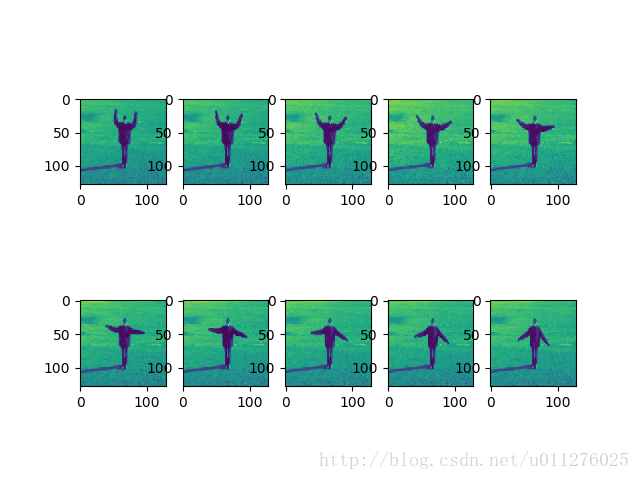目录连接
(1) 数据处理
(2) 搭建和自定义网络
(3) 使用训练好的模型测试自己图片
(4) 视频数据的处理
(5) PyTorch源码修改之增加ConvLSTM层
(6) 梯度反向传递(BackPropogate)的理解
(总) PyTorch遇到令人迷人的BUG
PyTorch的学习和使用(四)
最近在跑一个视频处理的代码,其用tensorFlow实现的,现在转换为使用PyTorch处理,主要实现如下:
- 对原始视频的读取,得到连续的K帧存储
- 对每帧图片数据的处理(翻转,归一化)
- 对数据的mini-batch处理
和之前博客 PyTorch(一)——数据处理,中所说的一样,需要:
1)定义数据读取的方法。
2)针对数据的格式,改写transforms中数据处理的方法。
3)由于torch.utils.data.DataLoader()是对单张图片进行批次处理,对于连续多帧图片不好处理(也许可以使用图片的通道存储视频的帧数),因此在读取数据是进行mini-batch批次处理。
实现的主要想法为:首先把所有的视频数据的文件名称读入,使用shuffle打乱后进行mini-batch分组,然后根据分组的名称读取每组的视频,最后把读取批次的视频进行处理。
视频的读取
定义一个文件完成视频的读取、批次处理,并且调用定义的transforms方法对图片进行处理,返回处理为PyTorch使用的数据块。
使用imageio和opencv完成视频的读取
其代码主要为下:
def load_kth_data(f_name, data_path, image_size, L):
"""
:param f_name: video name
:param data_path: data path
:param image_size: image size
:param L: extract L frame of video
:return: sequence frame of K+T len
"""
tokens = f_name.split()
vid_path = os.path.join(data_path, tokens[0] + "_uncomp.avi")
vid = imageio.get_reader(vid_path, "ffmpeg") # load video
low = int(tokens[1]) # start of video
# make sure the len of video is than L
high = np.min([int(tokens[2]), vid.get_length()]) - L + 1
# the len of video is equal L
if (low == high):
stidx = 0
else:
# the len of video is less-than L, print video path and the error for next line
if (low >= high): print(vid_path)
# the len of video greater than L, and the start is random of low-high
stidx = np.random.randint(low=low, high=high)
# extract video of L len
seq = np.zeros((image_size, image_size, L, 1), dtype="float32")
for t in xrange(L):
img = cv2.cvtColor(cv2.resize(vid.get_data(stidx + t), (image_size, image_size)),
cv2.COLOR_RGB2GRAY)
seq[:, :, t] = img[:, :, None]
return seq(这注释写的估计我自己都不认识^_^!)
输入文件名、文件路径、没帧图片大小和帧长度(L),返回L帧图片的数组。
使用shuffle和视频文件名完成视频的批次处理
根据视频数据的数量,对其索引进行shuffle,然后根据索引对应的文件,完成视频数据的读取,其主要代码如下:
def get_minibatches_idx(n, minibatch_size, shuffle=False):
"""
:param n: len of data
:param minibatch_size: minibatch size of data
:param shuffle: shuffle the data
:return: len of minibatches and minibatches
"""
idx_list = np.arange(n, dtype="int32")
# shuffle
if shuffle:
random.shuffle(idx_list)
# segment
minibatches = []
minibatch_start = 0
for i in range(n // minibatch_size):
minibatches.append(idx_list[minibatch_start:
minibatch_start + minibatch_size])
minibatch_start += minibatch_size
# processing the last batch
if (minibatch_start != n):
minibatches.append(idx_list[minibatch_start:])
return zip(range(len(minibatches)), minibatches)输入视频数量的大小、mini-batch的尺寸和是否重新排列(shuffle),返回视频每个batch的序号和索引。
迭代器中实现视频数据读取和处理
PyTorch通过迭代器返回每次需要处理的批次,放入网络中进行训练。因此在数据处理的迭代返回方法中完成:
- 根据mini-batch索引对视频数据读取
- 调用transforms中的方法实现数据的处理(归一化、tensor转化等)
主要代码如下:
def __getitem__(self, index):
# read video data of mini-batch with parallel method
Ls = np.repeat(np.array([self.T + self.K]), self.batch_size, axis=0) # video length of past and feature
paths = np.repeat(self.root, self.batch_size, axis=0)
files = np.array(self.trainFiles)[self.mini_batches[index][1]]
shapes = np.repeat(np.array([self.image_size]), self.batch_size, axis=0)
with joblib.Parallel(n_jobs=self.batch_size) as parallel:
output = parallel(joblib.delayed(load_kth_data)(f, p, img_size, l)
for f, p, img_size, l in zip(files,
paths,
shapes,
Ls))
# save batch data
seq_batch = np.zeros((self.batch_size, self.image_size, self.image_size,
self.K + self.T, 1), dtype="float32")
for i in xrange(self.batch_size):
seq_batch[i] = output[i]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
if self.transform is not None:
seq_batch = self.transform(seq_batch)
return seq_batch其中使用了joblib.Parallel 多线程处理,具有较快的速度。
数据处理transforms中方法的实现
主要实现了:
- tensor的转换
- Normalize归一化处理
- RandomHorizontalFlip水平翻转
实现较为简单,代码如下:
class ToTensor(object):
"""
Converts numpy.ndarray (N x H x W x C x 1) in the range
[0, 255] to a torch.FloatTensor of shape (N x H x W x C x 1).
"""
def __call__(self, pic):
# handle numpy array
img = torch.from_numpy(pic)
# backard compability
return img
class Normalize(object):
"""
will normalize each channel of the torch.*Tensor, i.e.
channel = channel/127.5 - 1
"""
def __call__(self, tensor):
# TODO: make efficient
for t in tensor:
t.div_(127.5).sub_(1)
return tensor
class RandomHorizontalFlip(object):
"""
Randomly horizontally flips the given numpy.ndarray
(N x H x W x C x 1) with a probability of 0.5
"""
def __call__(self, img):
for n in xrange(img.shape[0]):
if random.random() < 0.5:
img[n] = img[n,:,::-1]
return img输出结果
最后对处理后的视频图片可视化,得到如下结果: