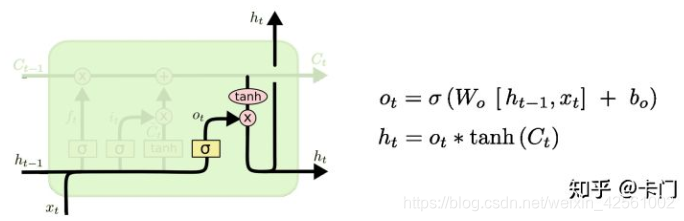
控制了新信息中哪些用于此单元输出
LSTM的优势
相比RNN, LSTM最大的优势就是可以缓解梯度消失问题. (RNN在反向传播的时候求底层的参数梯度会涉及到梯度连乘, 出现梯度消失或者梯度爆炸)(具体的数学原理, 参考知乎: 为什么相比于RNN,LSTM在梯度消失上表现更好?-- 刘通的回答)
注意, LSTM并不能解决梯度爆炸问题, 不过针对梯度爆炸有专门的方法, 比较好处理.
此外, LSTM通过引入更多的参数, 可以更加精细地预测时间序列变量.
第二部分: GRU
GRU的结构
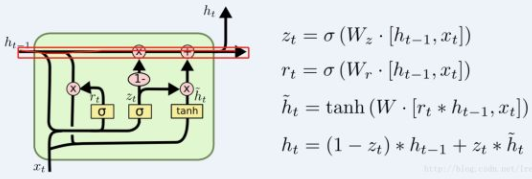
在GRU里面,不再有C和h两部分,而是只用了h
GRU的原理
与LSTM类似, GRU的学习也是先遗忘一部分旧信息, 再添加一部分新信息.
而不同之处在于, 在LSTM中,忘记和添加的比例是学习来的,两者没什么相关;而在GRU中,这个比例是固定的:忘记了多少比例,那么新的信息就添加多少比例。这个由 (1-)来进行控制
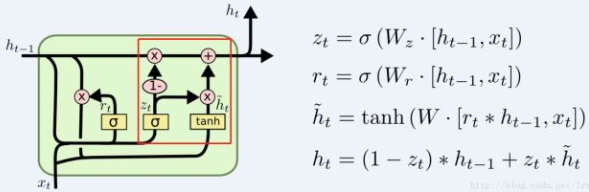
同时控制遗忘旧信息和记住新信息的比例
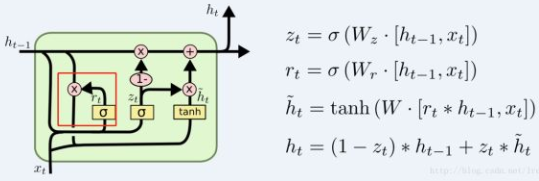
新信息是由
和一部分
生成的, 这"一部分"由
控制
GRU的优势
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU, 尤其是训练较深的网络时.