========= 关于偏差、方差以及学习曲线为代表的诊断法 ==========
(一)模型选择Model selection
在评估假设函数时,我们习惯将整个样本按照6:2:2的比例分割:60%训练集training set、20%交叉验证集cross validation set、20%测试集test set,分别用于拟合假设函数、模型选择和预测。

三个集合对应的误差如下图所示(注意没有不使用正则化项):

基于以上划分,我们有模型选择的三个步骤:
step1.用测试集training set对多个模型(比如直线、二次曲线、三次曲线)进行训练;
step2.用交叉验证集cross validation set验证step1得到的多个假设函数,选择交叉验证集误差最小的模型;
step3.用测试集test set对step2选择的最优模型进行预测;

以线性回归为例,假设你利用线性回归模型最小化代价函数J(θ)求解得到一个假设函数h(x),如何判断假设函数对样本的拟合结果是好是坏,是不是说所有点都经过(代价函数J最小)一定是最理想的?
或者这样说,给你下图的样本点,你是选择直线、二次曲线、还是三次曲线......作为假设函数去拟合呢?


以下图为例,你的模型选取其实直接关系到最终的拟合结果:
=======================================
欠拟合Underfit || 高偏差High bias
正常拟合Just right || 偏差和方差均较小
过拟合Overfit || 高方差High variance
=======================================
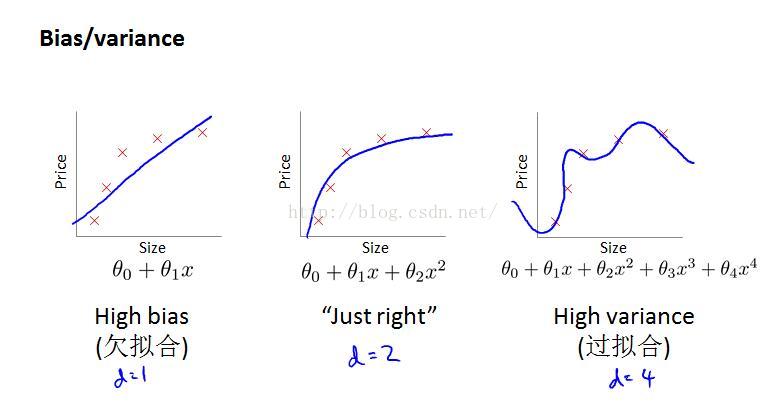
★★★以上问题只是模型选择过程中需要考虑的一点------多项式次数d,实际上,我们还会去考虑这样两个参数:正则化参数λ、样本量m.
下面我将从多项式次数d、正则化参数λ、样本量m这三个量与拟合结果之间的关系做一个简单的概括.
(二)偏差、方差、学习曲线Bias、Variance、Learning curve
1.特征量的度d
还是之前的例子,用二次曲线拟合,训练集和交叉验证集的误差可能都很小;但是你用一条直线去拟合,不管使用多高级的算法去减小代价函数,偏差仍然是很大的,这时候我们就说:多项式次数d过小,导致高偏差、欠拟合;类似的当用10次曲线去拟合,样本点都能经过,对应的代价函数(误差)为0,但是带入交叉验证集你会发现拟合很差,这时候我们说:多项式次数d过大,导致高方差、过拟合。
所以,多项式次数d与训练集、交叉验证集误差的关系如下图:
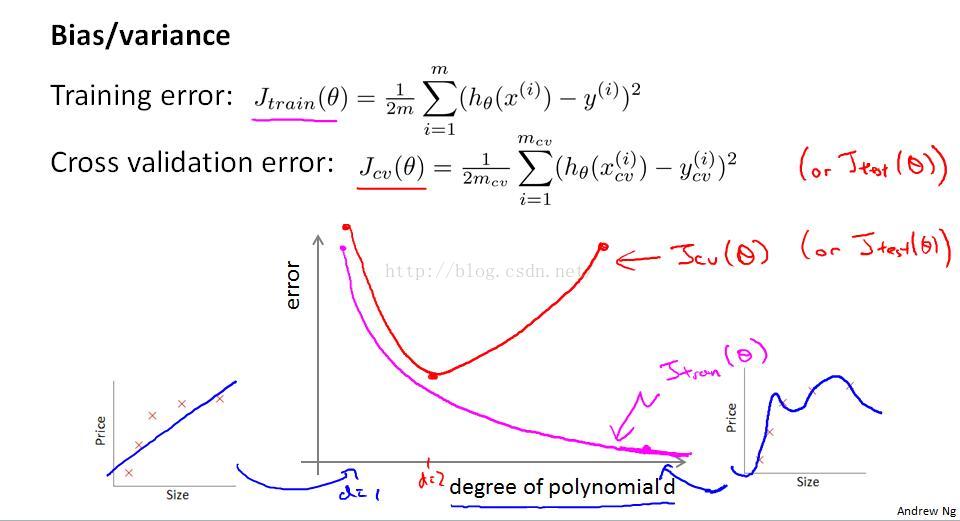
2.正则化参数λ
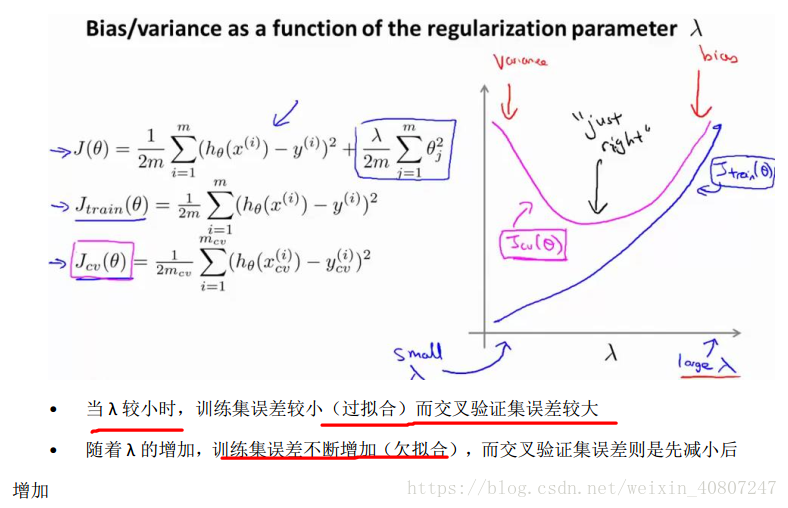
正则化参数我们在第三周有介绍到,正则化参数λ越大,对θ惩罚的越厉害,θ->0,假设函数是一条水平线,欠拟合、高偏差;正则化参数越小,相当于正则化的作用越弱,过拟合、高方差。关系如下图所示:

3.样本量m与学习曲线Learning curve
学习曲线是样本量与训练集、交叉验证集误差之间的关系,分为高偏差和高方差两种情况(欠拟合和过拟合)。
①高偏差(欠拟合):
根据下图右部分分析有,通过增加样本量两者误差都很大,即m的增加对于算法的改进无益。

②高方差(过拟合):
根据下图右部分分析有,通过增加样本量训练集样本拟合程度很好(过拟合),训练集误差很小,即m的增加对于算法的改进有一些帮助。

★★★(三)如何决策
综上所述,你会发现有这样的一个结论,就是:
◆训练集误差大、交叉验证集误差也大:欠拟合、高偏差、多项式次数d太小、λ太大;
◆训练集误差小、交叉验证集误差却很大:过拟合、高方差、多项式次数d太大、λ太下、样本量太少。
这就为我们改善机器学习算法提供了依据。




解决高偏差:
尝试获得更多的特征
尝试增加多项式特征
尝试减少归一化程度lamda




训练集误差小、交叉验证集误差却很大:过拟合、高方差、多项式次数d太大、λ太下、样本量太少。
这就为我们改善机器学习算法提供了依据。

训练集误差大、交叉验证集误差也大:欠拟合、高偏差、多项式次数d太小、λ太大;
这个时候有三种方法:
Try getting additional features 增加更多的特征向量
Try adding ploynomail features 增加多项式特征
Try decreasing lamda 减少归一化程度lamda


应该是通过训练集让我们的模型学习得出其参数后,然后对测试集运用该模型
假设你用线性回归来预测房价,你的数据集是按照增加房屋的大小来排序的。在将数据集分割成培训、验证和测试集之前,随机地将数据集打乱,这样我们就不会有所有最小的房子进入培训集,所有最大的房子都进入测试集。这是对的
假设您正在使用多项式特性训练一个逻辑回归分类器,并希望选择使用什么程度多项式(在课堂视频中表示dd)。在对整个培训集中培训分类器之后,您决定使用培训示例的子集作为验证集,这将与从培训集中分离(分离)的验证集一样有效。这不对 不能用自己的训练集来,而是应该

一个典型的数据集分割为训练、验证和测试集可能是60%的培训集,20%的验证集和20%的测试集。

