第十章 应用机器学习的建议
第1节 评估一个学习算法(Evaluating a Learning Algorithm)
10.1 决定下一步做什么
参考视频:10 - 1 - Deciding What to Try Next (6 min).mkv
到目前为止,我们已经介绍了许多不同的算法,你会发现自己已经了解了许多机器学习方面的东西。
然而在懂机器学习的人当中,不同人仍然存在很大的差距:一部分人确实掌握了怎样高效地运用学习算法,而另外一些人可能只是生搬硬套。在接下来的几段视频中,我将向你介绍一些实用的建议和指导,帮助你明白怎样进行选择,以改进目前的机器学习系统。
假设你对房屋价格完成了正则化线性回归,得到了学习参数 ,但是在预测房价时产生了很大的误差,要想改进这个算法,接下来该怎么办?
- 获得更多的训练实例。通常是有效的,但是代价比较大,可以先考虑下面的集中方法。
- 尝试减少特征的数量。可以手动操作,或者使用一些维度约简技术(例如PCA)
- 尝试获得更多的特征。有时候并没有用,会很耗费时间。
- 尝试增加多项式特征。
- 尝试减少正则化系数
- 尝试增加正则化系数
我们要学习的就是理解哪些方法对我们的算法是有效的,做出更好的选择进行改进,而不是凭直觉挑一个方法去尝试,那样会浪费很多时间。
机器学习诊断法(Machine learning diagnostics)是一种测试法。通过执行这种测试,能够了解某些算法是否有用,通常也能告诉你做些什么来改进算法。需要明确的是,诊断法的实现和执行是需要花费一些时间,但是,他们可以帮助你端正前进的方向,进而节省时间。
10.2 评估一个假设
参考视频: 10 - 2 - Evaluating a Hypothesis (8 min).mkv
本节视频介绍怎样用学过的算法来评估假设函数,并以此为基础来讨论如何避免过拟合(overfit)和欠拟合(underfit)的问题。
当确定学习算法的参数时,我们使用的是最小化训练误差的参数。有时一个模型在训练集的误差非常低,并不能说明它一定是一个好的假设函数(因为过拟合)。那么我们该如何判断一个假设函数是不是过拟合的呢?对于简单的例子,我们对模型进行画图,观察图形趋势,但是对于特征变量较多的情况,我们就很难画图了。
我们使用一种新的方法来评估假设函数:把数据集分成两部分,通常用70%的数据作为训练集(training set),用剩下的30%作为测试集(test set)。有两点要求,每个类别之间选取相同比例的数据,每个类别的数据随机进行选取。
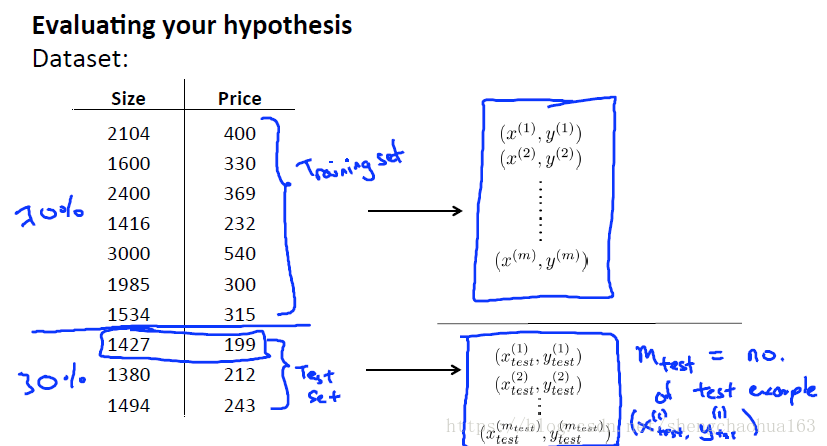
所以一个典型的训练学习过程是:

- 最小化学习模型在训练集上的误差,求得模型参数
- 将该模型运用在测试集上,并计算测试集误差
线性回归计算测试集误差:
逻辑回归计算测试集误差有两种方法:
- 用原有的模型:
- 用误分类的比率:
10.3 模型选择和交叉验证
参考视频: 10 - 3 - Model Selection and Train_Validation_Test Sets (12 min).mkv
对于模型选择问题,我们可以选择正则化参数或特征的多项式次数等等。假设我们要在10个不同的模型之间进行选择:
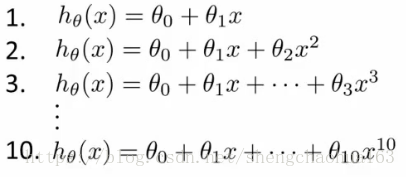
显然多项式次数越高的模型拟合训练集越好,但是并不代表能推广至一般情况。考虑到具有不同多项式的模型,我们可以使用一种系统的方法来识别“最佳”模型,需要使用交叉验证集来帮助选择模型。
这种分解数据集的方法一般为:60%的数据作为训练集,20%的数据作为交叉验证集(cross validation set),剩余20%的数据作为测试集。
模型选择的方法为:
- 使用训练集训练出10个模型
- 用10个模型分别对交叉验证集计算得出交叉验证误差
- 选择交叉验证误差最小的模型
- 用步骤3选出的模型对测试集计算得出测试集误差
误差计算方法:
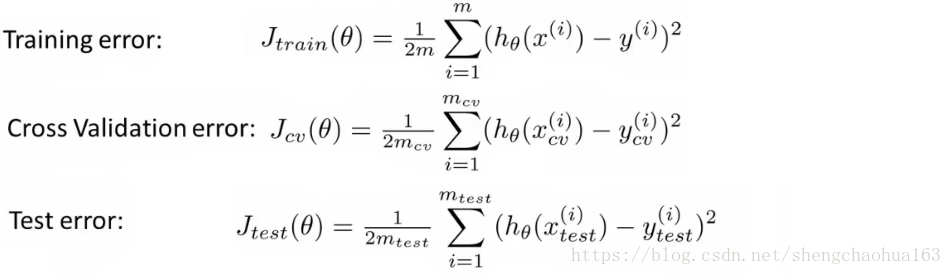
第2节 偏差和方差(bias vs. variance)
10.4 诊断偏差和方差
参考视频: 10 - 4 - Diagnosing Bias vs. Variance (8 min).mkv
当运行一个算法时,如果算法的表现不理想,那么多半时出现两种情况:要么偏差(bias)比较大,要么方差(variance)比较大。换句话说,前一种是欠拟合的表现,后一种是过拟合的表现。搞清楚这一点非常重要,因为能判断是哪种情况是指引我i们改进算法非常有效的方法和途径。
高偏差(high bias)、正常和高方差(high variance)如下图:
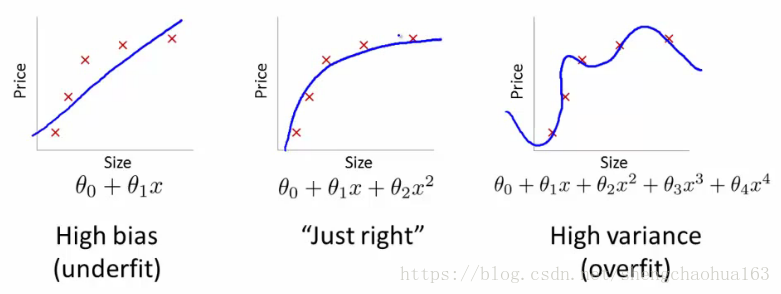
我们可以看出来:随着模型复杂度增加(多项式d次数增加),拟合程度越来越高。训练集误差和交叉验证集误差随着d增加会如何变化,总结如下图:
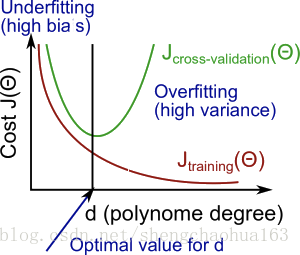
解释:随着模型复杂度增加(多项式次数d增加),拟合程度越来越高,训练集误差越来越小。对于交叉验证集,d较小时,模型拟合程度低,预测能力较低,误差较大。随着d增加,模型拟合程度增加,预测能力增加,但是一旦达到过拟合,模型就会变差,预测能力降低,所以误差先减小后增大。转折点是模型最好的点,再往右过拟合程度增加。
如果交叉验证集误差较大,我们如何判断是高偏差还是高方差呢?
- 高偏差是欠拟合的表现。此时训练集误差和交叉验证集(或测试集)误差均较高,而且大致相等。
- 高方差是过拟合的表现。此时训练误差较低,而交叉验证集(或测试集)误差较高,而且后者远大于前者。
10.5 正则化和偏差/方差
参考视频:10 - 5 - Regularization and Bias_Variance (11 min).mkv
在我们训练模型的时候,有时会使用一些正则化方法来防止过拟合。正则化的程度( )会影响模型多项式的次数:正则化程度过大,对模型中的参数惩罚过大,导致欠拟合;正则化程度过小,模型可能仍存在过拟合的现象。
以正则化线性回为例:
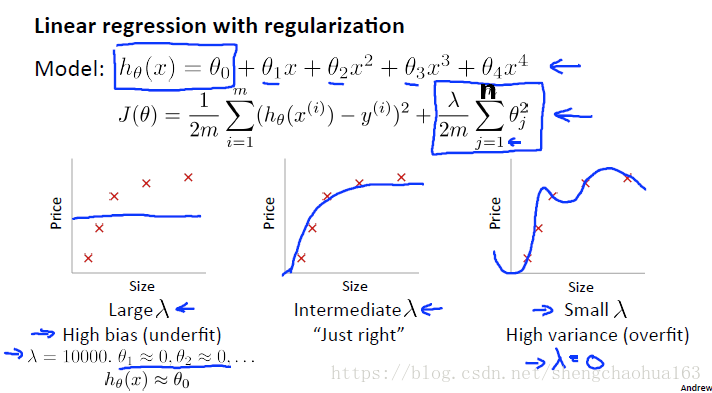
当
很大时,多项式系数几乎为0,模型欠拟合;当
变小,接近 0 时,模型容易过拟合。那么我们应该如何选择合适的
值呢?

如何选择合适的 值:
- 创建一个 列表,通常是0-10之间呈现2倍关系的值。例如,{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24},有12个值。
- 使用训练集对上图中的模型进行训练,得到12个不同程度正则化的模型
- 使用交叉验证集计算交叉验证集误差,使用参数 但不使用
- 选择交叉验证集误差最小的模型
- 运用步骤 4 中选出的模型对测试集计算得出测试集误差(推广误差)
另外,可以将训练集误差和交叉验证集误差与
的大小关系绘制在一张图表上。如下图:
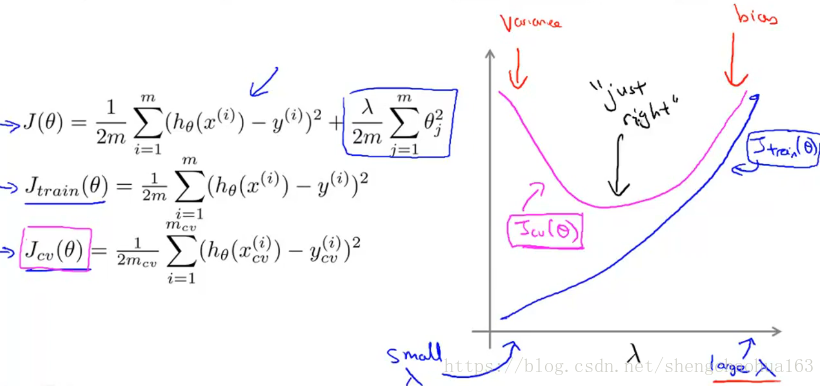
- 当 较小时,模型复杂度较大,容易产生过拟合,所以训练集误差较小而交叉验证集误差较大
- 随着 较大时,模型复杂度变小,拟合程度减小,训练集误差不断增加,而交叉验证集误差则是先减小后增大。转折点是模型最好的点。
10.6 学习曲线
参考视频:10 - 6 - Learning Curves (12 min).mkv
学习曲线(learning curve)是一种很好的工具,我经常使用学习曲线来判断某一个算法是否存在偏差或方差问题。学习曲线通常有助于检查学习算法的完整性或提高性能。该方法将训练集误差和交叉验证集误差与训练集实例数量(m)的函数关系绘制成图表。
假设模型是一个二次函数,当我们在很少的数据集(例如m=1,2,3)上训练时,模型很容易地就可以拟合这些数据,但是训练出来的模型却不能很好地适应交叉验证集。随着训练数据集的增多(m增大),模型在训练集上的误差会增加;当m达到一定值时,误差就会趋于稳定。
像上一节一样,思考一下高偏差和高方差问题。高偏差(high bias):
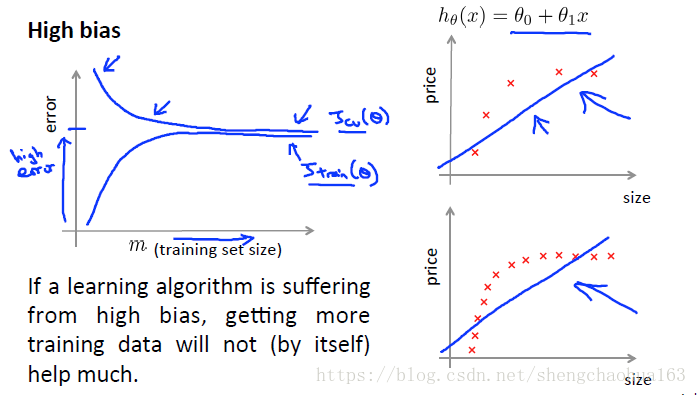
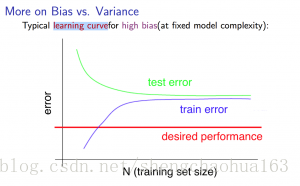
- m 很小时,训练误差很低而交叉验证误差很高
- m 很大时,训练误差和交叉验证误差都很高,而且二者很接近
- 所以,如果学习算法存在高偏差问题,取得更多的训练数据帮助并不大。因为模型复杂度较低,无法拟合较多数据。
高方差(high variance):
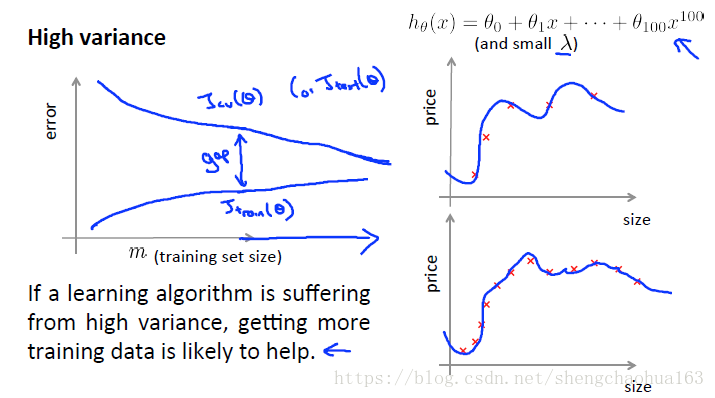

- m 很小时,训练误差很低而交叉验证误差很高
- 随着 m 增加,训练误差会缓慢增加,交叉验证误差随着模型拟合的越来越好而减小
- 所以,如果学习算法存在高方差问题,取得更多的训练数据会有一定帮助。因为更多的数据可以改善模型参数,提高预测能力。
10.7 决定下一步做什么
参考视频:10 - 7 - Deciding What to Do Next Revisited (7 min).mkv
我们已经介绍了怎样评价一个学习算法,讨论了模型选择、偏差和方差的问题。那么这些诊断法怎样帮助我们进行判断,哪些方法有助于改善学习算法的效果,而哪些是徒劳的呢?
回顾第一节中的六种方案:
- 获得更多的训练实例——解决高方差(改善模型参数)
- 尝试减少特征的数量——解决高方差(降低模型复杂度)
- 尝试获得更多的特征——解决高偏差(提高模型复杂度)
- 尝试增加多项式特征——解决高偏差(提高模型复杂度)
- 尝试减少正则化系数 ——解决高偏差(提高模型复杂度,提高拟合能力)
- 尝试增加正则化系数 ——解决高方差(降低模型复杂度,降低拟合能力)
高方差一般意味着过拟合,因为模型参数不好或模型复杂度太高,用1可以改善模型参数,用2、6可以降低模型复杂度,降低拟合能力;高方差意味着欠拟合,因为模型复杂度不够高,用3、4、5可以提高模型复杂度,提高拟合能力。
把本节的内容用于神经网络:
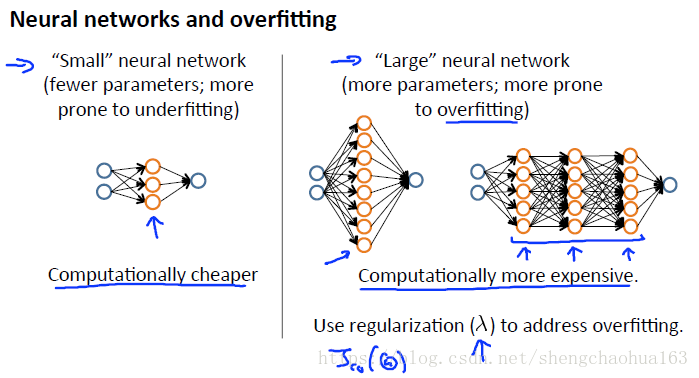
- 参数少的神经网络容易欠拟合,但是计算代价较低。
- 参数多的神经网络容易过拟合,但是计算代价较高,可以用正则化解决过拟合问题。
- 使用单个隐藏层是一个良好的默认值。你可以使用交叉验证集在许多隐藏的图层上训练你的神经网络,然后你可以选择一个表现最好的图层。
总结:
- 多项式次数低(复杂度低)的模型具有高偏差和低方差。在这种情况下,模型拟合数据的效果很差。
- 多项式次数高(复杂度高)的模型拟合训练数据非常好,但是在测试数据上表现非常糟糕。也就是说,对训练数据的偏差很低,但方差很大。
- 在现实中,我们想要在两者之间选择一个模型。它不仅可以很好地一般化,也能很好地拟合数据。