本实验依托于教材《模式分类》第二版第六章(公式符号与书中一致)
实验内容:
设计编写BP神经网络和RBF神经网络,对给定数据集进行分类测试,并将分类准确率与SVM进行对比。
实验环境:
matlab2016a
数据集:
数据集大小3*3000,表示3000个样本,每个样本包含2个特征,第三行表示样本所属的分类。对于此次实验编写的BP神经网络和RBF神经网络,均将原始数据集分为训练集和测试集两部分,训练集含2700个样本,测试集300样本,并且采用10-折交叉验证,将数据集分为10份,每次将其中一份作为测试,剩余作为训练,总共进行10次验证,得到10个准确率,将10个准确率求平均作为最终的衡量指标,与SVM分类效果进行对比。
本实验数据集下载:sample_ex6.mat
BP网络和RBF网络相似但有所不同,因此分开阐述,先来设计BP网络。
BP神经网络:
BP网络有三层,输入层,隐含层,输出层,输入层与隐含层之间有权值Wji,隐含层与输出层之间有权值Wkj(i,j,k分别代表各层的神经元数目)。根据给定数据规模,可设计输入层3个神经元(本来是2个神经元,加偏置后变为3),输出层1个神经元,隐含层的神经元个数待会讨论。
BP网络训练算法需要初始化以下参数:
(1)隐含层神经元个数
尽管输入和输出单元数分别由输入向量的维数和类别数目决定,但隐单元个数并不简单与此分类问题的外在特性相关。隐单元的个数决定了网络的表达能力,从而决定判决边界的复杂度。对于较多的隐单元数,训练误差可变得很小,这是因为网络具有较高的表达能力,但这种场合下对测试样本的误差率会很高,是一个“过拟合”的例子;相反隐单元数过少,网络没有足够的自由度来拟合训练集,同样导致测试误差高。一个简单的规则经验是选取隐单元的个数,使得网络的权值总数大致为n/10,n为总的样本数。当然,隐单元的个数需要根据实际效果来调节,这只是一个经验规则。对于本实验,选取初始隐单元数为62左右可使总的权值为n/10。
(2)激活函数
一般输入层到隐含层的激活函数需要非线性,饱和性和连续性,而隐含层到输出层的激活函数为线性即可。使用最多的激活函数是sigmoid函数,具有下列形式的激活函数可以很好的工作:

本次实验中,取a=1.716,b=2/3,从而保证线性范围为-1< net <+1。
(3)初始化权值
我们不能简单将权值初始化为0,否则学习过程将不可能开始。我们要设置初始权值以获得快速和均衡地学习,使所有权值同时达到最终的平衡值。为了使-1< net <+1,输入权值应该选取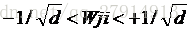
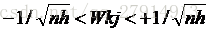
(4)学习率eta和阈值theta
学习率决定网络收敛的速度,可以先设为0.1,如果学习速度过慢,则将学习率调大,如果准则函数在学习过程中发散,则将学习率调小。阈值决定训练是否可以停止,设为0.01即可,根据实验效果再调节。
相关参数初始化后,可以开始训练,有三种训练方式:随机训练、成批训练和在线训练。本实验采用成批训练,更新权值前所有样本都提供一次,记为1个回合。
开始训练前,记得增广输入向量,给输入向量增加一维恒为1,作为偏置。数据训练前可以先规范化,都映射到-1和1之间,经过实际测试,对于本数据,是否规范化对最后的准确率影响不大,但没有规范化的数据收敛慢,运行时间长。
实验代码:
(1)函数 Batch_BP_neutral_network.m(建议使用matlab查看)
function correct_rate=Batch_BP_Neural_Network(train_data,test_data,hidden_layers,Wji,Wkj,theta,eta)
%-------------------------------------------------------------------
%Batch back-propagation neural network function which includes input layer(multiple layers with bias)、
%hidden layer(multiple layers) and output(one layer)
%Inputs:
%train_data -train data(including samples and its target output)
%test_data -test data(including samples and its target output)
%hidden_layers -numbers of hidden layers
%Wji -weights between input layer and hidden layer
%Wkj -weights between hidden layer and putput layer
%theta -threhold of target function
%eta -learnning rate
%Output:
%correct_rate: -classification correct rate of the test data
%-------------------------------------------------------------------
[rows,cols]=size(train_data);
train_input=train_data(1:rows-1,:);
train_target=train_data(rows,:);
test_input=test_data(1:rows-1,:);
test_target=test_data(rows,:);
%augmentation the train and test input
train_bias=ones(1,cols);
test_bias=ones(1,size(test_data,2));
train_input=[train_bias;train_input];
test_input=[test_bias;test_input];
%batch bp algorithm
r=0; %initialize the episode
J=zeros(1,1000); %initialize the error function
while(1) %outer loop
r=r+1;m=0;DELTA_Wji=zeros(hidden_layers,rows);DELTA_Wkj=zeros(1,hidden_layers); %initialization
while(1) %inner loop
m=m+1;
netj=zeros(1,hidden_layers);
yj=zeros(1,hidden_layers);
for j=1:hidden_layers
netj(1,j)=sum(train_input(:,m)'.*Wji(j,:)); %sum of product
yj(1,j)=3.432/(1+exp(-2*netj(1,j)/3))-1.716; %activation
end
netk=sum(yj(1,:).*Wkj(1,:)); %sum of product,output layer has only one neutron
zk=netk; %activation
J(1,r)=J(1,r)+(train_target(1,m)-zk)^2/2; %every sample has a error
for j=1:hidden_layers
delta_k=(train_target(1,m)-zk); %the sensitivity of output neutrons
DELTA_Wkj(1,j)=DELTA_Wkj(1,j)+eta*delta_k*yj(1,j); %update the DELTA_Wkj
end
delta_j=zeros(1,hidden_layers);
for j=1:hidden_layers
delta_j(1,j)=Wkj(1,j)*delta_k*(2.288*exp(-2*netj(1,j)/3)/(1+exp(-2*netj(1,j)/3)^2)); %the sensitivity of hidden neutrons
for i=1:rows
DELTA_Wji(j,i)=DELTA_Wji(j,i)+eta*delta_j(1,j)*train_input(i,m); %update the DELTA_Wji
end
end
if(m==cols) %all samples has been trained(one episode)
break; %back to outer loop
end
end %end inner loop
for j=1:hidden_layers
Wkj(1,j)=Wkj(1,j)+DELTA_Wkj(1,j); %update Wkj
end
for j=1:hidden_layers
for i=1:rows
Wji(j,i)=Wji(j,i)+DELTA_Wji(j,i); %update Wji
end
end
J(1,r)=J(1,r)/cols;
if((r>=2)&&abs(J(1,r)-J(1,r-1))<theta) %determine when to stop
%disp('ok!');disp(r);
%plot(0:r-1,J(1,1:r));hold on;
%start to test the model
correct=0;
for i=1:size(test_data,2)
test_netj=zeros(1,hidden_layers);
test_yj=zeros(1,hidden_layers);
for j=1:hidden_layers
test_netj(1,j)=sum(test_input(:,i)'.*Wji(j,:)); %sum of product
test_yj(1,j)=3.432/(1+exp(-2*test_netj(1,j)/3))-1.716; %activation
end
test_netk=sum(test_yj(1,:).*Wkj(1,:)); %sum of product,output layer has only one neutron
test_zk=test_netk; %activation
if((test_zk>0&&test_target(1,i)==1)||(test_zk<0&&test_target(1,i)==-1))
correct=correct+1;
end
end
correct_rate=correct/size(test_data,2);
break;
end
end(2)主函数
clear;
load sample_ex6.mat; %load data
[M,N]=size(data);
hidden_layers=10;
theta=0.001;
eta=0.00001;
wkj=-1/(hidden_layers^0.5)+2/(hidden_layers^0.5)*rand(1,hidden_layers);
wji=-1/(M^0.5)+2/(M^0.5)*rand(hidden_layers,M);
%input data normalization
[norm_data,norm_dataps]=mapminmax(data);
%10-fold crossing validation
sub_N=N/10;
rates=zeros(1,10);
for i=1:10
norm_testdata=data(:,1:sub_N); %set the first part as testdata
norm_traindata=data(:,sub_N+1:N); %set the next nine part as traindata
rates(1,i)=Batch_BP_Neural_Network(norm_traindata,norm_testdata,hidden_layers,wji,wkj,theta,eta);
data=[norm_traindata,norm_testdata];
end
disp('the accuracy of ten validation:')
disp(rates);disp('the average accuracy is:')
ave_rate=sum(rates)/10;
disp(ave_rate);实验结果:
训练完后,输入测试数据求出分类的准确率,由于采取的是10-fold交叉验证,需要训练10次,下图显示10次训练误差函数与回合的曲线:
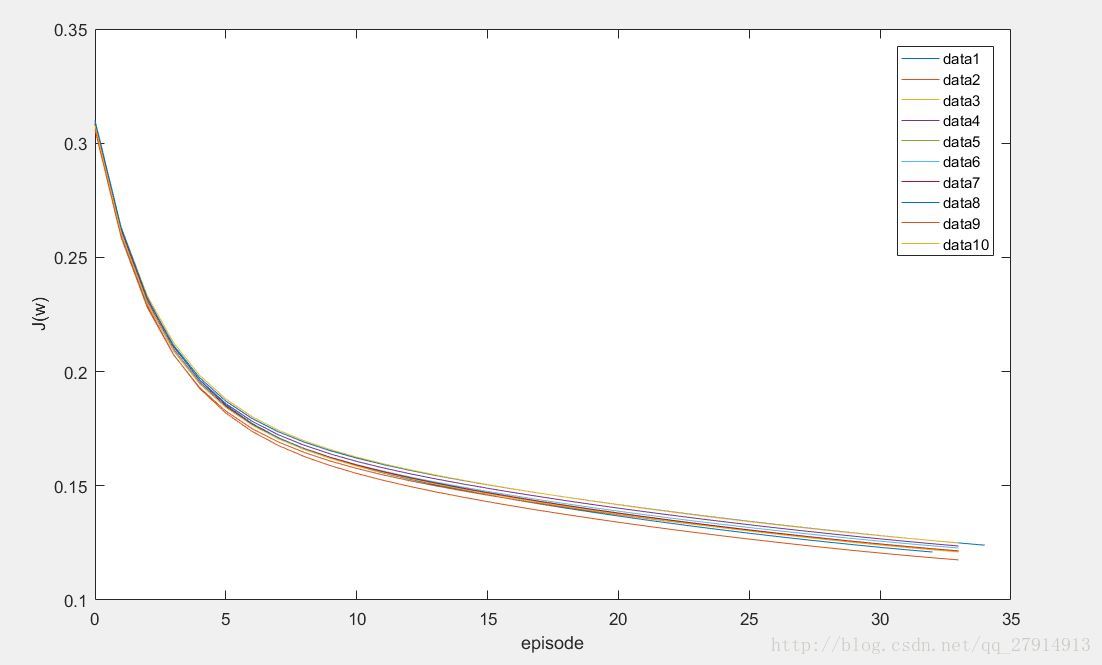
可以看出,随着训练的进行,误差函数一直减小,直到前后两次误差函数的差小于阈值停止训练。
每次测试的准确率以及最后的平均准确率如下图:


经过多次实验,平均准确率都在91%左右,不是很高,为什么说不是很高,看后面与SVM的对比就知道了。并且发现隐含层神经元个数取62或者10结果都差不多,准确率相差不大。但隐单元个数少运行时间短,10次交叉验证的总时间为:
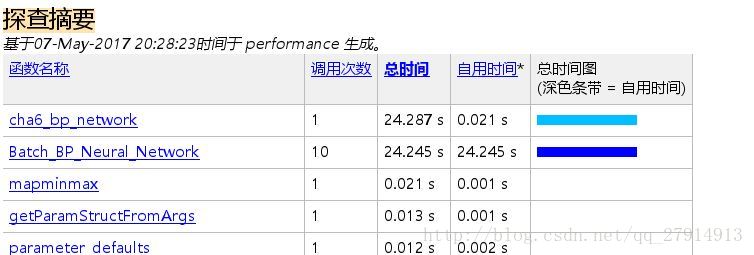
每次运行时间均有差异,十几秒到二十几秒之间。
这是BP网络设计部分,RBF网络设计以及与SVM的对比 将在下一篇博文:Matlab实现BP神经网络和RBF神经网络(二)中讨论。