1、KNN算法原理
K近邻分类器可以说是目前为止最简单的机器学习和图像分类算法。实际上,由于其过于简单,算法不“学习”任何东西,取而代之的是这个算法直接依赖于特征向量之间的距离。
具体来说,就是将所有数据样本的特征向量直接存储下来,然后基于某种相似性度量准则,查询与当前样本最近似的k个样本来进行投票,将投票结果作为最终的分类结果,翻译过来就是:“告诉我你的邻居是谁,我将告诉你,你是谁。”
为了保证KNN算法能够工作,这里做了一个假设,有相似内容的图片在n维空间上距离较近。因此,我们可以看一下表示猫、狗和熊猫三个类别的图片,如图1所示,x轴表示图片分布的蓬松性,y轴表示动物外观。
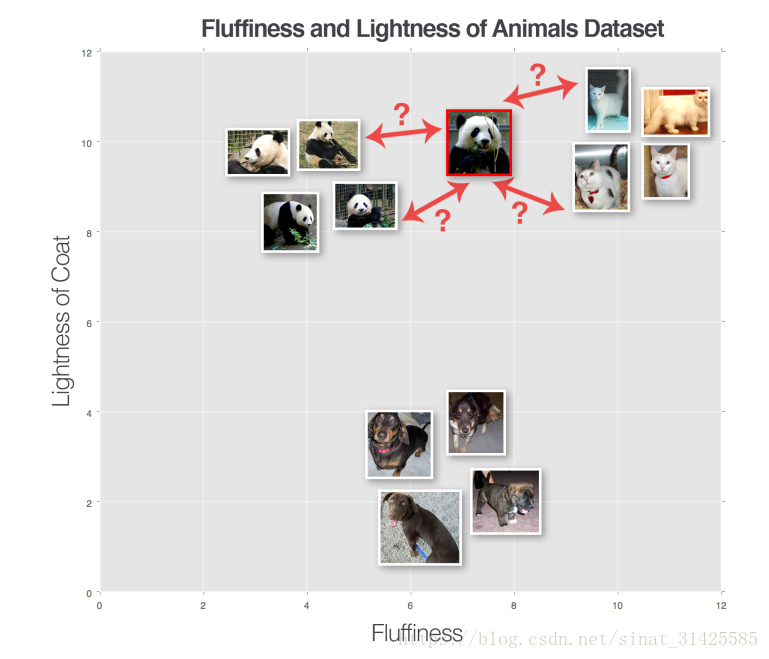
图1 猫、狗和熊猫三个类别分布(摘自参考资料[1])
为了应用KNN分类器进行分类,需要预先设定相似性度量准则,常见的度量准则有欧拉距离和曼哈顿距离,欧拉距离定义如式(1)所示。
曼哈顿距离或 距离如式(2)所示。
实际上,你可以选择最符合你数据的任何度量相似性准则(给你最好的分类结果)。
2、KNN算法流程
1) 收集数据集:获取样本图像,并将所有样本的大小都规范化到同一个尺寸;
2) 分离数据集:将样本分为训练集和测试集两个部分;
3) 训练分类器:使用训练样本集训练KNN分类器,其实就是将训练集存下来;
4) 评估分类器:使用测试集来评估训练好的KNN分类器性能。
KNN算法实例如图2所示。

图2 KNN算法实例(摘自参考资料[1])
图2中就是样本分布示意,当一张猫图像(红色边界)来了,首先,找最近似的K(这里K=3)个训练样本,然后,利用这K个样本进行投票(这里K个样本中,2个为猫,1个为熊猫),最后,得出结论,当前样本为猫。
3、代码实现
~~~~未完待续~~~~
参考资料:
[1] Deep_Learning_for_Computer_Vision_with_Python