在上一篇博文中:Matlab实现BP神经网络和RBF神经网络(一) 中,我们讨论了BP网络设计部分,下面我们将设计RBF网络并将它们结果与SVM对比。
数据格式不变,详情请看上一篇博文。
RBF神经网络:
RBF网络和BP网络都是非线性多层前向网络,它们都是通用逼近器。对于任一个BP神经网络,总存在一个RBF神经网络可以代替它,反之亦然。但是这两个网络也存在着很多不同点,他们在网络结构、训练算法、网络资源的利用及逼近性能方面均有差异。RBF网络输入层与隐含层直接连接,相当于直接将输入向量输入到隐含层,隐含层的激活函数有几种,最常用的是高斯函数:

σ称为径向基函数的扩展常数,它反应了函数图像的宽度,σ越小,宽度越窄,函数越具有选择性。RBF网络传递函数是以输入向量与中心向量之间的距离|| X-Cj ||作为自变量的,把高斯函数中的r替换为|| X-Cj ||即可。RBF网络需要确定的参数是数据中心C,扩展常数σ和隐含层到输出层的权值。从网上查阅资料说,RBF网络可以根据具体问题确定相应的网络拓扑结构,具有自学习、自组织、自适应功能,它对非线性连续函数具有一致逼近性,学习速度快,可以进行大范围的数据融合,可以并行高速地处理数据。RBF神经网络的优良特性使得其显示出比BP神经网络更强的生命力,正在越来越多的领域内替代BP神经网络。下图是一个输出神经元RBF网络的示意图:
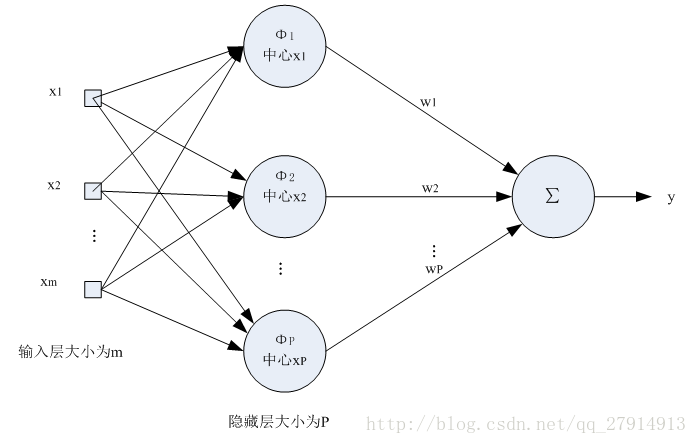
初始化参数:
同BP网络,RBF训练前同样需要初始化各类参数,RBF网络初始化参数有两种方法,一种是监督学习,一种是非监督学习。
(1)非监督方法:
数据中心的选取可以采用非监督的聚类算法,例如kmeans算法,直接求出k个数据中心不再变化,而扩展常数可根据各中心间距离来确定:
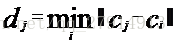
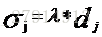
其中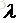
(2)监督方法:
最一般的情况,RBF函数中心、扩展常数、输出权值都应该采用监督学习算法进行训练,经历一个误差修正学习的过程,与BP网络的学习原理一样。同样采用梯度下降法,定义目标函数:
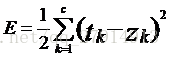
其中,c表示输出层神经元的个数,tk表示第k个输出神经元期望输出,zk表示实际输出。在本实验数据中,k取1。Zk由下式计算:
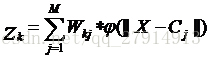
其中,M表示隐含层神经元的个数,Wkj表示隐含层到输出层的权值,X表示输入样本,Cj表示第j个隐含层神经元的数据中心。
分别计算目标函数E对权值Wkj、Cj和扩展常数σ的偏导,得到以下的更新公式:
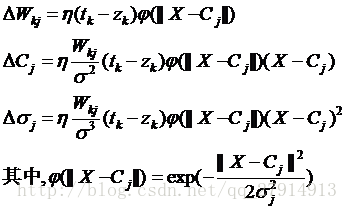
做好以上准备工作后,就可以开始实验了。本实验采用监督学习的方式来求取各参数,训练协议同样是成批训练,当然也可以随机训练,结果都差不多。算法开始前,需要初始化各参数。隐含层神经元初始化为10,对于Wkj,可以随机在范围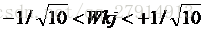
实验代码:
初始化工作后,编写代码测试。数据分成10份,每份300样本,同样采用10-fold交叉验证的方法,最后求准确率的平均值。
(1)函数 Batch_RBF_neutral_network.m
function correct_rate=Batch_RBF_Neural_Network(train_data,test_data,hidden_layers,Wkj,c,sigma,theta,eta)
%-------------------------------------------------------------------
%Batch RBF neural network function with only one output neutron
%Inputs:
%train_data -train data(including samples and its target output)
%test_data -test data(including samples and its target output)
%hidden_layers -numbers of hidden layers
%Wkj -weights between hidden layer and putput layer
%c -array of center points
%sigma -standard deviation of Gaussian function
%theta -threhold of delta target function
%eta -learnning rate
%Output:
%correct_rate: -classification correct rate of the test data
%-------------------------------------------------------------------
[rows,cols]=size(train_data);
train_input=train_data(1:rows-1,:);
train_target=train_data(rows,:);
test_input=test_data(1:rows-1,:);
test_target=test_data(rows,:);
%batch rbf algorithm
r=0; %initialize the episode
J=zeros(1,1000); %initialize the error function
while(1) %outer loop
r=r+1;m=0;DELTA_Wkj=zeros(1,hidden_layers);DELTA_c=zeros(hidden_layers,size(train_input,1));
DELTA_sigma=zeros(1,hidden_layers);%initialization
while(1) %inner loop
m=m+1;
yj=zeros(1,hidden_layers);
for j=1:hidden_layers
%calculate the output of the hidden layer
yj(1,j)=exp(-sum((train_input(:,m)'-c(j,:)).*(train_input(:,m)'-c(j,:)))/(2*sigma(1,j)^2));
end
zk=sum(yj(1,:).*Wkj(1,:)); %output of the output layer
error=train_target(1,m)-zk;
J(1,r)=J(1,r)+error^2/2; %accumulate every error
for j=1:hidden_layers
%update the DELTA_Wkj,DELTA_c and DELTA_sigma
DELTA_Wkj(1,j)=DELTA_Wkj(1,j)+eta*error*yj(1,j);
DELTA_c(j,:)=DELTA_c(j,:)+eta*error*Wkj(1,j)*yj(1,j)*(train_input(:,m)'-c(j,:))/sigma(1,j)^2;
DELTA_sigma(1,j)=DELTA_sigma(1,j)+eta*error*Wkj(1,j)*yj(1,j)* ...
sum((train_input(:,m)'-c(j,:)).*(train_input(:,m)'-c(j,:)))/sigma(1,j)^3;
end
if(m==cols) %all samples has been trained(one episode)
break; %back to outer loop
end
end %end inner loop
for j=1:hidden_layers
Wkj(1,j)=Wkj(1,j)+DELTA_Wkj(1,j); %update Wkj
c(j,:)=c(j,:)+DELTA_c(j,:); %update c
sigma(1,j)=sigma(1,j)+DELTA_sigma(1,j); %update sigma
end
J(1,r)=J(1,r)/cols;
if((r>=2)&&abs(J(1,r)-J(1,r-1))<theta) %determine when to stop
%disp('ok!');disp(r);
%plot(0:r-1,J(1,1:r));hold on;
%start to test the model
correct=0;
for i=1:size(test_input,2)
test_yj=zeros(1,hidden_layers);
for j=1:hidden_layers
test_yj(1,j)=exp(-sum((test_input(:,i)'-c(j,:)).*(test_input(:,i)'-c(j,:)))/(2*sigma(1,j)^2));
end
test_zk=sum(test_yj(1,:).*Wkj(1,:));
if((test_zk>0&&test_target(1,i)==1)||(test_zk<0&&test_target(1,i)==-1))
correct=correct+1;
end
end
correct_rate=correct/size(test_data,2);
break;
end
end(2)主函数:
clear;
load sample_ex6.mat;
[M,N]=size(data);
hidden_layers=10;
theta=0.01;
eta=0.01;
wkj=-1/(hidden_layers^0.5)+2/(hidden_layers^0.5)*rand(1,hidden_layers);
sigma=zeros(1,hidden_layers);
for i=1:hidden_layers
sigma(1,i)=2+2*rand(); %initialize sigma to 2.0-4.0
end
%input data normalization
% [norm_data,norm_dataps]=mapminmax(data);
%10-fold crossing validation
sub_N=N/10;
rates=zeros(1,10);
for i=1:10
testdata=data(:,1:sub_N); %set the first part as testdata
traindata=data(:,sub_N+1:N); %set the next nine part as traindata
center_points=zeros(hidden_layers,M-1);
for j=1:10
%random initialize center points in train data
center_points(j,:)=traindata(1:2,ceil(rand()*size(traindata,2)))';
end
rates(1,i)=Batch_RBF_Neural_Network(traindata,testdata,hidden_layers,wkj,center_points,sigma,theta,eta);
data=[traindata,testdata];
end
disp('the accuracy of ten validation:')
disp(rates);disp('the average accuracy is:')
ave_rate=sum(rates)/10;
disp(ave_rate);实验结果:
几次实验结果如下:



由以上结果可以看到,RBF神经网络能得到较高的分类准确率,在96%左右波动,并且观察10次的准确率,发现有的准确率能到100%,而有的还不到90%,浮动较大,但平均能到96%。
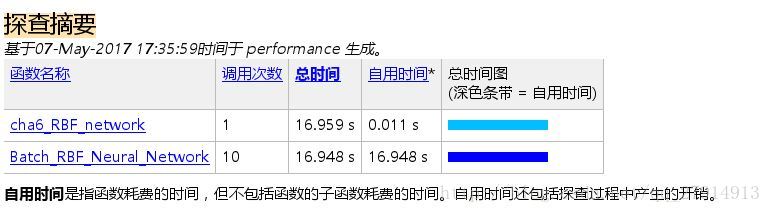
10次验证总的运行时间比BP网络短:
讨论完BP神经网络和RBF神经网络,他们的分类准确率到底如何,接下来我们用SVM来对比一下。
可以在matlab安装LIBSVM,也可以使用matlab自带的分类学习工具箱(Classification Learner),为了方便,直接使用matlab工具箱中的SVM。
Classification Learner的使用方法参考博文:Matlab自带的分类学习工具箱
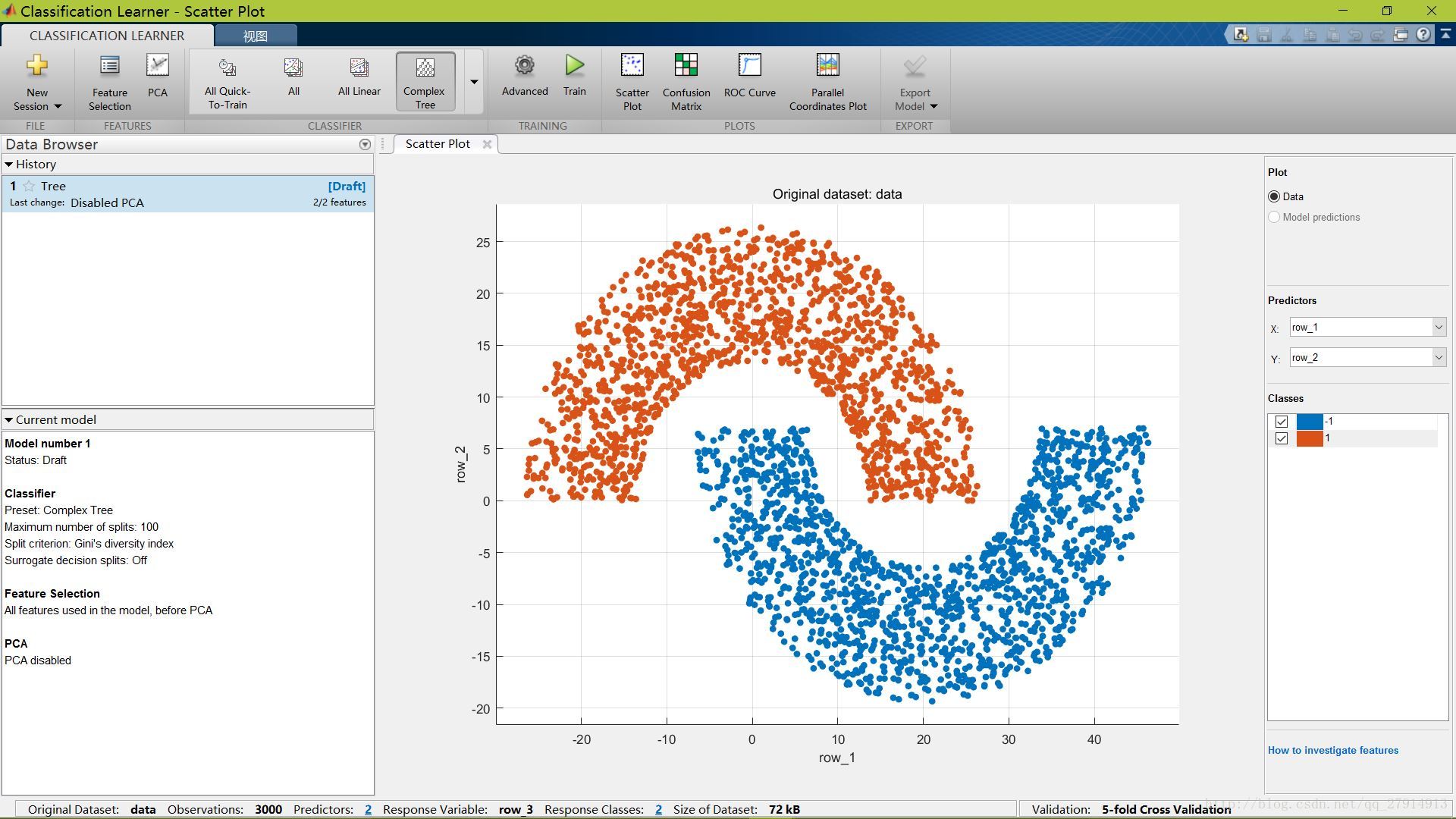
进入Classification Learner,显示原始数据:
点击classifier中的下拉箭头,选择svm分类器,点击train,开始训练,结果如下:
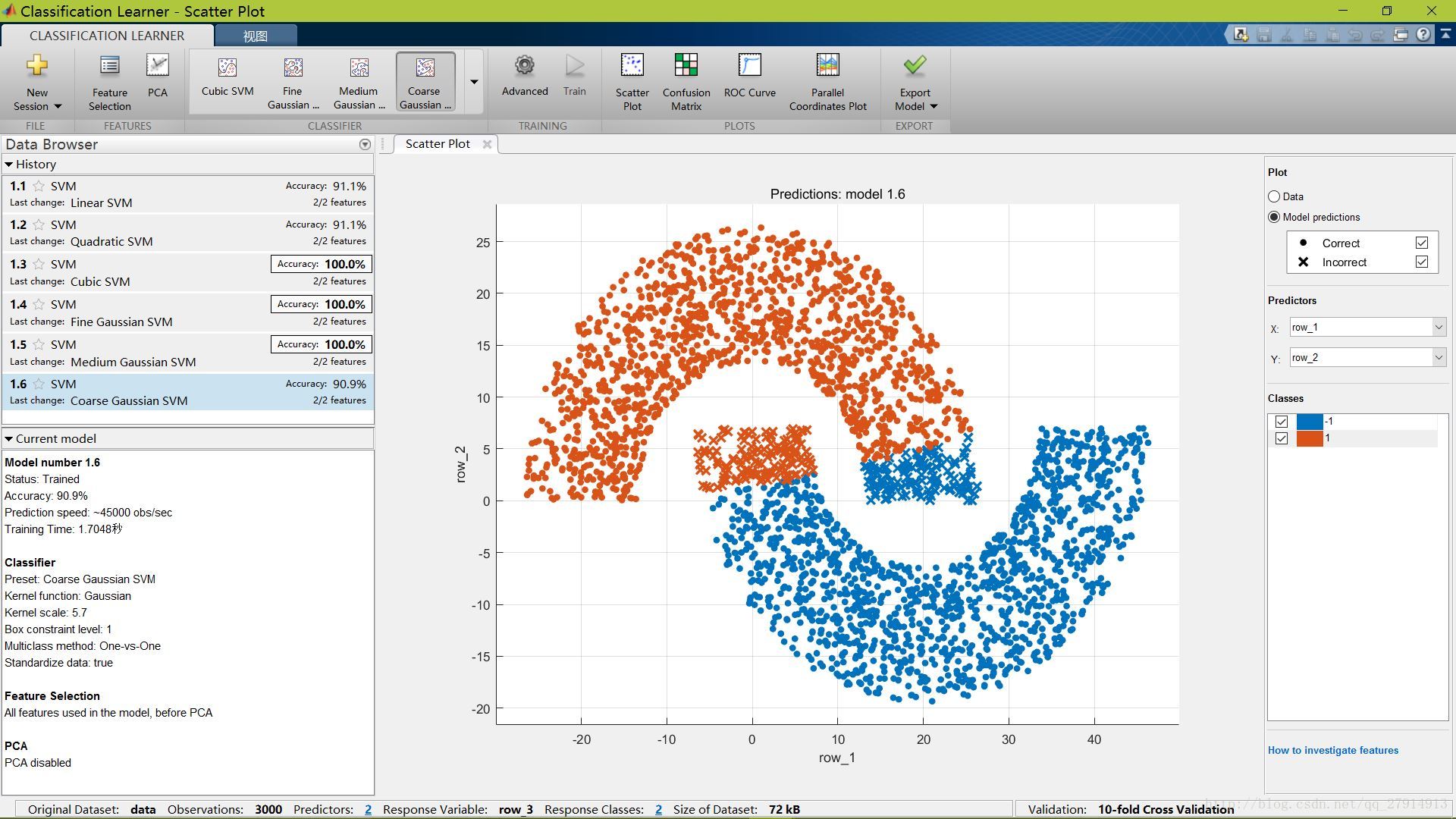
图中显示了6个SVM分类器的分类结果,准确率最低为Coarse Gaussian SVM的90.9%,而Cubic Gaussian SVM、Fine Gaussian SVM和Medium Gaussian SVM的准确率均为100%,能将测试样本完全分开。并且,Linear SVM的准确率达到91.1%,也就是说画条线作为分界的准确率都跟BP网络差不多,所以说本次实验得到的BP网络的准确率并不高。
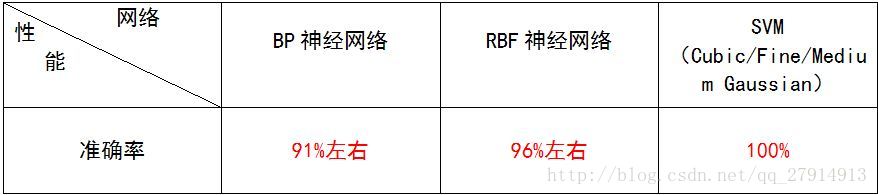
下表列出了本实验三种模型准确率:
总结:
神经网络的训练前,需要初始化各类参数,这些参数的初始值对网络的性能、收敛速度等都有影响,初始化应该有明确的方向而不是盲目初始化。当然,最佳的参数值需要根据实验结果进行调整。
BP神经网络和RBF网络都能用来训练分类数据,但它们的网络结构、训练算法、网络资源的利用及逼近性能等方面均有差异,RBF神经网络可以根据具体问题确定相应的网络拓扑结构,具有自学习、自组织、自适应功能,它对非线性连续函数具有一致逼近性,学习速度快,比BP网络有更强的生命力。
SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远。在本实验中,使用高斯函数为核函数的SVM取得的效果最好。