说到自然语言,我就会想到朴素贝叶斯,贝叶斯核心就是条件概率,而且大多数自然语言处理的思想也就是条件概率。
所以我用预测一个句子出现的概率为例,阐述一下自然语言处理的思想。
处理思想-概率
句子,就是单词的序列,句子出现的概率就是这个序列出现的概率
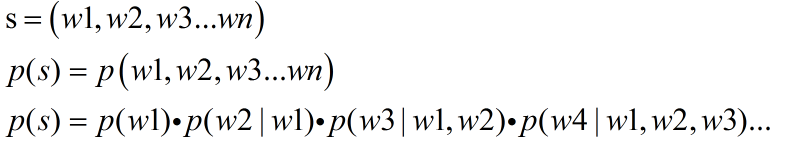
可以想象上面这个式子计算量有多大。
为了减少计算量,常常用一个估计值来代替上面的概率。估计该值常用的方法有
n-gram、决策树、最大熵模型、条件随机出、神经网络等。
以最简单的n-gram为例
n-gram模型有个假设:当前单词出现的概率仅与前面n-1个单词有关
于是,m个单词的句子出现的概率可以估计为
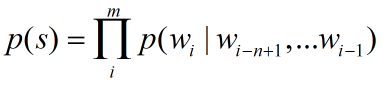
显然n取值越大,理论上这个估计越准确
但是因为计算量的问题,通常n取较小值,如 1,2,3,分别有对应的名字 unigram, bigram, trigram,最常用的是2
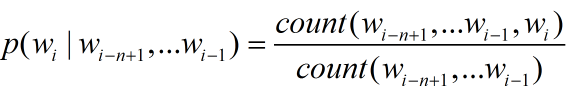
出现次数相比,很显然有个问题,如果没出现呢,比如语料库较小,那么这个单词出现的概率为0,,p(s)=0,
一个单词没出现导致整个句子出现概率为0,显然不合适
这也是自然语言处理中比较普遍的问题,常用的解决方法是拉普拉斯平滑,避免0的出现,比如

此时这个句子的概率就算出来了。
评价指标-复杂度
语言模型的好坏常用复杂度(perplexity)来评价。
如果一个句子在文档中确实出现了,那么我们的模型算出来的概率越大越好,
概率越大,就需要每个p的概率越大,
每个p越大,就意味着这某些单词出现的情况下,出现这个单词的概率很大,
也就是说,在某些单词出现时,下一个单词的可选择性很小,比如单词 “国”后面的单词很少,最常用的是“家”,此时“家”的概率就很大
这个可选择性就是复杂度。
其实可以理解为整个词语结构的复杂度,词语结构越简单,复杂度越低。图形表示如下
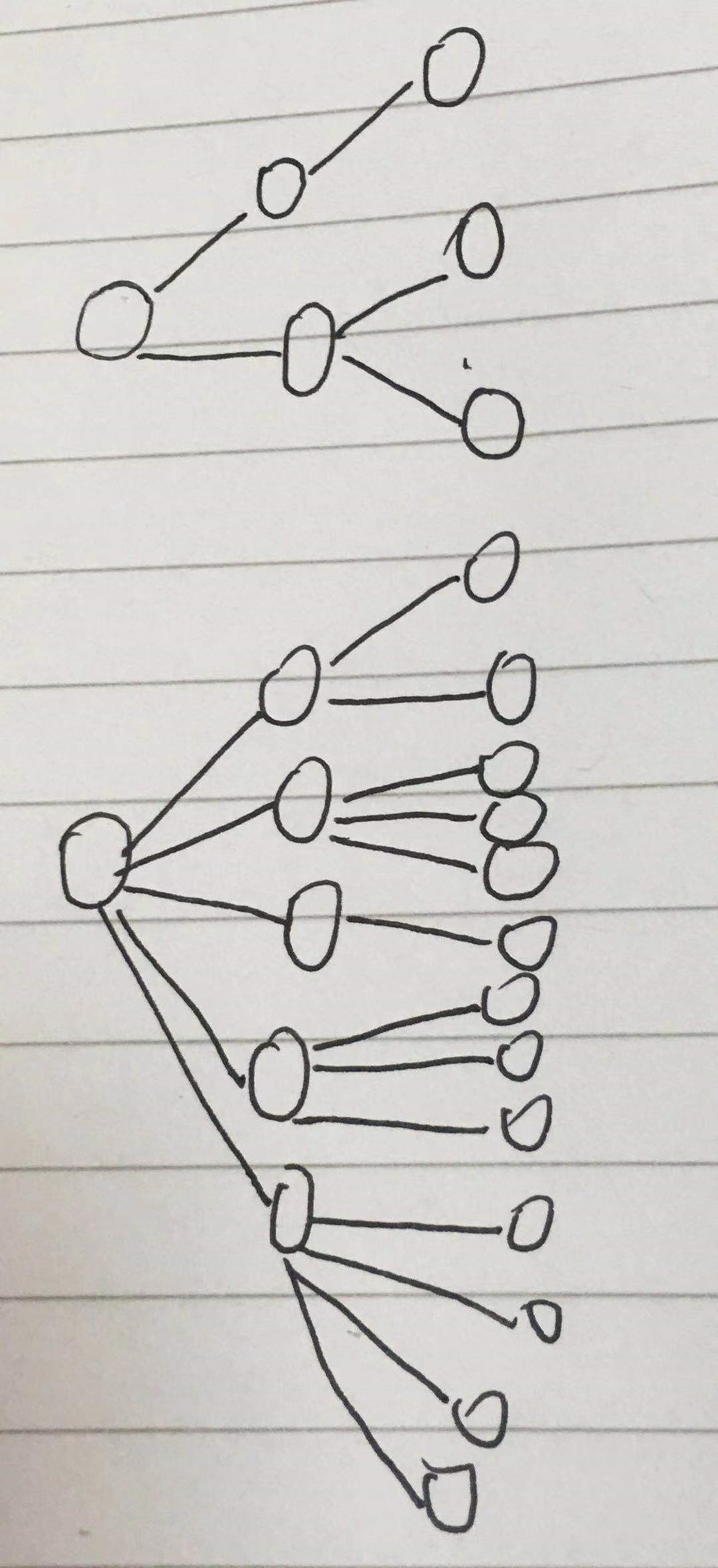
显然上面的结构简单。
可选择性可以用概率的倒数来表示。即概率越大,可选择性越小,复杂度越低。

可以两边取log简化运算。取log乘法变加法,也避免了一个为0结果为0的情况。
LSTM 语言模型
lstm 使得网络具有记忆功能,也就是记住了之前的词语,也就是在知道之前词语的情况下,训练或者预测下一个单词。这就是rnn处理自然语言的逻辑。
训练过程:输入x是单词,y是x的下一个单词,最终得到每个单词下一个单词的概率。
预测过程:取下一个单词中概率最大的单词。
图形表示如下
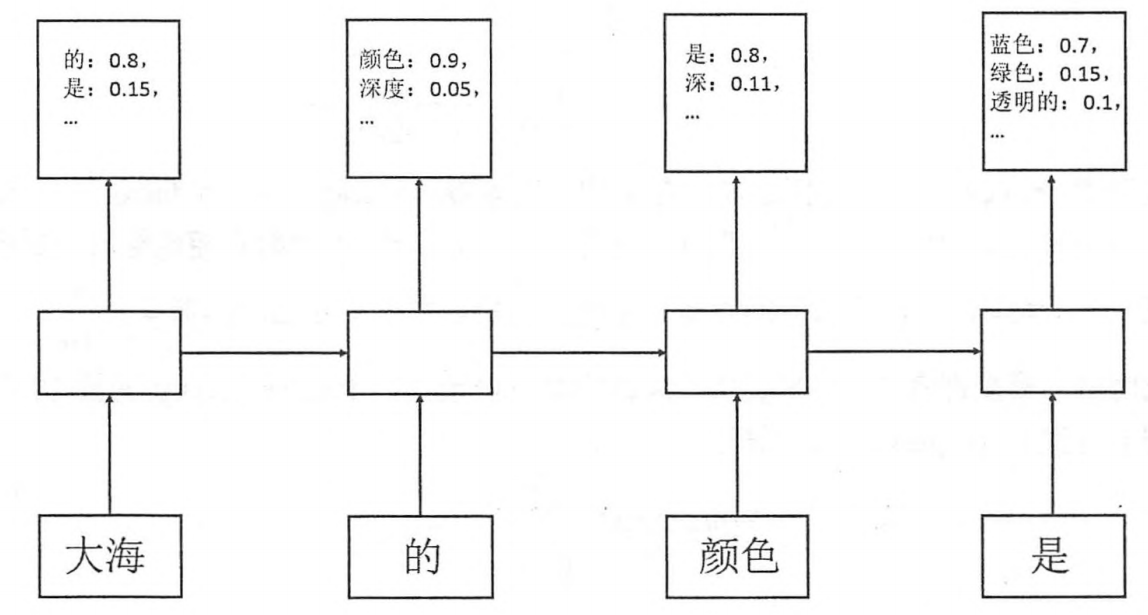
把训练样本 “大海的颜色是蓝色” 输入网络训练,可以得到在 “大海” 出现的情况下,后面是 “的” 的概率0.8,是 “是”的概率0.15,
在“大海的”出现的情况下,后面每个单词出现的概率,依次
最终预测时,在“大海的颜色是”出现的情况下,预测结果是“蓝色”的概率是0.7,预测正确。