记录一下参赛的过程和体会
文章目录
比赛地址
比赛回顾
这是我第一次参加与NLP相关的比赛,所以就是在实践中学习,哪里不会点哪里,经过大约10天的努力跑出的成绩如下:
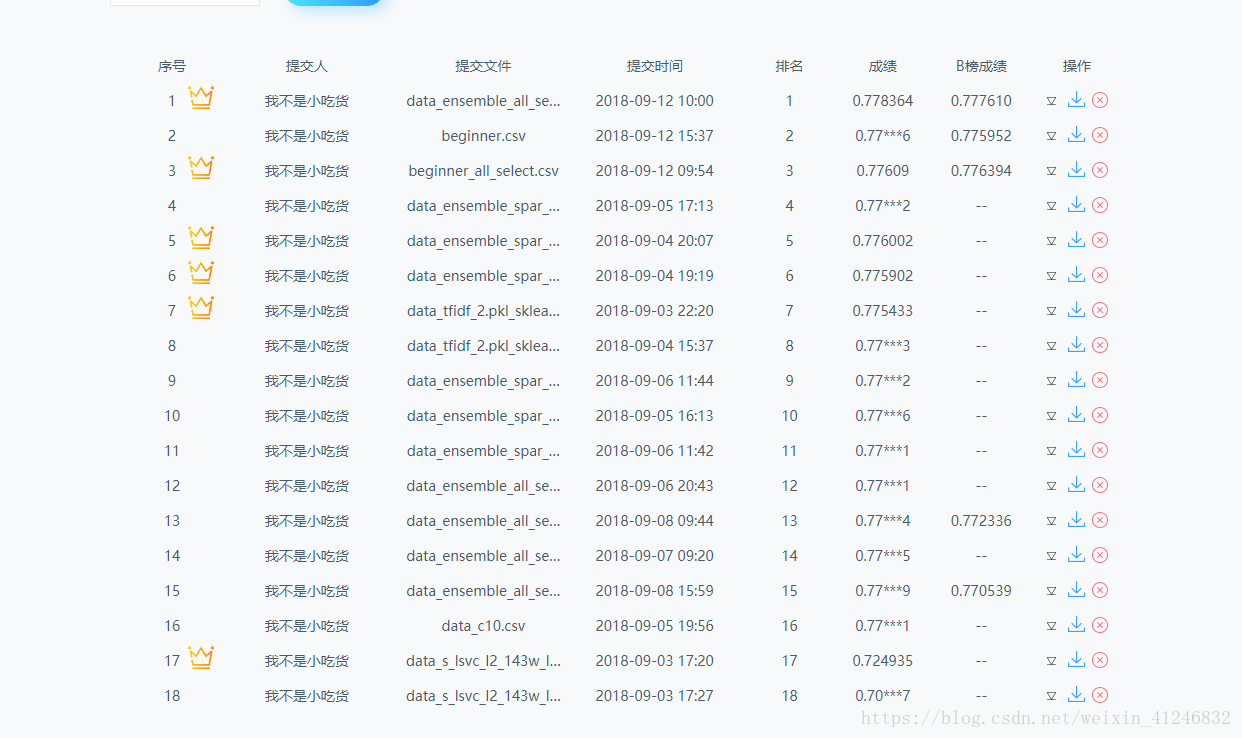
记录下我的比赛提交记录
回顾比赛,在整理自己的特征数据、结果对比的时候还是有些不够规范,有点混乱,以后要改正!
特征分析 提取
感谢Jian老师提供的Github。我是jian老师的Github
首先,应该是分析数据得到其中的特征,但比赛数据是经过脱敏后的数据,所以就没分析~~,哈哈哈。
直接提取了tf(词频)、hash(哈希)、tfidf(term frequency–inverse document frequency)词频逆文本频率、lsa(潜在语义特征)、Doc2vec等特征。还有一个特征是LDA(线性判别式分析),由于要生成这个特征的时间太长所以放弃了,即使把tf特征筛选之后生成LDA特征,时间也是不能接受。
Tfidf特征代表的是词的重要程度,直觉上这个特征一定比tf特征要好,所以最开始使用的这个特征。之前常听Word2vec。所以当时查了一下Word2vec 和Doc2vec的区别(忘了··)

实验
lsa单特征
lsa特征可以把tfidf特征降维,可以找到词在句子中的含义(具体作用有点忘了),因为不用词在不同句子中的意思也不一样。降维也可以提高运行速度。下面是lsa特征在不同模型中的对比。
| 特征 | 模型 | 分数 | 耗时(min) |
|---|---|---|---|
| lsa | SVM | 0.7227 | 0.88 |
| lsa | lr | 0.7038 | 1.85 |
| lsa | bagging | 0.7227 | 52 |
| lsa | rf | 0.6428 | 0.74 |
| lsa | adaboost | 0.7227 | 2.7 |
| lsa | gbdt | 0.7026 | 164.88 |
可见SVM的得分最高,而且速度更快,比一些模型融合的方法更好,可能是因为特征较少吧。
之后看见比赛讨论中一个老哥的分享 “带你进前10dadada” 把提取tfidf特征的代码修改如下:
具体细节真忘了(有时间具体说)。重新生成了tfidf特征,实验结果如下:

| 特征 | 模型 | 分数 | 耗时(min) |
|---|---|---|---|
| lsa | SVM | 0.7803 | 7.77 |
| lsa | lgb | 0.75多点 | 383.88 |
| las | adaboost | 0.77多点 | ~~ |
发现分数有所提高,调参挺有用 ,但是时间消耗很多,(有待分析)
特征融合
由于生成多个特征所以考虑了特征融合。回头看数据,数据中把文章分成“词”表示和“字”表示,之前的实验都是建立在“词”表示文章的基础上,所以接下来也把“字”表示文章加入实验中。
| 特征 | 模型 | 验证集分数 | 耗时(min) | 比赛A榜得分 |
|---|---|---|---|---|
| lsa + vec2vec + tf.idf | SVM | 0.7789 | 173.31 | 0.775902 |
| tfidf + tfidf_article | SVM | 0.7800 | 25.19 | 0.7760 (best) |
| tfidf_article + lsa +vec2vec +tf.idf | SVM | 0.7800 | 363.96 | 0.77***6 |
| Dec2vec+ tfidf | lgb | 0.7698 | 2456.92 | ~~ |
可见加入 “字” 后即使是两个tfidf特征融合也能得到很好的效果,接下来使用这个融合后的特征。得到不错的特征后,决定调一调参数。
调参
调整了SVM 的参数C 。C值越大,拟合非线性的能力越强。
| C | 分数 |
|---|---|
| 1 | 0.7800 |
| 2 | 0.7798 |
| ~ | ~ |
| 10 | 0.7780 |
发现差不多,就不写全了。迷茫一阵 不知所措。想尝试交叉验证,应该还能有所提升,无奈时不我待。
Finally
最终,我把所有能用的特征全部融合,之后做了一个特征筛选,使用LightGBM得到最终的成绩。
总结
- 实验很耗时,最好做实验之前有个良好的规划,多问为什么要做这个实验?接下来要怎么实验?并对实验的结果有序进行记录。
- 不熟练理论基础,有关NLP的知识都是遇到不懂的现查现用,导致很多知识记得不牢固,过段时间就忘记了。
- 接下来会完善上面不会的知识,弄懂代码背后的理论依据才是正确的道路。
- 展望一下未来的实验,可能会先学一下多种模型融合,在Top10的PPT展示中几乎都是多种深度学习和机器学习的模型融合,这可能是未来的一个方向。
- 再次感谢Jian老师提供的Github。感谢@范晶晶同学的督促,要不我可能就太懒了就不写了~~
- 不能懒 不能懒!!